转: 基于elk 实现nginx日志收集与数据分析
原文链接:https://www.cnblogs.com/wenchengxiaopenyou/p/9034213.html
一。背景
前端web服务器为nginx,采用filebeat + logstash + elasticsearch + granfa 进行数据采集与展示,对客户端ip进行地域统计,监控服务器响应时间等。
二。业务整体架构:
nginx日志落地——》filebear——》logstash——》elasticsearch——》grafna(展示)
三。先上个效果图,慢慢去一步步实现
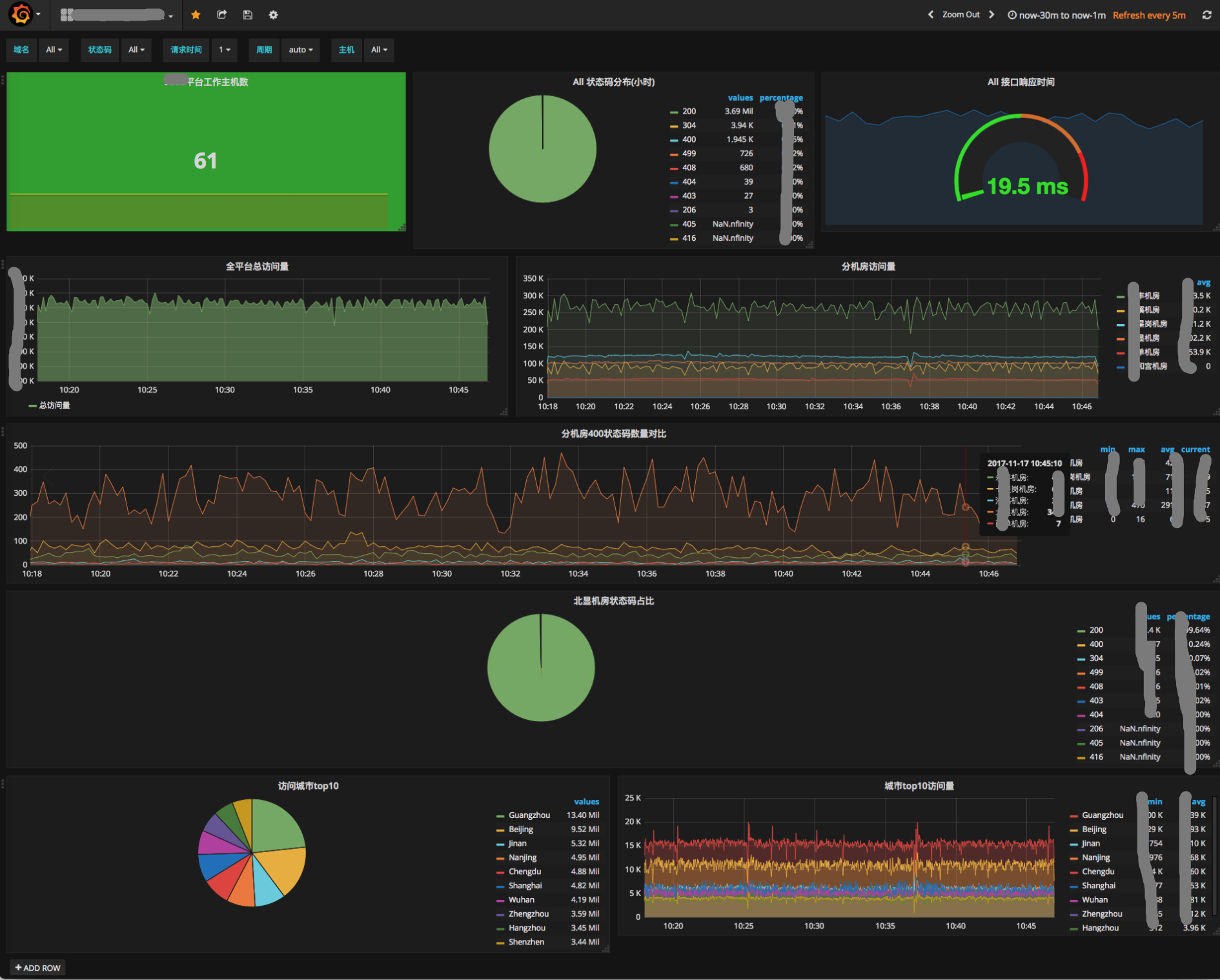
如上只是简单的几个实用的例子,实际上有多维度的数据之后还可以定制很多需要的内容,如终端ip访问数,国家、地区占比,访问前十的省份,请求方法占比,referer统计,user_agent统计,慢响应时间统计,更有世界地图坐标展示等等,只要有数据就能多维度进行展示。这里提供模板搜索位置大家可以查找参考:https://grafana.com/dashboards
四,准备条件
需要具备如下条件:
1.nginx日志落地,需要主要落地格式,以及各个字段对应的含义。
2.安装filebeat。 filebeat轻量,功能相比较logstash而言比较单一。
3.安装logstash 作为中继服务器。这里需要说明一下的是,起初设计阶段并没有计划使用filebeat,而是直接使用logstash发往elasticsearch,但是当前端机数量增加之后logstash数量也随之增加,同时发往elasticsearch的数量增大,logstash则会抛出由于elasticsearch 限制导致的错误,大家遇到后搜索相应错误的代码即可。为此只采用logstash作为中继。
4.elasticsearch 集群。坑点是index templates的创建会影响新手操作 geoip模块。后文会有。
5.grafana安装,取代传统的kibana,grafana有更友好、美观的展示界面。
五。实现过程
1.nginx日志落地配置
nginx日志格式、字段的内容和顺序都是高度可定制化的,将需要收集的字段内容排列好。定义一个log_format
定义的形势实际上直接决定了logstash配置中对于字段抽取的模式,这里有两种可用,一种是直接在nginx日志中拼接成json的格式,在logstash中用codec => "json"来转换,
一种是常规的甚至是默认的分隔符的格式,在logstash中需要用到grok来进行匹配,这个会是相对麻烦些。两种方法各有优点。直接拼接成json的操作比较简单,但是在转码过程中
会遇到诸如 \x 无法解析的情况。 这里我也遇到过,如有必要后续会详谈。采用grok来匹配的方法相对难操作,但是准确性有提升。我们这里采用的是第一种方法,下面logstash部分
也会给出采用grok的例子。 nginx日志中日志格式定义如下:
|
1
2
3
4
5
6
7
8
9
10
|
log_format access_json '{"timestamp":"$time_iso8601",' '"hostname":"$hostname",' '"ip":"$remote_addrx",' '"request_method":"$request_method",' '"domain":"XXXX",' '"size":$body_bytes_sent,' '"status": $status,' '"responsetime":$request_time,' '"sum":"1"' '}'; |
2.filebeat配置文件
关于filebeat更多内容请参考https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-overview.html
配置文件内容:filebeat.yml 这里应该不会遇到坑。
|
1
2
3
4
5
6
7
|
filebeat.prospectors:- input_type: log paths: - /data0/logs/log_json/*.log #nginx日志路径output.logstash: hosts: ["xxxx.xxxx.xxxx.xxx:12121"] #logstash 服务器地址 |
3.logstahs配置文件内容:
这里是针对json已经拼接号,直接进行json转码的情况:
需要注意如下:
1)date模块必须有,否则会造成数据无法回填导致最终的图像出现锯齿状影响稳定性(原因是排列时间并不是日志产生的时间,而是进入logstash的时间)。这里后面的 yyyy-MM-dd'T'HH:mm:ssZZ 需要根据你日志中的日期格式进行匹配匹配规则见:https://www.elastic.co/guide/en/logstash/current/plugins-filters-date.html
2)需要说明的是我下面去掉了好多的字段(remove_field),原因是我们数据量大,es服务器有限。 可以根据需要随时调整收集的字段。
3) geoip 仅需要指定源ip字段名称即可,fields并不是必须的,我加入的原因还是由于资源有限导致的。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
|
input { beats { port => 12121 host => "10.13.0.80" codec => "json" }}filter { date { match => [ "timestamp", "yyyy-MM-dd'T'HH:mm:ssZZ" ] #timezone => "Asia/Shanghai" #timezone => "+00:00" } mutate { convert => [ "status","integer" ] convert => [ "sum","integer" ] convert => [ "size","integer" ] remove_field => "message" remove_field => "source" remove_field => "tags" remove_field => "beat" remove_field => "offset" remove_field => "type" remove_field => "@source" remove_field => "input_type" remove_field => "@version" remove_field => "host" remove_field => "client" #remove_field => "request_method" remove_field => "size" remove_field => "timestamp" #remove_field => "domain" #remove_field => "ip" } geoip { source => "ip" fields => ["country_name", "city_name", "timezone","region_name","location"] }}output { elasticsearch { hosts => ["xxx:19200","xxx:19200","xxx:19200"] user => "xxx" password => "xxx" index => "logstash-suda-alllog-%{+YYYY.MM.dd}" flush_size => 10000 idle_flush_time => 35 }} |
下面给出一个采用grok的例子:
其中match内的内容不用参考我的,需要根据你的字段个数,以及格式来定制。 这里其实是正则表达式。自带了一部分几乎就可以满足所有的需求了无需自己写了,可以参考:https://github.com/elastic/logstash/blob/v1.4.0/patterns/grok-patterns 直接用即可。

input {
file {
type => "access"
path => ["/usr/local/nginx/logs/main/*.log"]
}
}
filter {
if [type] == "access" {
if [message] =~ "^#" {
drop {}
}
grok {
match => ["message", "\[%{HTTPDATE:log_timestamp}\] %{HOSTNAME:server_name} \"%{WORD:request_method} %{NOTSPACE:query_string} HTTP/%{NUMBER:httpversion}\" \"%{GREEDYDATA:http_user_agent}\" %{NUMBER:status} %{IPORHOST:server_addr} \"%{IPORHOST:remote_addr}\" \"%{NOTSPACE:http_referer}\" %{NUMBER:body_bytes_sent} %{NUMBER:time_taken} %{GREEDYDATA:clf_body_bytes_sent} %{NOTSPACE:uri} %{NUMBER:m_request_time}"]
}
date {
match => [ "log_timestamp", "dd/MMM/yyyy:mm:ss:SS Z" ]
timezone => "Etc/UTC"
}
mutate {
convert => [ "status","integer" ]
convert => [ "body_bytes_sent","integer" ]
convert => [ "m_request_time","float" ]
}
在提供一个高级的用法:
ruby:强大的模块, 可以进行诸如时间转换,单位计算等,多个可以用分号隔开。
ruby {
code => "event.set('logdateunix',event.get('@timestamp').to_i);event.set('request_time', event.get('m_request_time') / 1000000 )"
}
mutate {
add_field => {
"http_host" => "%{server_name}"
"request_uri" => "%{uri}"
}
在windowns上使用lgostsh需要注意的是:(win上收集iis的日志,我想正常环境是不会用到的,但是我确实用到了。。。。。。)
path路径一定要采用 linux中的分割符来拼接路径,用win的格式则正则不能实现,大家可以测试下。其他配置则无区别。
input {
file {
type => "access"
path => ["C:/WINDOWS/system32/LogFiles/W3SVC614874788/*.log"]
}
}
4.elasticsearch配置,集群的安装以及启动,调优这里不多说(说不完),需要注意的一个是,geoip location的格式,我这里采用的是index templates来实现的如下:
最重要的是 "location" 定义 (否则geoip_location字段格式有问题,无法拼接成坐标),其他可以根据情况自定:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
{ "order": 0, "version": 50001, "index_patterns": [ "suda-*" ], "settings": { "index": { "number_of_shards": "5", "number_of_replicas": "1", "refresh_interval": "200s" } }, "mappings": { "_default_": { "dynamic_templates": [ { "message_field": { "path_match": "message", "mapping": { "norms": false, "type": "text" }, "match_mapping_type": "string" } }, { "string_fields": { "mapping": { "norms": false, "type": "text", "fields": { "keyword": { "ignore_above": 256, "type": "keyword" } } }, "match_mapping_type": "string", "match": "*" } } ], "properties": { "@timestamp": { "type": "date" }, "geoip": { "dynamic": true, "properties": { "ip": { "type": "ip" }, "latitude": { "type": "half_float" }, "location": { "type": "geo_point" }, "longitude": { "type": "half_float" } } }, "@version": { "type": "keyword" } } } }, "aliases": {}} |
5 grafana 安装以及模板创建,这个比较简单,安装完直接写语句即可附一个例子如下:
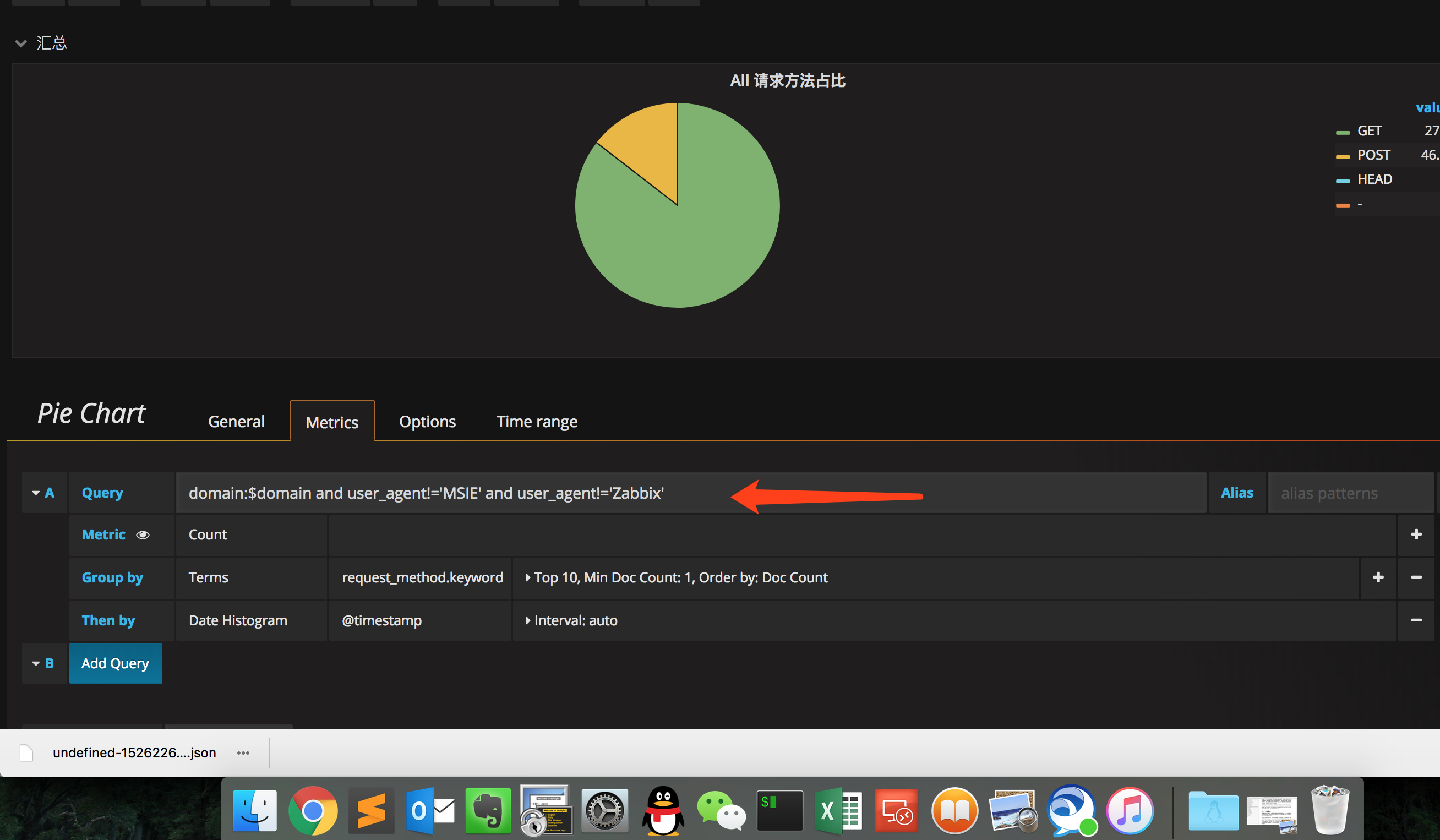
这里的变量需要自定义:

通过上面应该能够完成一个完整的收集和展示情况,这里实际上提供了一种可行的方法,并么有太大的具体操作。
希望多多交流
推荐内容:kibana中文指南(有ibook版本,看着挺方便) 三斗室著
https://www.elastic.co/cn/
https://grafana.com/dashboards
https://grafana.com/
转: 基于elk 实现nginx日志收集与数据分析的更多相关文章
- 基于elk 实现nginx日志收集与数据分析。
一.背景 前端web服务器为nginx,采用filebeat + logstash + elasticsearch + granfa 进行数据采集与展示,对客户端ip进行地域统计,监控服务器响应时间等 ...
- ELK 6安装配置 nginx日志收集 kabana汉化
#ELK 6安装配置 nginx日志收集 kabana汉化 #环境 centos 7.4 ,ELK 6 ,单节点 #服务端 Logstash 收集,过滤 Elasticsearch 存储,索引日志 K ...
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- ELK+Kafka 企业日志收集平台(一)
背景: 最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项:所以最近将Redis ...
- ELK对nginx日志进行流量监控
ELK对nginx日志进行流量监控 一.前言 线上有一套ELK单机版,版本为5.2.1.现在想把nginx访问日志接入到elk里,进行各个域名使用流量带宽的统计分析.要把nginx日志传输到elk上, ...
- 使用Docker快速部署ELK分析Nginx日志实践
原文:使用Docker快速部署ELK分析Nginx日志实践 一.背景 笔者所在项目组的项目由多个子项目所组成,每一个子项目都存在一定的日志,有时候想排查一些问题,需要到各个地方去查看,极为不方便,此前 ...
- 基于Flume的美团日志收集系统(二)改进和优化
在<基于Flume的美团日志收集系统(一)架构和设计>中,我们详述了基于Flume的美团日志收集系统的架构设计,以及为什么做这样的设计.在本节中,我们将会讲述在实际部署和使用过程中遇到的问 ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
- 基于Flume的美团日志收集系统(一)架构和设计【转】
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
随机推荐
- oj
https://github.com/zhblue/hustoj insert into privilege(user_id,rightstr) values('wxy','administrator ...
- hadoop mahout 算法和API说明
org.apache.mahout.cf.taste.hadoop.item.RecommenderJob.main(args) --input 偏好数据路径,文本文件.格式 userid\t ite ...
- python 大小端数据转换
"6fe28c0ab6f1b372c1a6a246ae63f74f931e8365e15a089c68d6190000000000".decode('hex')[::-1].enc ...
- 通用ajax请求方法封装,兼容主流浏览器
ajax简单介绍 没有AJAX会怎么样?普通的ASP.Net每次运行服务端方法的时候都要刷新当前页面. 假设没有AJAX,在youku看视频的过程中假设点击了"顶.踩".评论.评论 ...
- 转:CMake快速入门教程-实战
CMake快速入门教程:实战 收藏人:londonKu 2012-05-07 | 阅:10128 转:34 | 来源 | 分享 0. 前言一个多月 ...
- 解决CSS的position:absolute中left效果
有时候css中设置了position:absolute,left:100px,但是如果我们不想要这个left怎么办呢,当然你直接删除就可以,但是如果是框架的css,你直接删除就有问题了,这时候该怎么办 ...
- Textview文字监控(输入到某个字符后,进行操作)
以手机号充值为例,当用户输入最后一位数时候,进行汇率的变换. 1.首先给用户添加一个textchangedlistener 2.然后再写一个文字变化的监视器 mobile_et.add ...
- java struts2入门学习---自定义类型转换
自定义类型转换器的作用就是将struts无法识别的类型转换成自己所需要的. 比如输入:广东-东莞-虎门,对应的输出时能输出:广东省 东莞市 虎门(镇/区) 这里涉及到的知识点即是将String转换为任 ...
- http状态--status[查询的资料备注]
HTTP 状态消息 当浏览器从 web 服务器请求服务时,可能会发生错误. 从而有可能会返回下面的一系列状态消息: 1xx: 信息 消息: 描述: 100 Continue 服务器仅接收到部分请求,但 ...
- 10个很棒的学习Android 开发的网站
1. Android Developers 作为一个Android开发者,官网的资料当然不可错过,从设计,培训,指南,文档,都不应该错过,在以后的学习过程中慢慢理解体会. 2. Android Gui ...