概率检索模型:BIM+BM25+BM25F
1. 概率排序原理
以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分为两类 -- 相关文档、不相关文档,这样就转为了一个相关性的分类问题。
对于某个文档D来说,P(R|D)表示该文档数据相关文档的概率,则P(NR|D)表示该文档属于不相关文档的概率,如果query属于相关文档的概率大于不相关文档P(R|D)>P(NR|D),则认为这个文档是与用户查询相关相关的。
现在使用贝叶斯公式将其转一下:
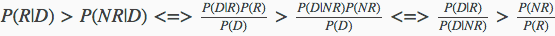
在搜索排序过程中不需要真正的分类,只需要保证相关性由高到底排序即可,所以只需要P(D|R) / P(D|NR)降序即可,
这样就最终转为计算P(D|R),P(D|NR)的值即可。
2. 二元独立模型(BIM)
为了能够使得上述两个计算因子可行,二元独立模型做出了两个假设:
1. 二元假设
类似于布尔模型中的文档表示方法,一篇文档在由特征(或者单词)进行表示的时候,以特征(或者单词)出现和不出现两种情况来表示,不考虑词频等其他因素。
2. 词汇独立性假设
指文档里出现的单词之间没有任何关联,任意一个单词在文档的分布概率不依赖于其他单词是否出现。因为词汇之间没有关联,所以可以将文档概率转换为单词概率的乘积。
上述提到的文档D表示为{1,0,1,0,1},用pi来表示第i个单词在相关文档出现的概率,则在已知相关文档集合的情况下,观察到D的概率为:
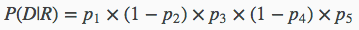
第1,3,5表示这个单词在D中出现,所以其贡献概率为pi,而第2,4这两个单词并没有在D中出现,所以其贡献的概率为1−pi。
同理在不相关文档中观察到的概率为:
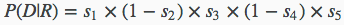
最终得到的相关性概率估算为:
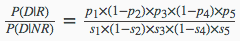
现在将其推广之后可以有通用的式子:
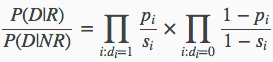
di=1表示在文档中出现的单词,di=0表示没在文档中出现的单词。
在这里进一步对上述公式进行等价变换之后有:
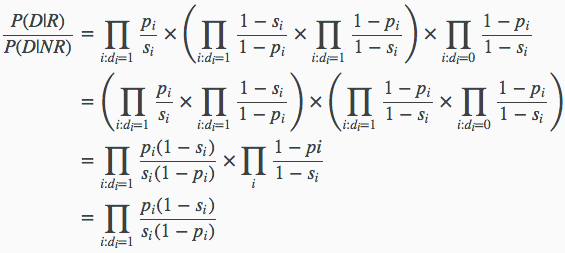
其中上面式子第三步的第二部分 表示各个单词在所有文档中出现的概率,所以这个式子的值和具体文档并没有什么关系,在排序中不起作用,才可以简化到第4步。
表示各个单词在所有文档中出现的概率,所以这个式子的值和具体文档并没有什么关系,在排序中不起作用,才可以简化到第4步。
为了方便计算,将上述连乘公式取log:
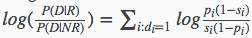
有了上述最终可计算的式子之后,我们就只需要统计文档D中的各个单词在相关文档/不相关文档中出现的概率即可:

上面的表格表示各个单词在文档集合中的相关文档/不相关文档出现数量,同时为了避免log(0)出现,加上平滑之后可以计算得到:

则最终可以得到如下公式:
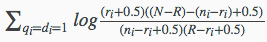
其代表的含义是:对于同时出现在用户查询Q和文档D中的单词,累加每个单词的估值,其和就是文档D和查询的相关性度量。
在不确定哪些文档是相关的,哪些文档是不相关的的时候,可以给公式的估算因子直接赋予固定值,则该公式将会退化为IDF因子。
3. BM25模型
BIM模型基于二元独立假设推导而出,即对于单词特征,只考虑是否在文档中出现过,而不考虑单词的权值。BM25模型在BIM模型的基础上,考虑了单词在查询中的权值及单词在文档中的权值,拟合出综合上述考虑因素的公式,并通过实验引入一些经验参数。
BM25模型的具体计算公式如下所示:
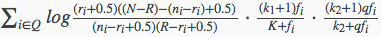
上面的式子中:
- 第1个组成部分即为上一小节的二元独立模型BIM计算得分,如果赋予一些默认值的话,等价于IDF因子的作用。
- 第2个组成部分是查询词在文档D中的权值,其中fi代表了单词在文档D中的词频,K因子代表了对文档长度的考虑,其计算公式为
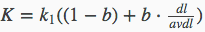
- k1为经验参数,作用是对查询词在文档中的词频进行调节。如果设为0,则第2部分整体变为1,即不考虑词频的因素,退化成了BIM模型;如果设为较大值,则第2部分计算因子基本与词频fi保持线性增长,即放大了词频的权值。根据经验,一般讲k1设置为1.2。
- b为调节因子,将b设为0时,文档长度因素将不起作用,经验表明一般b=0.75。
- dl代表当前文档D的长度。
- avdl代表文档集合中所有文档的平均长度。
- 第3个组成部分是查询词自身的权值,qfi表示查询词在用户查询中的词频,如果查询较短小的话,这个值一般是1,k2也为调节因子,是针对查询中的词频进行调节,因为查询往往很短,所以不同查询词的词频都很小,词频之间差异不大,为了放大这部分的差异,k2一般取值为
0~1000。
综合来看,BM25模型计算公式其实融合了4个考虑因素:IDF因子,文档长度因子,文档词频,和查询词频。并对3个自由调节因子(k1,k2,b)进行权值的调整。
例子:
假设当前以“乔布斯 IPAD2”这个查询词为例,来计算在某文档D中BM25相关性的值,由于不知道文档集中相关与不相关的分类,所以这里直接将相关文档个数r置为0,则将得到的BIM因子为:
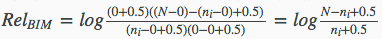
其他数值假定如下:
- 文档的集合总数:N=100000
- 包含
乔布斯的文档个数为:n乔布斯=1000 - 包含
IPAD2的文档个数为:nIPAD2=100 - 文档D中出现
乔布斯的词频为:f乔布斯=8 - 文档DD中出现
IPAD2的词频为:fIPAD2=8 - 查询词频均为:qfi=1
- 调节因子k1=1.2k
- 调节因子k2=200
- 调节因子b=0.75
- 设文档D的长度为平均长度的1.5倍(dl/avdl=1.5),即K=1.2×(0.25+0.75×1.5)=1.65
则最终可以计算到的BM25结果为:
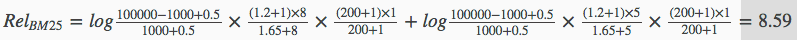
每个文档按上述公式计算得到相关性排序即可。
4. BM25F模型
在BM25模型中,文档被当做一个整体进行进行词频的统计,而忽视了不同区域的重要性,BM25F模型正是抓住了这点进行了相应的改进。
BM25F模型在计算相关性时候,会对文档分割成不同的域来进行加权统计,非常适用于网页搜索,因为在一个网页有标题信息、meta信息、页面内容信息等,而标题信息无疑是最重要的,其次是meta信息,最后才是网页内容,BM25F在计算相关性的,会将网页分为不用的区域,在各个区域分别统计自己的词频。
所以BM25F模型的计算公式为:
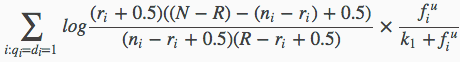
BM25F的第1部分还是BIM的值。
其中与BM25主要的差别体现在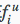 因子上,它是单词i在各个区域不同的得分,计算公式如下:
因子上,它是单词i在各个区域不同的得分,计算公式如下:
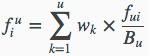
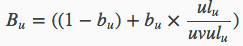
上面的公式表示:
- 文档D来个不同的u个域
- 各个域对应的权重为Wk
- fui为第i个单词在各个域中的 fui / Bu 的加权和
- fui表示词频
- Bu表示各个域的长度情况
- ulu为实际域的实际长度,uvulu表示域的平均长度
- bu则为各个域长度的调节因子
概率检索模型:BIM+BM25+BM25F的更多相关文章
- 概率检索模型及BM25
概率排序原理 以往的向量空间模型是将query和文档使用向量表示然后计算其内容相似性来进行相关性估计的,而概率检索模型是一种直接对用户需求进行相关性的建模方法,一个query进来,将所有的文档分为两类 ...
- [IR课程笔记]概率检索模型
几个符号意义: R:相关文档集 NR:不相关文档集 q:用户查询 dj:文档j 1/0风险情况 PRP(probability ranking principle):概率排序原理,利用概率模型来估计每 ...
- 概率主题模型简介 Introduction to Probabilistic Topic Models
此文为David M. Blei所写的<Introduction to Probabilistic Topic Models>的译文,供大家参考. 摘要:概率主题模型是一系列旨在发现隐藏在 ...
- 转:概率主题模型简介 --- ---David M. Blei所写的《Introduction to Probabilistic Topic Models》的译文
概率主题模型简介 Introduction to Probabilistic Topic Models 转:http://www.cnblogs.com/siegfang/archive/2 ...
- LDA概率主题模型
目录 LDA 主题模型 几个重要分布 模型 Unigram model Mixture of unigrams model PLSA模型 LDA 怎么确定LDA的topic个数? 如何用主题模型解决推 ...
- 概率图形模型(PGM)学习笔记(四)-贝叶斯网络-伯努利贝叶斯-贝叶斯多项式
之前忘记强调重要的差异:链式法则的条件概率和贝叶斯网络的链式法则之间的差异 条件概率链式法则 P\left({D,I,G,S,L} \right) = P\left( D \right)P\left( ...
- 概率图形模型(PGM)学习笔记(一)动机和概述
在本文中,基于Daphne Koller完成课程. PDM(ProbabilisticGraphiccal Models) 称为概率图模型. 以下分别说明3个词相应的意义. 概率 -给出了不确定性的明 ...
- 马尔可夫随机场(Markov random fields) 概率无向图模型 马尔科夫网(Markov network)
上面两篇博客,解释了概率有向图(贝叶斯网),和用其解释条件独立.本篇将研究马尔可夫随机场(Markov random fields),也叫无向图模型,或称为马尔科夫网(Markov network) ...
- Xapian索引-文档检索过程分析
本文是Xapian检索过程的分析,本文内容中源码比较多.检索过程,总的来说就是拉取倒排链,取得合法doc,然后做打分排序的过程. 1 理论分析 1.1 检索语法 面对不同的检索业务,我们会有多种检索 ...
随机推荐
- [工具] Textify – 复制不可能的窗口内容[Win]
Textify 是一款 Windows 下的小工具,能够复制那些平时无法复制的内容,比如错误提示.菜单按钮文字等等,只需要按下快捷键就可以随意复制,俗称复制不可能. http://rammichael ...
- oracle如何删除表空间
drop tablespace 表空间名 including contents and datafiles cascade constraint; ............. 以system用户登录, ...
- 使用Properties配置文件 InputStream与FileReader (java)
java 开发中,常常通过流读取的方式获取 配置文件数据,我们习惯使用properties文件,使用此文件需要注意 文件位置:任意,建议src下 文件名称:任意,扩展名为properties 文件内容 ...
- FFT【快速傅里叶变换】FWT【快速沃尔什变换】
实在是 美丽的数学啊 关于傅里叶变换的博客 讲的很细致 图片非常易于理解http://blog.jobbole.com/70549/ 大概能明白傅里叶变换是干吗的了 但是还是不能明白为什么用傅里叶变换 ...
- MySQL权限和用户管理
Mysql权限系统(由mysql权限表进行控制user和db)通过下面两个方面进行认证: 1)对于连接的用户进行身份验证,合法的通过验证,不合法的拒绝连接. 2)对于通过连接认证的用户,可以在合法的范 ...
- What is Gensim?
Gensim是一款开源的第三方Python工具包,用于从原始的非结构化的文本中,无监督地学习到文本隐层的主题向量表达.它支持包括TF-IDF,LSA,LDA,和word2vec在内的多种主题模型算法, ...
- Linux执行Cron Job失败,在Shell sh下执行却能成功 - 环境变量?
博客分类: Linux linuxcrontabpermissionetc/profile环境变量 一.我们常常碰到在shell下执行某个命令能够成功,比如执行一个java程序: java -jar ...
- iOS-绘图之CoreGraphics框架
第一步:先科普一下基础知识: Core Graphics是基于C的API,可以用于一切绘图操作 Core Graphics 和Quartz 2D的区别 quartz是一个通用的术语,用于描述在iOS和 ...
- iOS开发tableView去掉顶部上部空表区域
tableview中的第一个cell 里上部 有空白区域,大概64像素 在viewDidLoad中加入如下代码 self.automaticallyAdjustsScrollViewInsets = ...
- 安装JIRA
参考链接:https://www.cnblogs.com/houchaoying/p/9096118.html mysql-connector插件下载: https://mvnrepository.c ...