4.keras实现-->生成式深度学习之用GAN生成图像
生成式对抗网络(GAN,generative adversarial network)由Goodfellow等人于2014年提出,它可以替代VAE来学习图像的潜在空间。它能够迫使生成图像与真实图像在统计上几乎无法区别,从而生成相当逼真的合成图像。
1.GAN是什么?
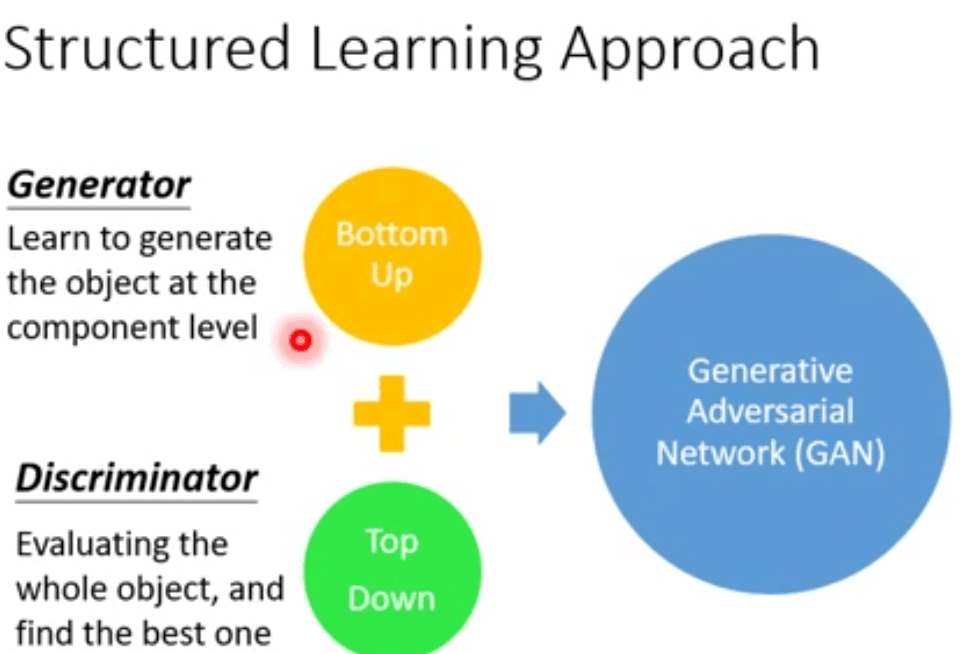
简单来说就是由两部分组成,生成器generator网络和判别器discriminator网络。一部分不断进化,使其对立部分也不断进化,实现共同进化的过程。
对GAN的一种直观理解是,想象我们想要试图生成一个二次元头像。一开始,我们并不擅长这项任务,就将自己的一些噪音二次元头像和真的二次元头像混在一起,并将其展示给discriminator。discriminator对每个头像进行真实性评估,并向我们给出反馈,告诉我们是什么让二次元头像看起来像真的二次元头像,我们回到自己的工作室,并准备一些新的二次元头像。随着时间的推移,我们变得越来越擅长模仿二次元头像的风格,discriminator也变得越来越擅长找出假的二次元头像。最后,我们手上拥有了一些优秀的二次元头像。

2.为什么?
【1】为什么我们有真的二次元头像和假的二次元头像,为什么不自己用监督学习生成新的二次元头像呢?
generator无法自己独立学习的原因是,以vae为例,输出layer层输出的是各像素点,而他们在输出时是独立的,没有相互作用的,因此无法判断总体的效果进行自主学习。对于discriminator,其输入是生成的整张图像,因此可以从总体上进行判断。
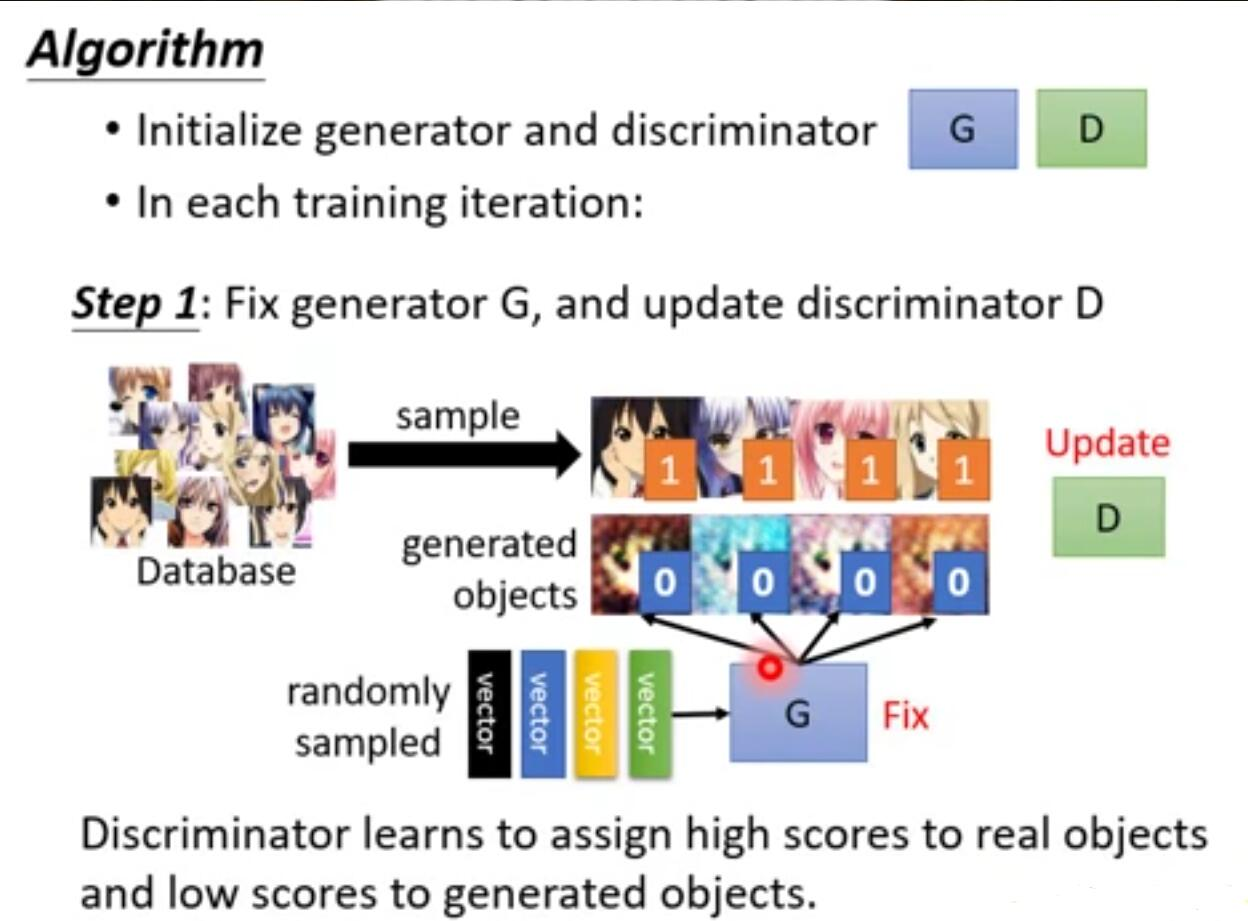
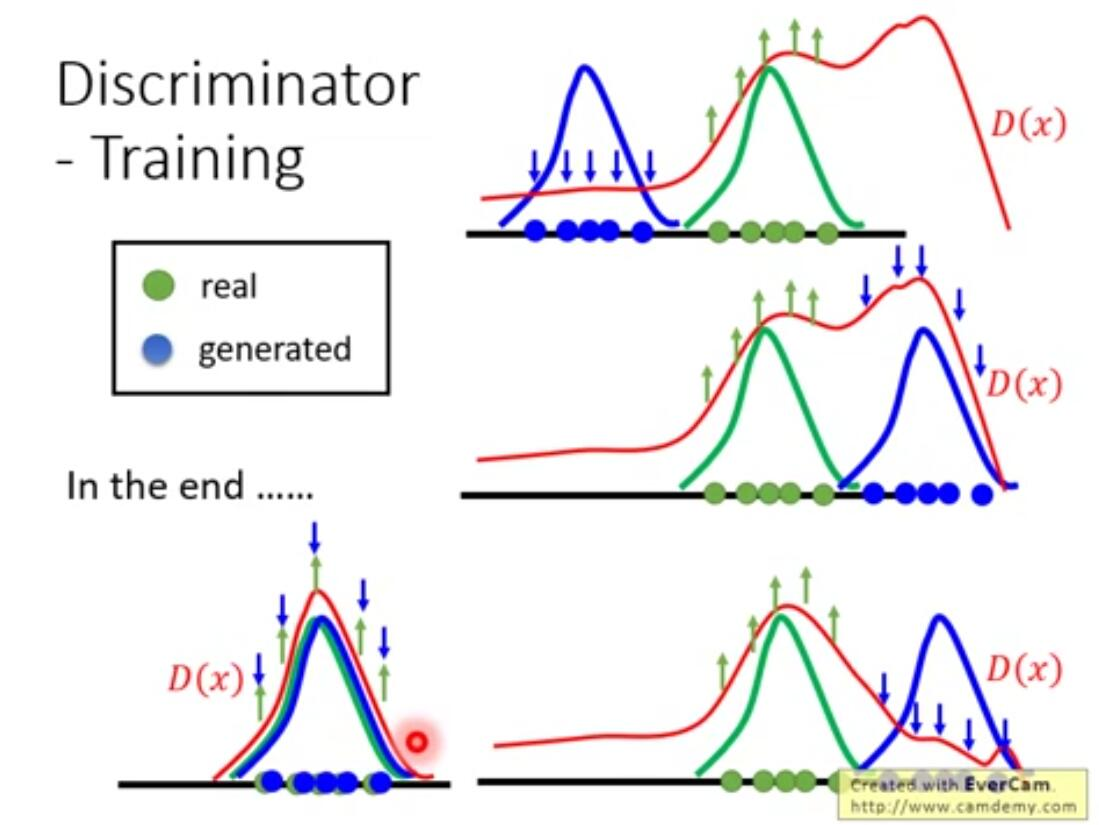
需要注意的是,discriminator对于输入的真实图像都应是高分,那么如果训练时只给它真实图像的话,他就无法实现正确的判断,会将所有输入都判为高分。所以需要一些差的图像送给discriminator进行训练,并且这些差的图像不应是简单的加些噪声之类的能让它轻易分辨的。因此,训练它的方法是,除真实图像外先给它一些随机生成的差的例子,然后对discriminator解argmaxD(x)做generation生成出一些他觉得好的图像,然后将原本极差的图像换为这些图像再进行训练,如此往复,discriminator会不断产生更好的图像,将这些作为negative examples给其学习,达到训练的目的。
【2】discriminator对真的二次元头像这么了解,为什么他不自己做,而是要来指导我们做呢?
那既然如此,为什么还需要generator呢?discriminator自己也可以生成图像啊?
这是因为discriminator生成图像需要解argmaxD(x), 难度较大,一般需要假设一些条件才会好解,比如网络假设为线性时,但这样会限制图像的生成效果。而generator生成非常快,因此将二者结合起来共同学习实现输出好的结果。二者优缺点如下所示:
总而言之,因为generator没有全局观,所以需要结合discriminator学习,对于discriminator,使用generator生成图像比自己解方程生成更简单高效,这二者的优缺点相互补充。
GAN的目的是为了生成,而VAE目的是为了压缩,目的不同效果自然不同。比如,由于二范数的原因,VAE的生成是模糊的。而GAN的生成是犀利的。

数据集为CIFAR10,包含50000张32*32的RGB图像,这些图像属于10个类别(每个类别5000张图像),这里我们只使用属于“frog”(青蛙)类别的图像
import keras
|
|
|
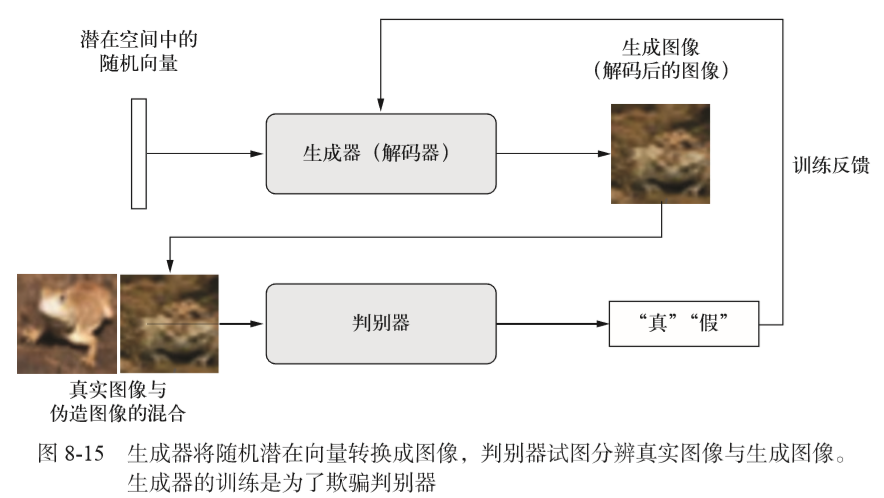
生成器网络:将一个向量(来自潜在空间,训练过程中对其随机采样)转换为一张候选图像 生成器从未直接见过训练集中的图像,它所知道的关于数据的信息都来自于判别器。 |
|
latent_dim = 32
|
|
|
判别器网络:它接收一张候选图像(真实的或合成的)作为输入,并将其划分到这两个类别之一:"生成图像"或"来自训练集的真实图像" |
|
#GAN判别器网络
|
|
discriminator_optimizer = keras.optimizers.RMSprop(
|
设置GAN,将生成器和判别器连接在一起 训练时,这个模型将让生成器向某个方向移动,从而提高它欺骗判别器的能力。这个模型将潜在空间的点转换为一个分类决策(即"真"或"假") 它训练的标签都是"真实图像"。因此,训练gan将会更新generator得到权重,使得discriminator在观测假图像时更有可能预测为"真"。 |
|
对抗网络 |
|
discriminator.trainable = True #将判别器权重设置为不可训练(仅应用于gan模型) gan_input = keras.Input(shape=(latent_dim,))
|
注意:在训练过程中需要将判别器设置为冻结(即不可训练),这样在训练gan时它的权重才不会更新。 如果在此过程中可以对判别器的权重进行更新,那么我们就是在训练判别器始终预测"真",但这并不是我们想要的。 |
|
实现GAN的训练 |
|
import os
|
|
iterations = 1000
|
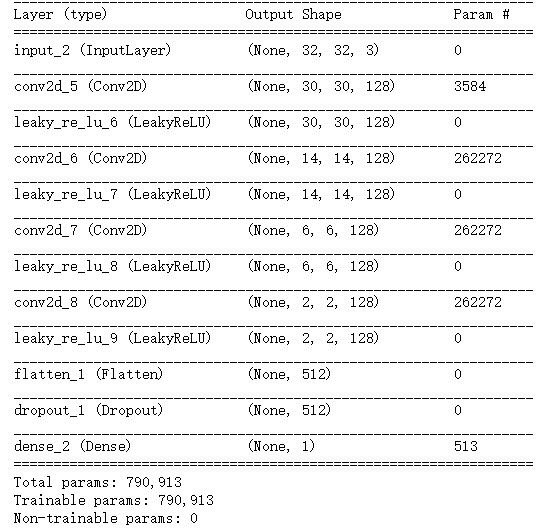
判别器损失:d_loss=(生成的图像和真实图像->标签) gan损失:a_loss=(随机采样的点->全是'真'的标签) 第一次 最后一次 |

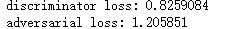
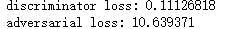
4.keras实现-->生成式深度学习之用GAN生成图像的更多相关文章
- 4.keras实现-->生成式深度学习之用变分自编码器VAE生成图像(mnist数据集和名人头像数据集)
变分自编码器(VAE,variatinal autoencoder) VS 生成式对抗网络(GAN,generative adversarial network) 两者不仅适用于图像,还可以 ...
- 4.keras实现-->生成式深度学习之DeepDream
DeepDream是一种艺术性的图像修改技术,它用到了卷积神经网络学到的表示,DeepDream由Google于2015年发布.这个算法与卷积神经网络过滤器可视化技术几乎相同,都是反向运行一个卷积神经 ...
- 从零开始学会GAN 0:第一部分 介绍生成式深度学习(连载中)
本书的前四章旨在介绍开始构建生成式深度学习模型所需的核心技术.在第1章中,我们将首先对生成式建模领域进行广泛的研究,并从概率的角度考虑我们试图解决的问题类型.然后,我们将探讨我们的基本概率生成模型的第 ...
- 深度学习新星:GAN的基本原理、应用和走向
深度学习新星:GAN的基本原理.应用和走向 (本文转自雷锋网,转载已获取授权,未经允许禁止转载)原文链接:http://www.leiphone.com/news/201701/Kq6FvnjgbKK ...
- 深度学习之 rnn 台词生成
深度学习之 rnn 台词生成 写一个台词生成的程序,用 pytorch 写的. import os def load_data(path): with open(path, 'r', encoding ...
- 转:TensorFlow和Caffe、MXNet、Keras等其他深度学习框架的对比
http://geek.csdn.net/news/detail/138968 Google近日发布了TensorFlow 1.0候选版,这第一个稳定版将是深度学习框架发展中的里程碑的一步.自Tens ...
- 深度学习----现今主流GAN原理总结及对比
原文地址:https://blog.csdn.net/Sakura55/article/details/81514828 1.GAN 先来看看公式: GAN网络主要由两个网络构 ...
- 惊不惊喜, 用深度学习 把设计图 自动生成HTML代码 !
如何用前端页面原型生成对应的代码一直是我们关注的问题,本文作者根据 pix2code 等论文构建了一个强大的前端代码生成模型,并详细解释了如何利用 LSTM 与 CNN 将设计原型编写为 HTML 和 ...
- 深度学习在gilt应用——用图像相似性搜索引擎来商品推荐和服务属性分类
机器学习起源于神经网络,而深度学习是机器学习的一个快速发展的子领域.最近的一些算法的进步和GPU并行计算的使用,使得基于深度学习的算法可以在围棋和其他的一些实际应用里取得很好的成绩. 时尚产业是深度学 ...
随机推荐
- 【JavaScript】如何判断一个对象是未定义的?(已解决)
JavaScript中,如果使用了一个未定义的变量,会有这样的错误提示:XXX未定义. 代码中,怎样才能判定一个对象是否定义了呢? 使用 typeof 示例: if("undefined& ...
- Promise 必知必会的面试题
Promise 想必大家都十分熟悉,想想就那么几个 api,可是你真的了解 Promise 吗?本文根据 Promise 的一些知识点总结了十道题,看看你能做对几道. 以下 promise 均指代 P ...
- sencha touch 自定义cardpanel控件 模仿改进NavigationView 灵活添加按钮组,导航栏,自由隐藏返回按钮(废弃 仅参考)
最新版本我将会放在:http://www.cnblogs.com/mlzs/p/3382229.html这里的示例里面,这里不会再做更新 代码: /* *模仿且改进NavigationView *返回 ...
- “找女神要QQ号码”——java篇
题目就是这样的: 给了一串数字(不是QQ号码),根据下面规则可以找出QQ号码: 首先删除第一个数,紧接着将第二个数放到这串数字的末尾,再将第三个数删除,并将第四个数放到这串数字的末尾...... 如此 ...
- Java虚拟机五 堆的参数配置
堆空间是Java进程的重要组成部分,几乎所有的应用相关的内存空间都和堆有关. 1.最大堆和初始堆的设置 当Java程序启动时,虚拟机就会分配一块初始堆空间,使用参数 -Xms 指定这块空间的大小.一般 ...
- Function学习
---恢复内容开始--- Function的定义: 1.函数声明 function sum1(){ alert("sum1") } 2.函数表达式 var sum2 = funct ...
- iOS - 仿微信朋友圈视频剪切功能
分析需求 我们先看一看微信的界面 微信效果图 1.页面下部拖动左边和右边的白色竖条控制剪切视频的开始和结束时间,预览界面跟随拖动位置跳到视频相应帧画面,控制视频长度最长15秒,最短5秒 2.拖动下部图 ...
- 通过JS模拟select表单,达到美化效果[demo][转]
转自: http://www.cnblogs.com/dreamback/p/SelectorJS.html 通过JS模拟select表单,达到美化效果 Demo ------------------ ...
- hdu1272 小希的迷宫【并查集】
上次Gardon的迷宫城堡小希玩了很久(见Problem B),现在她也想设计一个迷宫让Gardon来走.但是她设计迷宫的思路不一样,首先她认为所有的通道都应该是双向连通的,就是说如果有一个通道连通了 ...
- ZOJ 3780 - Paint the Grid Again - [模拟][第11届浙江省赛E题]
题目链接:http://acm.zju.edu.cn/onlinejudge/showProblem.do?problemCode=3780 Time Limit: 2 Seconds Me ...