Hadoop实战之三~ Hello World
本文介绍的是在Ubuntu下安装用三台PC安装完成Hadoop集群并运行好第一个Hello World的过程,软硬件信息如下:
Ubuntu:12.04 LTS
Master: 1.5G RAM,奔腾处理器。
Slave1、Slave2:4G RAM,I3处理器。
开始
1 安装Ubuntu : http://cdimage.ubuntu.com/releases/12.04/release/,Ubuntu的安装过程网上有很多,这里不再赘述了,安装之前一定要对Linux的目录树和Mount有所了解。另外i,安装Ubutu过程中,三个用户名必须是一样的,当然你后面建用户也行,但是不方便。另外OpenSSH一定要先装好。
2 安装好后,开启root:
sudo passwd root
sudo passwd -u root
3 开始安装jdk 1.6 ,下载地址 http://www.oracle.com/technetwork/java/javase/downloads/java-se-6u24-download-338091.html:
使用终端进入存放jdk-6u24-linux-i586.bin,我的位置是:/usr/lib。我推荐的终端软件为:XShell和XFTP。存放后后:
第一步:更改权限;默认文件没有可执行权限
chmod g+x jdk-6u24-linux-i586.bin
第二步: 安装
sudo -s ./jdk-6u24-linux-i586.bin
安装完毕,下面配置环境变量
我安装好后java的路径是:/usr/lib/jdk1.6.0_24
配置classpath,修改所有用户的环境变量:
sudo vi /etc/profile
在文件最后添加
#set java environment
export JAVA_HOME=/usr/lib/jdk1..0_24
export JRE_HOME=/usr/lib/jdk1..0_24/jre
export CLASSPATH=.:$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
如果使用sudo提示不在用户组中 则敲命令 su - ,切换到root,继续敲 visudo ,然后
在root ALL=(ALL:ALL) ALL下
添加
hadoop ALL=(ALL:ALL) ALL (ps:hadoop是我建的用户名。)
重新启动计算机,用命令测试jdk的版本
java -version
显示如下信息:成功安装
java version "1.6.0_12"
Java(TM) SE Runtime Environment (build 1.6.0_12-b04)
Java HotSpot(TM) Server VM (build 11.2-b01, mixed mode)
5 hadoop安装和运行
下载地址:http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-1.2.1/
存放目录:/home/hadoop(hadoop是用户名)
解压: tar -zxvf hadoop-1.2.1.tar.gz
6 Hadoop集群配置:
1 修改三台主机的hosts文件 :
vi /etc/hosts
加入如下四行,分别修改为你的master机器和slave机器的ip地址即可
127.0.0.1 localhost
192.168.1.1 master
192.168.1.2 slave1
192.168.1.3 slave2
2 修改主机名 vi /etc/hostname
各自改为master,slave1,slave2.
3 配置master免SSH登录slave
在master上生成密钥:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
然后用xftp将~/.ssh文件下的所有文件拷贝到两台slave机器即可。然后输入命令。
cd ~/.ssh
scp authorized_keys slave1:~/.ssh/
scp authorized_keys slave2:~/.ssh/
4 修改三台主机的配置文件
vi /home/hadoop/hadoop-1.2./conf/hadoop-env.sh
加入:export JAVA_HOME=/usr/lib/jdk1.6.0_24 (更改为你们自己的目录)
vi /home/hadoop/hadoop-1.2./conf/core-site.xml
加入:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
</configuration>
继续:
vi /home/hadoop/hadoop-1.2./conf/hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value></value>
</property>
</configuration>
继续:
vi /home/hadoop/hadoop-1.2./conf/mapred-site.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>master:</value>
</property>
</configuration>
在master机器上修改:
vi /home/hadoop/hadoop-1.2./conf/masters
加入master
vi /home/hadoop/hadoop-1.2./conf/slaves
加入
slave1
slave2
5 启动hadoop:
cd /home/hadoop/hadoop-1.2.
bin/hadoop namenode -format --这里是格式化 一次即可
bin/start-all.sh

6 Hello World-经典的wordcount程序
cd ~
mkdir file
cd file
echo "Hello World" > file1.txt
echo "Hello Hadoop" > file2.txt
cd /home/hadoop/hadoop-1.2.
bin/hadoop fs -mkdir input
bin/hadoop fs -ls
bin/hadoop fs -put ~/file/file*.txt input
bin/hadoop fs -ls input
bin/hadoop jar ./hadoop-examples-1.2..jar wordcount input output

查看输出结果:
bin/hadoop fs -ls output

查看最终结果:

可见,wordCount程序运行完成了。详细执行步骤如下:
1)将文件拆分成splits,由于测试用的文件较小,所以每个文件为一个split,并将文件按行分割形成<key,value>对,如图4-1所示。这一步由MapReduce框架自动完成,其中偏移量(即key值)包括了回车所占的字符数(Windows和Linux环境会不同)。

图4-1 分割过程
2)将分割好的<key,value>对交给用户定义的map方法进行处理,生成新的<key,value>对,如图4-2所示。
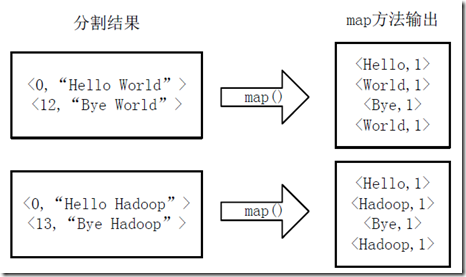
图4-2 执行map方法
3)得到map方法输出的<key,value>对后,Mapper会将它们按照key值进行排序,并执行Combine过程,将key至相同value值累加,得到Mapper的最终输出结果。如图4-3所示。

图4-3 Map端排序及Combine过程
4)Reducer先对从Mapper接收的数据进行排序,再交由用户自定义的reduce方法进行处理,得到新的<key,value>对,并作为WordCount的输出结果,如图4-4所示。
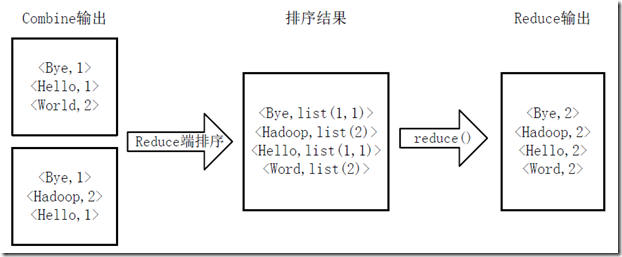
图4-4 Reduce端排序及输出结果
这一块:更详细的介绍可以参考:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html
该文是对《Hadoop实战》最佳阐述。
后记
搭建Hadoop集群网上的文章有很多,遇到问题不断的查找,最终总是可以解决问题的。感觉最繁碎的问题是权限,我后面一概就用root了。改起来烦。然,搭建完一个hadoop根本不算什么。搞懂hadoop适合的业务情形,搞懂Hadoop的设计思想,在写自己程序时,可以灵活运用,达到它山之石可以攻玉的效果,那才是学习Hadoop的最终目的。
Hadoop实战之三~ Hello World的更多相关文章
- 王家林的“云计算分布式大数据Hadoop实战高手之路---从零开始”的第十一讲Hadoop图文训练课程:MapReduce的原理机制和流程图剖析
这一讲我们主要剖析MapReduce的原理机制和流程. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发 ...
- 云计算分布式大数据Hadoop实战高手之路第七讲Hadoop图文训练课程:通过HDFS的心跳来测试replication具体的工作机制和流程
这一讲主要深入使用HDFS命令行工具操作Hadoop分布式集群,主要是通过实验的配置hdfs-site.xml文件的心跳来测试replication具体的工作和流程. 通过HDFS的心跳来测试repl ...
- Hadoop on Mac with IntelliJ IDEA - 10 陆喜恒. Hadoop实战(第2版)6.4.1(Shuffle和排序)Map端 内容整理
下午对着源码看陆喜恒. Hadoop实战(第2版)6.4.1 (Shuffle和排序)Map端,发现与Hadoop 1.2.1的源码有些出入.下面作个简单的记录,方便起见,引用自书本的语句都用斜体表 ...
- 云计算分布式大数据Hadoop实战高手之路第八讲Hadoop图文训练课程:Hadoop文件系统的操作实战
本讲通过实验的方式讲解Hadoop文件系统的操作. “云计算分布式大数据Hadoop实战高手之路”之完整发布目录 云计算分布式大数据实战技术Hadoop交流群:312494188,每天都会在群中发布云 ...
- Hadoop实战实例
Hadoop实战实例 Hadoop实战实例 Hadoop 是Google MapReduce的一个Java实现.MapReduce是一种简化的分布式编程模式,让程序自动分布 ...
- 升级版:深入浅出Hadoop实战开发(云存储、MapReduce、HBase实战微博、Hive应用、Storm应用)
Hadoop是一个分布式系统基础架构,由Apache基金会开发.用户可以在不了解分布式底层细节的情况下,开发分布式程序.充分利用集群的威力高速运算和存储.Hadoop实现了一个分布式文件系 ...
- [原创].NET 分布式架构开发实战之三 数据访问深入一点的思考
原文:[原创].NET 分布式架构开发实战之三 数据访问深入一点的思考 .NET 分布式架构开发实战之三 数据访问深入一点的思考 前言:首先,感谢园子里的朋友对文章的支持,感谢大家,希望本系列的文章能 ...
- hadoop基础----hadoop实战(七)-----hadoop管理工具---使用Cloudera Manager安装Hadoop---Cloudera Manager和CDH5.8离线安装
hadoop基础----hadoop实战(六)-----hadoop管理工具---Cloudera Manager---CDH介绍 简介 我们在上篇文章中已经了解了CDH,为了后续的学习,我们本章就来 ...
- [Java聊天室server]实战之三 接收循环
前言 学习不论什么一个稍有难度的技术,要对其有充分理性的分析,之后果断做出决定---->也就是人们常说的"多谋善断":本系列尽管涉及的是socket相关的知识.但学习之前,更 ...
随机推荐
- CentOS加入Windows域
CentOS加入Windows域,为减少操作已经提前关掉了selinux,防火墙.并且更改了主机名 yum install nss-pam-ldapd -y 第一步:更改主机名为linux.itxd ...
- ArchLinux 下安装 SecureCRT
相关说明: 上篇发了个Linux(Ubuntu) 下 SecureCRT 7 30天循环破解在启动的时候会多输入一次确认窗口, 后来maz-1网友留言说可以用Windows破解后程序替换Linux下的 ...
- ArchLinux pacman 提高俩倍下载速度方法
pacman能够调用外部下载工具来代替默认的wget来给pacman提速 比如将/etc/pacman.conf中 XferCommand = /usr/bin/wget –passive-ftp - ...
- 发布 Android Library 到 JCenter 从入门到放弃
最近想倒腾一个小小的 UIKit 到 JCenter,为开源社区贡献一点绵薄之力,于是就有了一系列惨无人道的踩坑史.好,接下来,直奔主题,以下是发布流程. 发布到 JCenter 发布到 JCente ...
- 全局CSS的配置
/*公共部分开始*/ ::selection{ background-color: #3095fb; color: white; } ::moz-selection{ background-color ...
- ajax跨域请求问题
ajax是不允许跨域请求的,今天在使用bootstap-table的时候,data-url使用的地址是绝对地址,而非相对地址,因此在载入数据的时候就出错了. 启动的时候使用是 http://127.0 ...
- Machine learning吴恩达第三周 Logistic Regression
1. Sigmoid function function g = sigmoid(z) %SIGMOID Compute sigmoid function % g = SIGMOID(z) compu ...
- 关于JAVA泛型中的通配符类型
之前对JAVA一知半解时就拿起weiss的数据结构开始看,大部分数据结构实现都是采取通配符的思想,好处不言而喻. 首先建立两个类employee和manager,继承关系如下.其次Pair类是一个简单 ...
- AS添加依赖库提示Manifest merger failed解决办法
今天在学习<Android权威编程指南>时 在project structure中添加recyclerview时提示错误 按照提示添加tools:replace标签还是报错 然后切换至bu ...
- 2018牛客多校1 - J Different Integers 莫队/主席树签到
题意:给出n<5e4,a[1...n],单次1e5总次1e6次查询除去区间(L,R)的数的个数 开场5分钟:莫队是不可能莫队的,这道题是不可能莫队的 最后1小时:真香 具体操作没啥特别的,注意一 ...