【Machine Learning】如何处理机器学习中的非均衡数据集?

- 过采样 Over-sampling
- 下采样 Under-sampling
- 上采样与下采样结合
- 集成采样 Ensemble sampling
- 代价敏感学习 Cost-Sensitive Learning
过采样 Over-sampling

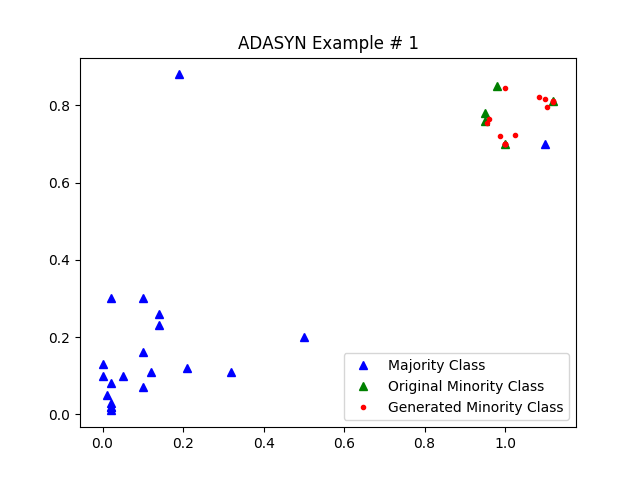
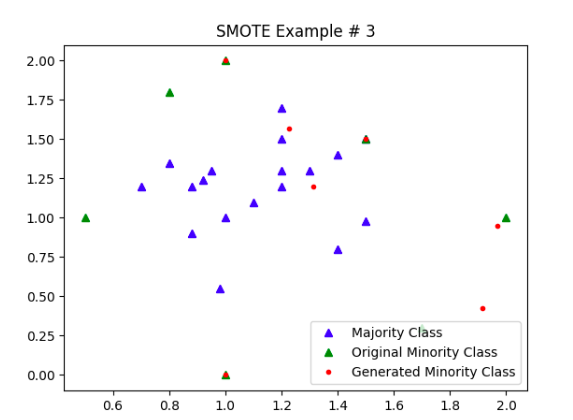
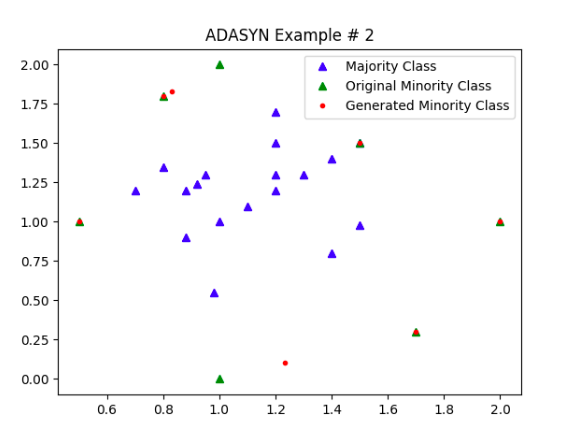
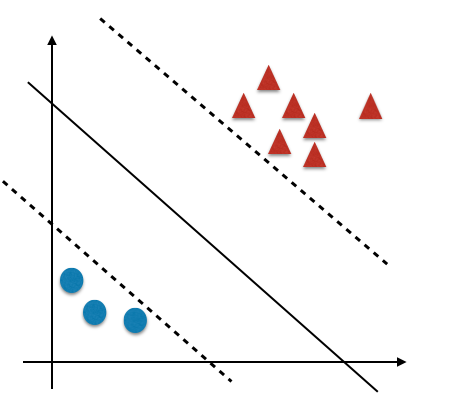
下采样 Under-sampling
- Tomek links
- One-sided selection: Addressing the curse of imbalanced training sets: One-sided selection
- Neighboorhood Cleaning Rule: Improving identification of difficult small classes by balancing class distribution
上采样与下采样结合
集成采样 Ensemble sampling
代价敏感学习 Cost-Sensitive Learning

【Machine Learning】如何处理机器学习中的非均衡数据集?的更多相关文章
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- 【Machine Learning】机器学习及其基础概念简介
机器学习及其基础概念简介 作者:白宁超 2016年12月23日21:24:51 摘要:随着机器学习和深度学习的热潮,各种图书层出不穷.然而多数是基础理论知识介绍,缺乏实现的深入理解.本系列文章是作者结 ...
- 【Machine Learning】机器学习の特征
绘制了一张导图,有不对的地方欢迎指正: 下载地址 机器学习中,特征是很关键的.其中包括,特征的提取和特征的选择.他们是降维的两种方法,但又有所不同: 特征抽取(Feature Extraction): ...
- 人工智能(Machine Learning)—— 机器学习
https://blog.csdn.net/luyao_cxy/article/details/82383091 转载:https://blog.csdn.net/qq_27297393/articl ...
- 機器學習基石(Machine Learning Foundations) 机器学习基石 课后习题链接汇总
大家好,我是Mac Jiang,非常高兴您能在百忙之中阅读我的博客!这个专题我主要讲的是Coursera-台湾大学-機器學習基石(Machine Learning Foundations)的课后习题解 ...
- 機器學習基石(Machine Learning Foundations) 机器学习基石 作业三 课后习题解答
今天和大家分享coursera-NTU-機器學習基石(Machine Learning Foundations)-作业三的习题解答.笔者在做这些题目时遇到非常多困难,当我在网上寻找答案时却找不到,而林 ...
- 機器學習基石(Machine Learning Foundations) 机器学习基石 作业四 Q13-20 MATLAB实现
大家好,我是Mac Jiang,今天和大家分享Coursera-NTU-機器學習基石(Machine Learning Foundations)-作业四 Q13-20的MATLAB实现. 曾经的代码都 ...
- [Machine Learning] 深度学习中消失的梯度
好久没有更新blog了,最近抽时间看了Nielsen的<Neural Networks and Deep Learning>感觉小有收获,分享给大家. 了解深度学习的同学可能知道,目前深度 ...
- 《Hands-On Machine Learning with Scikit-Learn&TensorFlow》mnist数据集错误及解决方案
最近在看这本书看到Chapter 3.Classification,是关于mnist数据集的分类,里面有个代码是 from sklearn.datasets import fetch_mldata m ...
随机推荐
- Window系统Oracle 安装
一:安装Oracle 数据库软件 1.先去官网下载所需文件:http://www.oracle.com/technetwork/database/enterprise-edition/download ...
- 常用Sql server 自定义函数
/****** 对象: UserDefinedFunction [dbo].[fun_get_LowerFirst] 脚本日期: 08/04/2012 13:03:56 ******/ IF EXIS ...
- 不用注解,获取spring容器里的bean(ApplicaitonContext)
以静态变量保存Spring ApplicationContext, 可在任何代码任何地方任何时候取出ApplicaitonContext. 使用方法:SpringContextHolder.getBe ...
- linux系统的介绍与环境搭建准备38-40
操作系统(OS):用于控制管理计算机,形成在用户和机器之间传递信息的系统软件 linux是什么? <--unix系统是linux的前身---> 特点: 开放的源代码,自由修改 自由传播,没 ...
- 在SQL Server中批量修改有规律列的定义
)=N'要修改的表名'; --修改所有以sl结尾的列名的小数位数为4位 select syscolumns.name into #t1 from syscolumns,systypes where s ...
- 【Hadoop故障处理】全分布下,DataNode进程正常启动,但是网页上不显示,并且DataNode节点为空
[故障背景] DataNode进程正常启动,但是网页上不显示,并且DataNode节点为空. /etc/hosts 的ip和hostname配置正常,各个机器之间能够ping通. [日志错误信息] ...
- BZOJ1011 莫比乌斯反演(基础题
[题目链接] http://www.lydsy.com/JudgeOnline/problem.php?id=1101 [题目大意] 求[1,n][1,m]内gcd=k的情况 [题解] 考虑求[1,n ...
- C# 获取UTC 转换时间戳为C#时间
获取UTC /// <summary> /// 获取时间戳 /// </summary> /// <returns>UTC</returns> publ ...
- 数据结构之栈和队列及其Java实现
栈和队列是数据结构中非常常见和基础的线性表,在某些场合栈和队列使用很多,因此本篇主要介绍栈和队列,并用Java实现基本的栈和队列,同时用栈和队列相互实现. 栈:栈是一种基于“后进先出”策略的线性表.在 ...
- lvs健康检查脚本第三版
如下是学习完马哥视频lvs后改写的健康检查脚本第三版.利用工作之余三四个小时时间才把整个逻辑搞清楚,有时候自己都有点蒙圈,尤其是在写到while循环的时候.总的来说非常感谢马哥的慷慨解囊!脚本原稿及思 ...