机器学习-Confusion Matrix混淆矩阵、ROC、AUC
本文整理了关于机器学习分类问题的评价指标——Confusion Matrix、ROC、AUC的概念以及理解。
混淆矩阵
在机器学习领域中,混淆矩阵(confusion matrix)是一种评价分类模型好坏的形象化展示工具。其中,矩阵的每一列表示的是模型预测的样本情况;矩阵的每一行表示的样本的真实情况。
举个经典的二分类例子: 混淆表格:
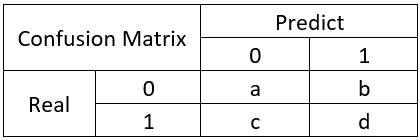

混淆矩阵是除了ROC曲线和AUC之外的另一个判断分类好坏程度的方法,通过混淆矩阵我们可以很清楚的看出每一类样本的识别正误情况。
混淆矩阵比模型的精度的评价指标更能够详细地反映出模型的”好坏”。模型的精度指标,在正负样本数量不均衡的情况下,会出现容易误导的结果。
基本概念
【1】True Positive
真正类(TP),样本的真实类别是正类,并且模型识别的结果也是正类。
【2】False Negative
假负类(FN),样本的真实类别是正类,但是模型将其识别成为负类。
【3】False Positive
假正类(FP),样本的真实类别是负类,但是模型将其识别成为正类。
【4】True Negative
真负类(TN),样本的真实类别是负类,并且模型将其识别成为负类。
评价指标(名词翻译来自机器学习实战)
【1】Accuracy(精确率)
模型的精度,即模型识别正确的个数 / 样本的总个数 。一般情况下,模型的精度越高,说明模型的效果越好。
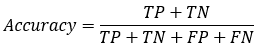
【2*】Precision(正确率)
又称为查准率,表示在模型识别为正类的样本中,真正为正类的样本所占的比例。 一般情况下,查准率越高,说明模型的效果越好。
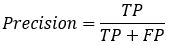
关于Accuracy(精确率)和Precision(正确率)的区别:
分类精确率(Accuracy),不管是哪个类别,只要预测正确,其数量都放在分子上,而分母是全部数据数量,这说明精确率是对全部数据的判断。
而正确率在分类中对应的是某个类别,分子是预测该类别正确的数量,分母是预测为该类别的全部数据的数量。
或者说,Accuracy是对分类器整体上的精确率的评价,而Precision是分类器预测为某一个类别的精确率的评价。
【3*】Recall(召回率)=Sensitivity(敏感指标,truepositive rate ,TPR)
=敏感性指标=查全率,表示的是,模型正确识别出为正类的样本的数量占总的正类样本数量的比值。 一般情况下,Recall越高,说明有更多的正类样本被模型预测正确,模型的效果越好。
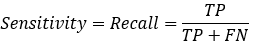
关于Precision(正确率)和Recall(召回率)的理解,套用网上的一个例子:
某池塘有1400条鲤鱼,300只虾,300只鳖。现在以捕鲤鱼为目的,撒一大网,逮着了700条鲤鱼,200只虾,100只鳖。那么,这些指标分别如下:
正确率 = 700 / (700 +200 + 100) = 70%
召回率 = 700 / 1400 =50%
正确率和召回率是一对矛盾的度量。以上面这个捕鱼的例子为例,如果希望将鲤鱼尽可能多地捕出来,可以用大网把池塘里的东西都捕出来,那么鲤鱼必然都被捕出来了,但这样正确率会很低。
希望补出的鲤鱼比例尽可能高,那么只捕最有把握的,这样就难免会漏掉一些鲤鱼,使得召回率较低。
通常只有在一些简单任务中,才可能使得正确率和召回率都很高。
【4】Specificity
特异性指标,表示的是模型识别为负类的样本的数量,占总的负类样本数量的比值。
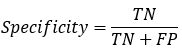
负正类率(false positive rate, FPR),计算公式为:FPR=FP/(TN+FP),计算的是模型错识别为正类的负类样本占所有负类样本的比例,一般越低越好。
Specificity = 1 - FPR
【5】Fβ_Score
Fβ的物理意义就是将正确率和召回率的一种加权平均,在合并的过程中,召回率的权重是正确率的β倍。
F1分数认为召回率和正确率同等重要,
F2分数认为召回率的重要程度是正确率的2倍,更看重recall,即看重模型对正样本的识别能力。
而F0.5分数认为召回率的重要程度是正确率的一半,更看重precision,即看重模型对负样本的区分能力。
分类阈值对Precision/Recall的影响:
做二值分类时,我们认为,若h(x)>=0.5,则predict=1;若h(x)<0.5,则predict=0。这里0.5就是分类阈值。
增加阈值,我们会对预测值更有信心,即增加了查准率。但这样会降低查全率。(High Precision, Low Recall)
减小阈值,则模型放过的真例就变少,查全率就增加。(Low Precision, High Recall)
实际应用:
(1)如果是做搜索,则要在保证召回率理想的情况下,提升准确率;
(2)如果做疾病监测、反垃圾,则是要保证准确率的条件下,提升召回率。
比较常用的是F1分数(F1 Score),是统计学中用来衡量二分类模型精确度的一种指标。
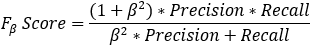
【6】F1_Score
数学定义:F1分数(F1_Score),又称为平衡F分数(BalancedScore),它被定义为正确率和召回率的调和平均数。
β=1的情况,F1-Score的值是从0到1的,1是最好,0是最差。
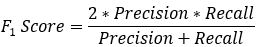
回到上面二分类的例子:
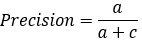
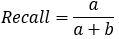
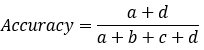
那么多分类呢?
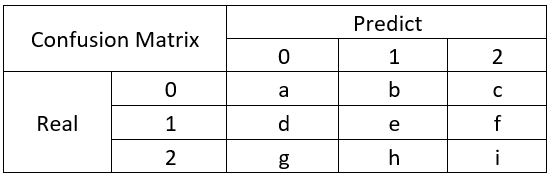
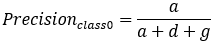
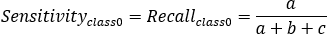
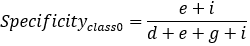
因此我们知道,计算Precision,Recall,Specificity等只是计算某一分类的特性,而Accuracy和F1-Score是判断分类模型总体的标准。
sklearn中 F1-micro 与 F1-macro区别和计算原理
在sklearn中的计算F1的函数为 f1_score ,其中有一个参数average用来控制F1的计算方式,今天我们就说说当参数取micro和macro时候的区别。
'micro':Calculate metrics globally by counting the total true positives, false negatives and false positives.'micro':通过先计算总体的TP,FN和FP的数量,再计算F1
'macro':Calculate metrics for each label, and find their unweighted mean. This does not take label imbalance into account.'macro':分布计算每个类别的F1,然后做平均(各类别F1的权重相同)
详见:https://www.cnblogs.com/techengin/p/8962024.html
ROC曲线
ROC曲线的横坐标是前文提到的FPR(false positive rate),纵坐标是TPR(truepositive rate,召回率)。
放在具体领域来理解上述两个指标。如在医学诊断中,判断有病的样本。
- 那么尽量把有病的揪出来是主要任务,也就是第二个指标TPR,要越高越好。
- 而把没病的样本误诊为有病的,也就是第一个指标FPR,要越低越好。
不难发现,这两个指标之间是相互制约的。如果某个医生对于有病的症状比较敏感,稍微的小症状都判断为有病,那么他的第一个指标应该会很高,但是第二个指标也就相应地变高。最极端的情况下,他把所有的样本都看做有病,那么第一个指标达到1,第二个指标也为1。
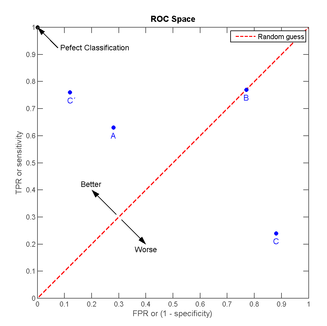
我们可以看出
- 左上角的点(TPR=1,FPR=0),为完美分类,也就是这个医生医术高明,诊断全对。
- 点A(TPR>FPR),医生A的判断大体是正确的。中线上的点B(TPR=FPR),也就是医生B全都是蒙的,蒙对一半,蒙错一半;下半平面的点C(TPR<FPR),这个医生说你有病,那么你很可能没有病,医生C的话我们要反着听,为真庸医。
- 曲线距离左上角越近,证明分类器效果越好。
为什么使用ROC曲线
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?
因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。
AUC值
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
- AUC = 1,是完美分类器,采用这个预测模型时,不管设定什么阈值都能得出完美预测。绝大多数预测的场合,不存在完美分类器。
- 0.5 < AUC < 1,优于随机猜测。这个分类器(模型)妥善设定阈值的话,能有预测价值。
- AUC = 0.5,跟随机猜测一样(例:丢铜板),模型没有预测价值。
- AUC < 0.5,比随机猜测还差;但只要总是反预测而行,就优于随机猜测。
计算AUC:
- 第一种方法:AUC为ROC曲线下的面积,那我们直接计算面积可得。面积为一个个小的梯形面积之和。计算的精度与阈值的精度有关。
- 第二种方法:根据AUC的物理意义,我们计算正样本score大于负样本的score的概率。取N*M(N为正样本数,M为负样本数)个二元组,比较score,最后得到AUC。时间复杂度为O(N*M)。
- 第三种方法:与第二种方法相似,直接计算正样本score大于负样本的概率。我们首先把所有样本按照score排序,依次用rank表示他们,如最大score的样本,rank=n(n=N+M),其次为n-1。那么对于正样本中rank最大的样本,rank_max,有M-1个其他正样本比他score小,那么就有(rank_max-1)-(M-1)个负样本比他score小。其次为(rank_second-1)-(M-2)。最后我们得到正样本大于负样本的概率为
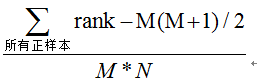
机器学习-Confusion Matrix混淆矩阵、ROC、AUC的更多相关文章
- ML01 机器学习后利用混淆矩阵Confusion matrix 进行结果分析
目标: 快速理解什么是混淆矩阵, 混淆矩阵是用来干嘛的. 首先理解什么是confusion matrix 看定义,在机器学习领域,混淆矩阵(confusion matrix),又称为可能性表格或是 ...
- 二分类算法的评价指标:准确率、精准率、召回率、混淆矩阵、AUC
评价指标是针对同样的数据,输入不同的算法,或者输入相同的算法但参数不同而给出这个算法或者参数好坏的定量指标. 以下为了方便讲解,都以二分类问题为前提进行介绍,其实多分类问题下这些概念都可以得到推广. ...
- 五分钟秒懂机器学习混淆矩阵、ROC和AUC
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第18篇文章,我们来看看机器学习领域当中,非常重要的其他几个指标. 混淆矩阵 在上一篇文章当中,我们在介绍召回率.准确率 ...
- 【机器学习】--模型评估指标之混淆矩阵,ROC曲线和AUC面积
一.前述 怎么样对训练出来的模型进行评估是有一定指标的,本文就相关指标做一个总结. 二.具体 1.混淆矩阵 混淆矩阵如图: 第一个参数true,false是指预测的正确性. 第二个参数true,p ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- 评估分类器性能的度量,像混淆矩阵、ROC、AUC等
评估分类器性能的度量,像混淆矩阵.ROC.AUC等 内容概要¶ 模型评估的目的及一般评估流程 分类准确率的用处及其限制 混淆矩阵(confusion matrix)是如何表示一个分类器的性能 混淆矩阵 ...
- 【分类模型评判指标 一】混淆矩阵(Confusion Matrix)
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80520839 略有改动,仅供个人学习使用 简介 混淆矩阵是ROC曲线绘制的基础 ...
- [机器学习]-分类问题常用评价指标、混淆矩阵及ROC曲线绘制方法
分类问题 分类问题是人工智能领域中最常见的一类问题之一,掌握合适的评价指标,对模型进行恰当的评价,是至关重要的. 同样地,分割问题是像素级别的分类,除了mAcc.mIoU之外,也可以采用分类问题的一些 ...
- 混淆矩阵(Confusion matrix)的原理及使用(scikit-learn 和 tensorflow)
原理 在机器学习中, 混淆矩阵是一个误差矩阵, 常用来可视化地评估监督学习算法的性能. 混淆矩阵大小为 (n_classes, n_classes) 的方阵, 其中 n_classes 表示类的数量. ...
随机推荐
- php文件上传错误信息
错误信息说明 UPLOAD_ERR_OK:其值为0,没有错误发生,文件上传成功 UPLOAD_ERR_INI_SIZE:其值为1,上传的文件超过了php.ini和upload_max_filesize ...
- sql server 完整备份、差异备份、事务日志备份
一. 理解: 完整备份为基础, 完整备份可以实物回滚还原,但是由于完整备份文件过大,对硬盘空间比较浪费这是就需要差异备份 或者 事务日志备份. 差异备份还原时,只能还原到备份的那个点, 日志备份还原时 ...
- 浅谈对js原型的理解
一. 在JavaScript中,一切皆对象,每个对象都有一个原型对象(prototype),而指向该原型对象的内部指针则是__proto__.当我们对对象进行for in 或者for of遍历时,就 ...
- Codeforces 1131 C. Birthday-暴力 (Codeforces Round #541 (Div. 2))
C. Birthday time limit per test 1 second memory limit per test 256 megabytes input standard input ou ...
- 转:攻击JavaWeb应用[9]-Server篇[2]
转:http://static.hx99.net/static/drops/papers-869.html 攻击JavaWeb应用[9]-Server篇[2] 园长 · 2014/01/22 12:5 ...
- CodeForces 738A Interview with Oleg
模拟. #pragma comment(linker, "/STACK:1024000000,1024000000") #include<cstdio> #includ ...
- Python中sorted函数的用法(转)
[Python] sorted函数 我们需要对List.Dict进行排序,Python提供了两个方法 对给定的List L进行排序, 方法1.用List的成员函数sort进行排序,在本地进行排序,不返 ...
- 【BZOJ 1053】 1053: [HAOI2007]反素数ant (反素数)
1053: [HAOI2007]反素数ant Description 对于任何正整数x,其约数的个数记作g(x).例如g(1)=1.g(6)=4.如果某个正整数x满足:g(x)>g(i) 0&l ...
- NOIP2005 day1 t1 谁拿了最多奖学金
题目描述 某校的惯例是在每学期的期末考试之后发放奖学金.发放的奖学金共有五种,获取的条件各自不同: 1) 院士奖学金,每人8000元,期末平均成绩高于80分(>80),并且在本学期内发表1篇或1 ...
- 【分块】【暴力】XVII Open Cup named after E.V. Pankratiev Grand Prix of Moscow Workshops, Sunday, April 23, 2017 Problem I. Rage Minimum Query
1000w的数组,一开始都是2^31-1,然后经过5*10^7次随机位置的随机修改,问你每次的全局最小值. 有效的随机修改的期望次数很少,只有当修改到的位置恰好是当前最小值的位置时才需要扫一下更新最小 ...