numpy 数组迭代Iterating over arrays
在numpy 1.6中引入的迭代器对象nditer提供了许多灵活的方式来以系统的方式访问一个或多个数组的所有元素。
1 单数组迭代
该部分位于numpy-ref-1.14.5第1.15 部分Single Array Iteration。
利用nditer对象可以实现完成访问数组中的每一个元素这项最基本的功能,使用标准的python迭代器接口可以逐个访问每一个元素。
1.1 默认迭代顺序
a = np.arange(6).reshape(2,3)
b = a.T
print(a)
# [[0 1 2]
# [3 4 5]]
for i in np.nditer(a):
print(i)
# 1 2 3 4 5 6(节约版面,竖着 -> 横着)
print(b)
# [[0 3]
# [1 4]
# [2 5]]
for j in np.nditer(b):
print(j)
# 1 2 3 4 5 6(节约版面,竖着 -> 横着)
注意:通过该种方式迭代输出的是以元素在存储器中的布局顺序输出的,无论其视图做何种改变(转置,变换shape),其输出结果是一致的,该中方式可以提高迭代效率
1.2 控制迭代顺序 Controlling Iteration Order
有时候我们不去考虑元素在存储器中的位置关系,而需要按照特定顺序(如视图顺序)访问数组中的元素,nditer对象提供了一个命令参数来控制迭代输出顺序;
nditer 默认是‘K',也即order = ’K‘,该默认值为按在存储器中的顺序输出(keep the existing order),默认迭代顺序。
同时 nditer 中还提供了两个参数以控制迭代器输出顺序
- order = ‘ C ’ 按行访问,
for x in np.nditer(a.T, order='C')
等价于
for x in np.nditer(a.T.copy(order='C'))
- order = ' F ' 按列访问,
for x in np.nditer(a.T, order='F')
等价于
for x in np.nditer(a.T.copy(order='F'))
注意:虽然等价,当时其原理是不一样的,
(1)A和A.T的元素以相同的顺序遍历,即它们存储在存储器中的顺序,而A.T.拷贝的元素(order=‘C’)以不同的顺序被访问,因为它们被放入不同的存储器布局中。
(2)order = ’C‘ / ’F‘ 只是输出顺序改变了。
1.3 修改数组值(Modify Array Values)
一般情况下,python中的常规赋值只需要更变本地变量或全局变量字典中的引用,而不必修改现有变量。
默认情况下,nditer对象将输入数组视为只读对象,要修改数组中的元素,必须指定读写read-write 或只写write-only 模式,这是用每个操作数标志(per-operand flags )来控制的。
a = np.arange(6).reshape(2,3)
print(a)
# [[0 1 2]
# [3 4 5]]
for x in np.nditer(a ,op_flags=['readwrite']):
x[...] = 2 * x
print(a)
# [[ 0 2 4]
# [ 6 8 10]]
如果不添加 op_flags=['readwrite'] ,则 ValueError: assignment destination is read-only ,所以必须添加readwrite;
一般是从数组元素中引用x,将其转换为所赋值的引用,而不会再将所赋值放入数组元素中;可以简单理解为可以从数组中取出元素并对元素值进行赋值运算,但是不能将计算后的值再放入数组中,如果要实现修改数组中的元素,x应该用省略号索引
注意:
a = np.arange(6).reshape(2,3)
print(a)
# [[0 1 2]
# [3 4 5]]
for i in np.nditer(a ,op_flags=['readwrite']):
i = i * 2
print(a) #a值不发生改变
# [[0 1 2]
# [3 4 5]]
for j in np.nditer(a ,op_flags=['readwrite']):
j *= 2
print(a) #a值均*2
# [[ 0 2 4]
# [ 6 8 10]]
疑惑:按照语法规则,i = i *2 等价于 i *=2 ,为什么结果却不一样!有知道的请留言说一下,谢谢!
2 数组迭代(Iterating over arrays)
该部分内容位于numpy-ref-1.14.5中的3.15.4 Iterating over arrays 章节
numpy.nditer 为高效多维迭代器对象,用于对数组的迭代。
flags:sequence of str ,optional
用于控制迭代器行为的标志(flags)
buffrered - 再需要时可以缓冲
c_index - 跟踪C顺序的索引
f_index - 跟踪F顺序的索引
multi_index - 跟踪 多指标,或每个迭代维度的一组指数
external_loop - 外部循环,将一维的最内层的循环转移到外部循环迭代器,使得numpy的矢量操作在处理更大规模数据时变得更有效率。
op_flags:list of list of str , optional
这是每个操作数的标志列表。至少必须指定一个“只读”、“读写”或“写”。
readonly - 该操作数表明可以读取
readwrite - 该操作数表明可以读取和写入
writeonly - 该操作数表明仅写入
no_broadcast - 该操作数可以防止被广播
copy - 该操作数表明允许临时只读拷贝
op_dtypes:dtype or tuple of dtype(s), optional
操作数所需的数据类型(s)。
order:{‘C’, ‘F’, ‘A’, ‘K’}, optional
控制迭代顺序(Controls the iteration order)
2.1 使用外部循环 external_loop
将一维的最内层的循环转移到外部循环迭代器,使得numpy的矢量化操作在处理更大规模数据时变得更有效率。
a = np.arange(6).reshape(2,3)
print(a)
# [[0 1 2]
# [3 4 5]]
for x in np.nditer(a, flags = ['external_loop']):
print(x)
# [0 1 2 3 4 5]
for x in np.nditer(a, flags = ['external_loop'],order = 'C'):
print(x)
# [0 1 2 3 4 5]
for x in np.nditer(a, flags = ['external_loop'],order = 'F'):
print(x)
# [0 3]
# [1 4]
# [2 5]
面试题:面试题:将矩阵旋转90度,这道题写完之后,非常有成就感!
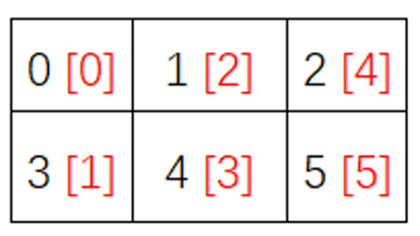
2.2 追踪单个索引或多重索引
a = np.arange(6).reshape(2,3)
print(a)
# [[0 1 2]
# [3 4 5]]
it = np.nditer(a,flags = ['f_index'])
while not it.finished:
print("%d <%d>" % (it[0], it.index))
it.iternext()
# 0 <0>
# 1 <2>
# 2 <4>
# 3 <1>
# 4 <3>
# 5 <5>
为了更清楚地表述,可以直观地看下表
flags = multi_index
a = np.arange(6).reshape(2,3)
print(a)
# [[0 1 2]
# [3 4 5]]
it = np.nditer(a,flags = ['multi_index'])
while not it.finished:
print("%d <%s>" % (it[0], it.multi_index))
it.iternext()
# 0 <(0, 0)>
# 1 <(0, 1)>
# 2 <(0, 2)>
# 3 <(1, 0)>
# 4 <(1, 1)>
# 5 <(1, 2)>
multi_index是将元素的行列位置以元组方式打印出来,但元组形式不是整型,所以要将 %d 变为 %s,
若不改,则会报错 TypeError: %d format: a number is required, not tuple
a = np.arange(6).reshape(1,2,3)
print(a)
# [[[0 1 2]
# [3 4 5]]]
it = np.nditer(a,flags = ['multi_index'])
while not it.finished:
print("%d <%s>" % (it[0], it.multi_index))
it.iternext()
# 0 <(0, 0, 0)>
# 1 <(0, 0, 1)>
# 2 <(0, 0, 2)>
# 3 <(0, 1, 0)>
# 4 <(0, 1, 1)>
# 5 <(0, 1, 2)>
2.3 广播迭代
如果两个数组是 可广播的,nditer组合对象能够同时迭代它们,假设数组 a 具有维度 3*4 ,并且存在维度为 1*4的另一个数组b,则使用以下类型的迭代器(数组b被广播到a的大小)
a = np.arange(0,60,5).reshape(3,4)
print(a)
# [[ 0 5 10 15]
# [20 25 30 35]
# [40 45 50 55]]
b = np.array([1, 2, 3, 4], dtype = int)
print(b)
# [1 2 3 4]
for x,y in np.nditer([a,b]):
print("%d:%d" %(x,y))
# 0:1
# # 5:2
# # 10:3
# # 15:4
# # 20:1
# # 25:2
# # 30:3
# # 35:4
# # 40:1
# # 45:2
# # 50:3
# # 55:4
参考:NumPy - 数组上的迭代、nditer —— numpy.ndarray 多维数组的迭代、python nditer---迭代数组、numpy-ref-1.14.5官方文档(1.5 Iterating Over Arrays )。
numpy 数组迭代Iterating over arrays的更多相关文章
- NumPy 数组迭代
章节 Numpy 介绍 Numpy 安装 NumPy ndarray NumPy 数据类型 NumPy 数组创建 NumPy 基于已有数据创建数组 NumPy 基于数值区间创建数组 NumPy 数组切 ...
- 8、numpy——数组的迭代
1.单数组的迭代 NumPy 迭代器对象 numpy.nditer 提供了一种灵活访问一个或者多个数组元素的方式. 迭代器最基本的任务的可以完成对数组元素的访问. 1.1 默认迭代顺序 import ...
- NumPy 数组切片
章节 Numpy 介绍 Numpy 安装 NumPy ndarray NumPy 数据类型 NumPy 数组创建 NumPy 基于已有数据创建数组 NumPy 基于数值区间创建数组 NumPy 数组切 ...
- NumPy 数组创建
章节 Numpy 介绍 Numpy 安装 NumPy ndarray NumPy 数据类型 NumPy 数组创建 NumPy 基于已有数据创建数组 NumPy 基于数值区间创建数组 NumPy 数组切 ...
- Numpy数组对象的操作-索引机制、切片和迭代方法
前几篇博文我写了数组创建和数据运算,现在我们就来看一下数组对象的操作方法.使用索引和切片的方法选择元素,还有如何数组的迭代方法. 一.索引机制 1.一维数组 In [1]: a = np.arange ...
- Numpy 数组操作
Numpy 数组操作 Numpy 中包含了一些函数用于处理数组,大概可分为以下几类: 修改数组形状 翻转数组 修改数组维度 连接数组 分割数组 数组元素的添加与删除 修改数组形状 函数 描述 resh ...
- 玩转NumPy数组
一.Numpy 数值类型 1.前言:Python 本身支持的数值类型有 int(整型, long 长整型).float(浮点型).bool(布尔型) 和 complex(复数型).而 Numpy 支持 ...
- 操作 numpy 数组的常用函数
操作 numpy 数组的常用函数 where 使用 where 函数能将索引掩码转换成索引位置: indices = where(mask) indices => (array([11, 12, ...
- NumPy 超详细教程(1):NumPy 数组
系列文章地址 NumPy 最详细教程(1):NumPy 数组 NumPy 超详细教程(2):数据类型 NumPy 超详细教程(3):ndarray 的内部机理及高级迭代 文章目录 Numpy 数组:n ...
随机推荐
- Robotframework(4):创建变量的类型和使用
转载:http://www.cnblogs.com/CCGGAAG/p/7800321.html 实际的测试过程中,编写脚本时,我们需要创建一些变量来暂时或者永久性的存储数据,那么在Robotfram ...
- 编程王道,唯“慢”不破
原文地址 人和人之间编程速度的差异还是很大的,有的程序猿写代码非常快,有的却常常是龟速.Jeffrey Ventrella 最近在一篇文章里探讨了这种编程速度的差异,他是绝对的龟速派代表,来看看他对编 ...
- springboot升级到2.0后context-path配置不起作用
springboot升级到2.0后,context-path配置不起作用,改成了: server.servlet.context-path=/projname
- 【转】一些linux基础命令
学习Linux,其实很多基础命令很重要. 不论多么复杂的shell或者命令组合,都是一个一个的拼接组合命令拼接而成: 大号一个基本功,遇到需要的场景,信手拈来,随意组合拼接,是非常重要的. 恰好看到一 ...
- 微信小程序 - 自定义switch切换(示例)
点击下载:switch示例 ,适用于表单,官方switch 说明 .
- 解决Visio复制绘图时虚框变实框的问题
参考:http://www.educity.cn/help/653700.html 问题好像是,在VISIO里只要虚线框的大小超过一个界限,拷贝之后就会变成实线框. 解决办法是修改注册表:[运行reg ...
- mysql标准写法及其他常见问题
/* Navicat MySQL Data Transfer Source Server : localhost_3306 Source Server Version : 50549 Source H ...
- 配置Git绑定Git@OSC
用户名,这个名字会出现在以后的提交记录中. git config --global user.name "Git@OSC用户名" 然后是Email,同样,这个Email也会出现在你 ...
- Java多线程之锁优化策略
转载请注明原文地址:http://www.cnblogs.com/ygj0930/p/6561264.html 锁的优化策略 编码过程中可采取的锁优化的思路有以下几种: 1:减少锁持有时间 例如:对 ...
- oracle的参数文件:pfile和spfile
1.pfile和spfile Oracle中的参数文件是一个包含一系列参数以及参数对应值的操作系统文件.它们是在数据库实例启动时候加载的,决定了数据库的物理 结构.内存.数据库的限制及系统大量的默认值 ...