JAVA数据结构之哈希表
Hash表简介:
Hash表是基于数组的,优点是提供快速的插入和查找的操作,编程实现相对容易,缺点是一旦创建就不好扩展,当hash表被基本填满的时候,性能下降非常严重(发生聚集引起的性能的下降),而且没有简便方法以任何一种顺序来遍历表中的数据项,若需要,则要考虑其他的数据结构(选择hash表存储数据一般是不需要有序遍历数据,可以提前预测数据量的大小)
Hash化:在hash表中我们一般通过hash函数将数据的关键字转换成为数组的下标(若关键字可以直接作为数组的下标则不需要hash函数转换)。现在我们假设要在内存中存储50000个单词,此时关键字单词不能直接作为我们的数组的下标,所以我们就需要将其用我们的hash函数转换一下得到我们的数组的下标,这里我们用1-26代表我们真的字母a-z空格我们用0代表,接下来我们要探讨如何将代表单个字母的数字组合成代表整个单词的数字呢,有两种具有代表性的方法,假设我们约定单词由十个字母组成,
第一种是把每个字母对应的数字相加得到数组的下标:
空位是0那么第一个单词a就是0+0+0+0+0+0+0+0+0+1 = 1,最后一个单词是zzzzzzzzzz对应的数组下标是26+26+26+26+26+26+26+26+26+26 = 260,这里我们可以明显地看到,我们的存储数组的大小是260,明显不够我们存储50000个单词,所以这里的每一个数组项都要包含一个数组或链表,这样就严重降低了存取的速度。
第二种是使用幂的连乘:
我们将每个字母对应的数字乘以适当的27的幂(由于包括空格有27个字符),在字母的第一位乘以0次幂第二位乘以1次幂以此类推,然后将每一个结果相加得到我们最终的数组的下标,例如我们将cats依此转换3*273+1*272+20*271+19*270 =60337这样可以为每一个单词创建独一无二的整数但是此时的问题是单词zzzzzzzzzz计算出来的数值变得非常大279=7000000000000结果非常巨大其中大多数结果都是空的
对于英语词典我们存储50000个单词大约需要多余一倍的空间来容纳这些单词(由于当hash填满的时候对其性能影响很大),所以需要容量100000的数组,我们需要将0到超过7000000000000的范围,压缩为0-100000的范围,使用上面通过计算得到的数字(这个数字可能超出变量范围)来对我们的压缩范围取余可以得到我们最终压缩后的数字,将这样巨大的数字空间压缩成较小的数字空间,由于不能保证每个单词都映射到数组的空白单元,这时候就会发生冲突,解决这样冲突我们一般使用开放地址法和链地址法。
开放地址法:通过系统的方法找到系统的空位(三种:线性探测、二次探测、再哈希法),并将插入的单词填入,而不再使用用hash函数得到数字作为数组的下标。
- 线性探测:假若当前要插入的位置已经被占用了之后,沿数组下标递增方向查找,直到找到空位为止
- 二次探测:二次探测和线性探测的区别在于二次探测的步长是,若计算的原始下标是x则二次探测的过程是x+12,x+22,x+32,x+42,x+52随着探测次数的增加,探测的步长是探测次数的二次方(因此名为二次探测)。二次探测会产生二次聚集:即当插入的几个数经过hash后的下标相同的话,那么这一串数字插入的探测步长会增加很快
- 再hash法:为了消除原始聚集和二次聚集,把关键字用不同的hash函数再做一遍hash化,用过这个结果作为探测的步长,这样对于特定的关键字在整个探测中步长不变,但是不同的关键字会使用不同的步长。stepSize = constant - (key % constant) 这个hash函数求步长比较实用,constant是小于数组容量的质数。(注意:第二个hash函数必须和第一个hash函数不同,步长hash函数输出的结果值不能为0)
下面给出再hash的JAVA代码
class DataItem {
private int iData;
public DataItem(int iData) {
this.iData = iData;
}
public int getKey() {
return iData;
}
}
/***再hash法的java代码*/
class HashTableDouble {
private DataItem[] hashArray;
private int arraySize;
//用来标记删除数据项
private DataItem nonItem;
HashTableDouble(int size) {
arraySize = size;
hashArray = new DataItem[size];
nonItem = new DataItem(-1);
}
//此函数用来得到关键字插入的脚标
public int hashFunc1(int key) {
return key % arraySize;
}
//此函数用来得到探测的步长
public int hashFunc2(int key) {
return 5 - key % 5;
}
/***再hash法插入数据*/
public void insert(int key) {
int hashVal = hashFunc1(key);
int stepSize = hashFunc2(key);
while (hashArray[hashVal] != null && hashArray[hashVal].getKey() != -1) {
//将hash值依次加上步长
hashVal += stepSize;
//当hash值超出范围了之后压缩到指定范围,相当于是循环寻找数据项
hashVal %= stepSize;
}
hashArray[hashVal] = new DataItem(key);
}
/***删除*/
public void delete(int key) {
int hashVal = hashFunc1(key);
int stepSize = hashFunc2(key);
while(hashArray[hashVal] != null){
if (hashArray[hashVal].getKey() == key){
hashArray[hashVal] = nonItem;
return;
}
hashVal += stepSize;
hashVal %= stepSize;
}
}
/***查找对应的关键字*/
public DataItem find(int key) {
int hashVal = hashFunc1(key);
int stepSize = hashFunc2(key);
while(hashArray[hashVal] != null){
if (hashArray[hashVal].getKey() == key){
return hashArray[hashVal];
}
hashVal += stepSize;
hashVal %= stepSize;
}
return null;
}
}
再哈希法JAVA代码
链地址法 :创建一个存放单词链表的数组,数组内不直接存储单词,而是存储单词的链表或数组。发生冲突的时候,数据项直接接到这个数组下标所指的链表中即可。
优势:填入过程允许重复,所有关键值相同的项放在同一链表中,找到所有项就需要查找整个是链表,稍微有点影响性能。删除只需要找到正确的链表,从链表中删除对应的数据即可。表容量是质数的要求不像在二次探测和再hash法中那么重要,由于没有探测的操作,所以无需担心容量被步长整除,从而陷入无限循环中。接下来给出链地址法的JAVA代码:
/**
* Link 是链节点类
* SortedList 是链表类
* HashTable 是Hash表类
*/
class Link {
private int iData;
public Link next;
public Link(int iData) {
this.iData = iData;
}
public int getKey() {
return iData;
} } /**
* 这里创建的是一个有序的链表,可减少不成功搜索一半的时间,删除的时间级也减少一半
* 插入的时间变长了,由于需要找到正确的插入位置
*/
class SortedList { private Link first;
public SortedList() {
first = null;
} //插入
public void insert(Link theLink) {
int key = theLink.getKey();
Link previous = null;
Link current = first;
//这里循环找到链节点插入的位置
while (current != null && key > current.getKey()) {
previous = current;
current = current.next;
}
//插入新的链节点
if (previous == null) {
first = theLink;
} else {
previous.next = theLink;
theLink.next = current;
}
} //delete删除
public void delete(int key) {
Link previous = null;
Link current = first;
//找到需要删除的链节点的位置
while (current != null && key != current.getKey()) {
previous = current;
current = current.next;
}
//删除链节点
if (previous == null) {
first = first.next;
} else {
previous.next = current.next;
}
} //find查找
public Link find(int key) {
Link current = first;
while (current != null && current.getKey() <= key){
if (current.getKey() == key)
return current;
current = current.next;
}
return null;
}
} class HashTable {
private SortedList[] hashArray;
private int arraySize;
public HashTable(int arraySize) { //构造函数
this.arraySize = arraySize;
hashArray = new SortedList[arraySize];
for (int j = 0; j<arraySize;j++){
hashArray[j] = new SortedList();
}
}
/***将关键字hash化*/
public int hashFunc(int key) {
return key % arraySize;
}
public void insert(Link theLink) {
int key = theLink.getKey();
//获取关键字的hash值
int hashVal = hashFunc(key);
hashArray[hashVal].insert(theLink);
}
public void delete(int key) { //删除
int hashVal = hashFunc(key);
hashArray[hashVal].delete(key);
}
public Link find(int key) { //查找
int hashVal = hashFunc(key);
return hashArray[hashVal].find(key);
}
}
链地址法的JAVA代码
ps:桶:类似于链地址法,只是将链表换为数组这样的数组有时称为桶,但是桶的容量不好选择。
Hash化的效率:
下图显示了不同的hash方法的效率情况
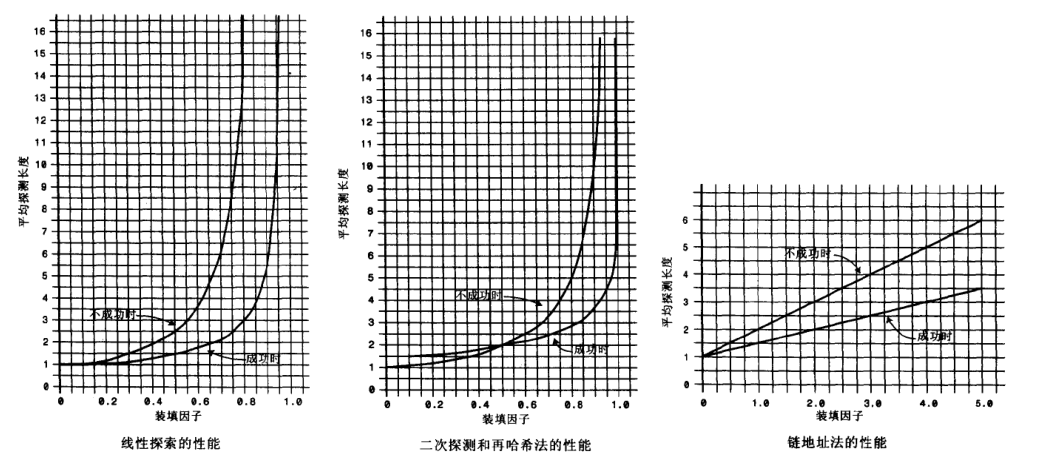
从上图我们可以看到开放地址法随着装填因子变大,比较次数后期会急剧变大,所以使用开放地址法的时候尽量保持装填因子不能超过2/3,二次探测和再hash法的性能相当,他们都要比线性探测要好。当装填因子为0.5的时候成功和不成功的查找需要平均2次比较,当装填因子为0.8的时候分别需要2.9和5.0次查找,所以对于较高的装填因子,可以选择二次探测和再hash法。链地址法的效率,所有的操作都需要1+nComps的时间,nComps表示关键字的比较次数,和装填因子有关,装填因子的大小影响每一个链表的平均长度,从而会影响每个关键字在链表中的比较次数,从而影响效率。
如果在hash表创建的时候,填入的项数未知,链地址法好于开放地址法,当装填因子变大的时候开放地址法的效率下降很快,而链地址法效率是线性地下降。两种都可选的时候也推荐选择链地址法,虽然要使用到链表类,但是当要增加比预期更多的数据的时候性能不会快速的下降
以上就是hash表数据结构的所有内容
JAVA数据结构之哈希表的更多相关文章
- 数据结构 5 哈希表/HashMap 、自动扩容、多线程会出现的问题
上一节,我们已经介绍了最重要的B树以及B+树,使用的情况以及区别的内容.当然,本节课,我们将学习重要的一个数据结构.哈希表 哈希表 哈希也常被称作是散列表,为什么要这么称呼呢,散列.散列.其元素分布较 ...
- 数据结构是哈希表(hashTable)
哈希表也称为散列表,是根据关键字值(key value)而直接进行访问的数据结构.也就是说,它通过把关键字值映射到一个位置来访问记录,以加快查找的速度.这个映射函数称为哈希函数(也称为散列函数),映射 ...
- python数据结构之哈希表
哈希表(Hash table) 众所周知,HashMap是一个用于存储Key-Value键值对的集合,每一个键值对也叫做Entry.这些个键值对(Entry)分散存储在一个数组当中,这个数组就是Has ...
- 算法与数据结构基础 - 哈希表(Hash Table)
Hash Table基础 哈希表(Hash Table)是常用的数据结构,其运用哈希函数(hash function)实现映射,内部使用开放定址.拉链法等方式解决哈希冲突,使得读写时间复杂度平均为O( ...
- 数据结构HashMap哈希表原理分析
先看看定义:“散列表(Hash table,也叫哈希表),是根据关键码值(Key value)而直接进行访问的数据结构.也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度. 哈希 ...
- java实现自定义哈希表
哈希表实现原理 哈希表底层是使用数组实现的,因为数组使用下标查找元素很快.所以实现哈希表的关键就是把某种数据类型通过计算变成数组的下标(这个计算就是hashCode()函数 比如,你怎么把一个字符串转 ...
- 数据结构,哈希表hash设计实验
数据结构实验,hash表 采用链地址法处理hash冲突 代码全部自己写,转载请留本文连接, 附上代码 #include<stdlib.h> #include<stdio.h> ...
- js:数据结构笔记7--哈希表
哈希表(散列表):通过哈希函数将键值映射为一个字典; 哈希函数:依赖键值的数据类型来构建一个哈希函数: 一个基本的哈希表:(按字符串计算键值) function HashTable() { this. ...
- C++数据结构之哈希表
哈希表的定义:哈希表是一种根据关键码去寻找值的数据映射结构,该结构通过把关键码映射的位置去寻找存放值的地方.键可以对应多个值(即哈希冲突),值根据相应的hash公式存入对应的键中. 哈希函数的构造要求 ...
随机推荐
- 使用SpringMVC<mvc:view-controller/>标签时踩的一个坑
<mvc:view-controller>标签 如果我们有些请求只是想跳转页面,不需要来后台处理什么逻辑,我们无法在Action中写一个空方法来跳转,直接在中配置一个如下的视图跳转控制器即 ...
- Redis数据结构之压缩列表-ziplist
为了节约内存,在zset和hash容器对象元素个数较少时,Redis会采用压缩列表(ziplist)进行存储. 压缩列表是一块连续的内存空间,元素之间紧挨着存储,不存在冗余 一个压缩列表可以包含任意多 ...
- Avito Cool Challenge 2018 B - Farewell Party
题目大意: 有n个人 接下来一行n个数a[i] 表示第i个人描述其他人有a[i]个的帽子跟他不一样 帽子编号为1~n 如果所有的描述都是正确的 输出possible 再输出一行b[i] 表示第i个人的 ...
- C#跨线程访问(二)----thread参数、回调传参数
一.单个参数(封箱也可实现多参数) class B { public static void Main() { Thread t = new Thread(ne ...
- thrift 的一些相关知识
thrift是一个很好用的跨语言的rpc框架. 但是其也有一些需要注意的问题: 第一: 发现其对于类型检查没有那么严格: 最近工作中发现是可以把一个int类型直接付给string,而没有任何wa ...
- 解决vi显示文件不能全屏的问题
https://blog.csdn.net/ly890700/article/details/52735092 docker外: vi ~/.vimrc
- 发现一个新的远程软件 gotohttp
之前直到远程桌面连接是TeamViewer 替换的原因是: 被控制端版本 11.0.x (很久以前安装的),而我本地的Teamviewer是 14.x, 去连接,好像提示被控制端的版本太低:本地使用 ...
- table 表头不动,tbody滚动对齐
http://www.imaputz.com/cssStuff/bigFourVersion.html# https://blog.csdn.net/yiifaa/article/details/52 ...
- 8-26接口压力测试-3Jmeter-Java请求
1.新建maven工程 2.导入依赖,并使用shade将所需的依赖打入jar包 <?xml version="1.0" encoding="UTF-8"? ...
- 【原理】LVM(Logical Volume Manager)动态卷管理
一张图让你学会LVM 导读 随着科技的进步,人们不知不觉的就进入了大数据的时代,数据的不断增加我们发现我们的磁盘越来越不够用了,接下来就是令人头疼的事情--加硬盘,数据的备份与还原.LVM就是Li ...