一篇文章学会spark-streaming
版权申明:转载请注明出处。
文章来源:bigdataer.net
1.什么是spark-streaming?
实际生产中会有许多应用到实时处理的场景,比如:实时监测页面点击,实时监测系统异常,实时监测来自于外部的攻击。针对这些场景,twitter研发了实时数据处理工具storm,并在后来开源。spark针对这些场景设计了spark-streaming实时计算模型,它允许用户使用一系列批处理的API去处理实时数据,能做到代码逻辑的重复使用。
和spark中的rdd非常相似,spark-streaming中使用离散化流(discretized stream)作为抽象的表示,叫做DStream。它是随时间推移而收集数据的序列,每个时间段收集到的数据在DStream内部以一个RDD的形式存在。DStream支持从kafka,flume,hdfs,s3等获取输入。DStream也支持两种操作,即转化操作和输出操作(区别于RDD中的行动操作)。转化操作又分为无状态的转化操作和有状态的转化操作,无状态的转化操作有map,filter,flatmap,repartition等,是针对单个时间区间内的操作。而有状态的转化操作可以针对不同的时间区间,后面详述。
2.两个简单的例子
2.1 监听socket获取数据,代码如下:
这里使用nc -lk 9999 在ip为10.121.33.44的机器上发送消息
object SocketStream {
def main(args: Array[String]): Unit = {
//本地测试,设置4核
val conf = new SparkConf().setMaster("local[4]").setAppName("streaming")
//以10秒为一个批次
val ssc = new StreamingContext(conf,Seconds(10))
//接收消息
val dstream = ssc.socketTextStream("10.121.33.44",9999,StorageLevel.MEMORY_AND_DISK_SER)
//监测关键字error,出现则print
dstream.filter(_.contains("error")).foreachRDD(rdd=>{
rdd.foreach(println(_))
})
ssc.start()
ssc.awaitTermination()
}
}
2.2 从kafka读取数据,比较常用
object KafkaStream {
def main(args: Array[String]): Unit = {
//本地测试,设置4核
val conf = new SparkConf().setMaster("local[4]").setAppName("streaming")
//以10秒为一个批次
val ssc = new StreamingContext(conf,Seconds(10))
val zkQuorum = "10.22.33.44:6688,10.22.33.45:6688/kafka_cluster"
val group_id = "realtime_data"
//kafka相关参数
val kafka_param = Map[String,String](
"zookeeper.connect" ->zkQuorum,
"group.id" -> group_id,
"zookeeper.connection.timeout.ms" -> "10000",
"fetch.message.max.bytes" -> "10485760"
)
val topic = Map[String,Int]("test_topic" -> 16)
//接收消息
val dstream = KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](ssc,kafka_param,topic,StorageLevel.MEMORY_AND_DISK_SER).map(_._2)
//监测关键字error,出现则print
dstream.filter(_.contains("error")).foreachRDD(rdd=>{
rdd.foreach(println(_))
})
ssc.start()
ssc.awaitTermination()
}
}
3.再来谈架构
通过上面两个例子,你可能对spark-streaming有了初步的了解,我们再来看一下它的架构。
Spark-streaming使用"微批次"的架构,把流式计算当做一系列微型的批处理操作来对待,每个时间段都产生一个RDD。如图:
作用于一个DStream上的无状态转化操作会对它其中的每个RDD生效,如针对一个输入为语句的DStream做flatMap操作的示意图如下: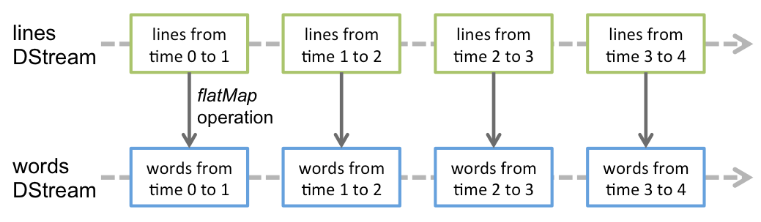
4.转化操作
4.1 无状态的转化操作。
无状态转化操作就是简单的将转化作用于DStream的每个RDD上面。下面列举了一些常见的转化操作,其中最后一个transform表示可以试用自定义的转化函数,尽管它前面已经提供了很多现成的API。
4.2有状态的转化操作。
有状态的转化操作是跨时间段的数据操作,一些先前的批次也被用来在新的批次中做计算。主要有滑动窗口和updateStateByKey。前者以一个时间段为滑动窗口进行操作,后者则用来跟踪每个键的状态变化。有状态的转化操作需要打开检查点机制来保证容错性。即:给ssc.checkpoint()设置一个检查点目录。
(1)基于窗口的转化操作会在一个比ssc设置的更长的时间段内,通过整合多个批次的,计算出整个大的时间窗口的结果。基于窗口的操作需要两个参数,一个是窗口时长,一个是滑动步长。这两个参数是ssc设置的时长的整数倍。下面的图表示了一个时间窗口为3,滑动步长为2的窗口转化操作。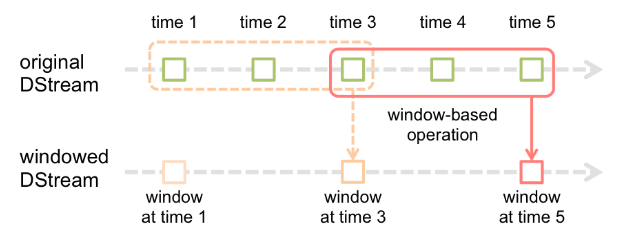
前面提到的监测关键字error的例子,现在需要每隔20s就对前面30s有error的日志记录做计数,代码如下:
object KafkaStream {
def main(args: Array[String]): Unit = {
//本地测试,设置4核
val conf = new SparkConf().setMaster("local[4]").setAppName("streaming")
//以10秒为一个批次
val ssc = new StreamingContext(conf,Seconds(10))
val zkQuorum = "10.22.33.44:6688,10.22.33.45:6688/kafka_cluster"
val group_id = "realtime_data"
//kafka相关参数
val kafka_param = Map[String,String](
"zookeeper.connect" ->zkQuorum,
"group.id" -> group_id,
"zookeeper.connection.timeout.ms" -> "10000",
"fetch.message.max.bytes" -> "10485760"
)
val topic = Map[String,Int]("test_topic" -> 16)
//接收消息
val dstream = KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](ssc,kafka_param,topic,StorageLevel.MEMORY_AND_DISK_SER)
.map(_._2)
//每隔20s对前30s出现error的日志做计数
val errors = dstream.window(Seconds(30),Seconds(20))
.filter(_.contains("error"))
.count()
errors.foreachRDD(rdd=>{
rdd.foreach(println(_))
})
ssc.start()
ssc.awaitTermination()
}
}
(2)updateStateByKey
updateStateByKey能对键值对的数据进行不同批次间的数据计算,使用updateStateByKey,需要传入一个update函数,这个函数接收某个key最新批次对应的values,以及该key之前对应的value,按照自定义的逻辑返回一个新的value。如需要计算一个实时日志中http响应码的计数,代码如下:
object KafkaStream {
def main(args: Array[String]): Unit = {
//输出目录
val output = args(0)
//本地测试,设置4核
val conf = new SparkConf().setMaster("local[4]").setAppName("streaming")
//以10秒为一个批次
val ssc = new StreamingContext(conf,Seconds(10))
val zkQuorum = "10.22.33.44:6688,10.22.33.45:6688/kafka_cluster"
val group_id = "realtime_data"
//kafka相关参数
val kafka_param = Map[String,String](
"zookeeper.connect" ->zkQuorum,
"group.id" -> group_id,
"zookeeper.connection.timeout.ms" -> "10000",
"fetch.message.max.bytes" -> "10485760"
)
val topic = Map[String,Int]("test_topic" -> 16)
//接收消息
val dstream = KafkaUtils.createStream[String,String,StringDecoder,StringDecoder](ssc,kafka_param,topic,StorageLevel.MEMORY_AND_DISK_SER).map(_._2)
val rdd = dstream.map(_.split("\001"))
.map(x=>(x(0),x(1).toLong))
.updateStateByKey(update)
//输出
rdd.foreachRDD(_.saveAsTextFile(output))
ssc.start()
ssc.awaitTermination()
}
//update函数
def update(new_values:Seq[Long],old_value:Option[Long]):Option[Long]={
val current_num = new_values.size
val result_num = current_num + old_value.getOrElse(0L)
Some(result_num)
}
}
(3)所有有状态转化操作
5.输出操作
输出操作比较简单,有以下几种:
6.作业稳定性
spark-streaming作业一般都要全天候不间断运行,那么作业的稳定性如何保证?主要有以下几点:
6.1 检查点机制。
其原理就是阶段性的将作业运行的数据存放到存储系统,如hdfs,s3等。当作业运行出现异常时可以从上述数据中恢复。
6.2 驱动器容错。
在创建实时计算作业的上下文时使用getOrCreate函数。代码如下:
val ssc = StreamingContext.getOrCreate(cp_dir,createContext )
def createContext(): StreamingContext ={
val sc = new SparkContext(conf)
val ssc = new StreamingContext(sc,Seconds(10))
ssc.checkpoint(cp_dir)
}
更多文章请关注微信公众号:bigdataer
一篇文章学会spark-streaming的更多相关文章
- 【干货】一篇文章学会Gulp(Getting started with Gulp)
抛开Grunt,又有一个新的自动化构建系统成为新的领跑者.那就是Gulp. Gulp是一种直观.自动化构建的工具. 为什么前端er会这么感兴趣Gulp?我相信大家都有个思想:要么不做事,要做事就要把事 ...
- 一篇文章学会Spring4.0
spring概述 spring 是一个开源框架. Spring 为简化企业级应用开发而生. 使用 Spring 可以使简单的 JavaBean 实现以前只有 EJB 才能实现的功能. Spring 是 ...
- 一篇文章学会springMVC(转)
说在前面 本文只是入门 为什么用springMVC?springMVC有什么有缺点?springMVC和Struts有什么区别?等等这些问题可以参考网路上资源,本文的重点是快速带入,让大家了解熟悉sp ...
- 一篇文章学会shell工具篇之sed
sed工具执行原理; 有关sed的参数及action的常见操作方法; 定址; 模式空间和保持空间; 使用标签 1.首先先来了解一下什么是sed? sed叫做流编辑器,在shell脚本和Makefile ...
- 一篇文章学会Docker命令
目录 简介 镜像仓库 login pull push search 本地镜像管理 images rmi tag build history save load import 容器操作 ps inspe ...
- 一篇文章学会shell脚本
一.Shell传递参数 #!/bin/bash # 假设在脚本运行时写了三个参数 ..,,则 "(传递了三个参数). echo "-- \$* 演示 --" for i ...
- 大数据技术之_19_Spark学习_04_Spark Streaming 应用解析 + Spark Streaming 概述、运行、解析 + DStream 的输入、转换、输出 + 优化
第1章 Spark Streaming 概述1.1 什么是 Spark Streaming1.2 为什么要学习 Spark Streaming1.3 Spark 与 Storm 的对比第2章 运行 S ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记十之铭文升级版
铭文一级: 第八章:Spark Streaming进阶与案例实战 updateStateByKey算子需求:统计到目前为止累积出现的单词的个数(需要保持住以前的状态) java.lang.Illega ...
- 【慕课网实战】Spark Streaming实时流处理项目实战笔记九之铭文升级版
铭文一级: 核心概念:StreamingContext def this(sparkContext: SparkContext, batchDuration: Duration) = { this(s ...
随机推荐
- NavigationBar 背景颜色,字体颜色
// 设置状态栏颜色 [application setStatusBarStyle:UIStatusBarStyleLightContent]; // 设置导航栏 [[UINavigationBar ...
- Vue入门之旅:一报错 Unknown ... make sure to provide the "name" option及error compiling template
报错一: Unknown custom element: <custom-select> - did you register the component correctly? For r ...
- EXCEL自动导出HTML
话说博主我以前总是为资料共享的问题发愁,刚才鼓捣了一下EXCEL.发现有个功能还是不错的'发布' 以OFFICE2013为标准吧. 点击文件--导出-- 更改文件类型---另存为--(网页)htm 点 ...
- JAVA源码之JDK(三)——String、StringBuffer、StrinBuilder
Java中,除了8种基本类型,最长用的应该就是String类了.那么我们来看看JDK中的源码是怎么建造String.StringBuffer.StrinBuilder一系列类的. java.lang. ...
- Python SQLAlchemy基本操作和常用技巧
转自:https://www.jb51.net/article/49789.htm 首先说下,由于最新的 0.8 版还是开发版本,因此我使用的是 0.79 版,API 也许会有些不同.因为我是搭配 M ...
- DOM 综合练习(一)
// 练习一: 完成一个好友列表的展开闭合效果 <html> <head> <style type="text/css"> // 对表格中的 u ...
- 解决: ./netapp.bin: error while loading shared libraries: libcaffe.so.1.0.0: cannot open shared object file: No such file or directory 运行时报错(caffe)
caffe安装好后lib没有配置到/usr/lib或/usr/local/lib中,需手动配置: export LD_LIBRARY_PATH=/path_to_your_caffe/build/li ...
- 利用jdt快速实现pmd的功能
jdt可以做语法树分析,并且支持visitor模式对代码进行分析.跟pmd的分析方式一样,我们只要实现 visitor接口即可实现一个插件. @Service("requestMapping ...
- 002-使用java类调用quartz
一.工具类 package com.tech.jin.jobScheduler; import java.text.ParseException; import java.util.ArrayList ...
- Django-进阶之路--信号
Model 到目前为止,当我们的程序涉及到数据库相关操作时,我们一般都会这么搞: 创建数据库,设计表结构和字段 使用 MySQLdb 来连接数据库,并编写数据访问层代码 业务逻辑层去调用数据访问层执行 ...