ssd算法论文理解
这篇博客主要是讲下我在阅读ssd论文时对论文的理解,并且自行使用pytorch实现了下论文的内容,并测试可以用。
开篇放下论文地址https://arxiv.org/abs/1512.02325,可以自行参考论文。
接着放下我使用pytorch复现的版本地址https://github.com/acm5656/ssd_pytorch,如果这篇博客或者代码有帮到你,麻烦给个星哈。
代码解读的博客链接如下https://www.cnblogs.com/cmai/p/10080005.html,欢迎大家前来阅读。
模型图
首先来介绍下ssd模型:
模型图如下:

在图中,我们可以大概看下模型的结构,前半部分是vgg-16的架构,作者在vgg-16的层次上,将vgg-16后边两层的全连接层(fc6,fc7)变换为了卷积层,conv7之后的层则是作者自己添加的识别层。
我们可以在模型图中观察到在conv4_3层,有一层Classifier层,使用一层(3,3,(4*(Classes+4)))卷积进行卷积(Classes是识别的物体的种类数,代表的是每一个物体的得分,4为x,y,w,h坐标,乘号前边的4为default box的数量),这一层的卷积则是提取出feature map,什么是feature map呢,我们在下文会介绍,这时候我们只需要简单的了解下。不仅在conv4_3这有一层卷积,在Conv7、Conv8_2、Conv9_2、Conv10_2和Conv11_2都有一层这样的卷积层,因此最后提取到6个feature map层。那么细心的小伙伴会发现,最后的Detections:8732 per Class是怎么算出来的呢?具体的计算如下:
Conv4_3 得到的feature map大小为38*38:38*38*4 = 5776
Conv7 得到的feature map大小为19*19:19*19*6 = 2166
Conv8_2 得到的feature map大小为10*10:10*10*6 = 600
Conv9_2 得到的feature map大小为5 * 5 :5 * 5 * 6 = 150
Conv10_2得到的feature map大小为3 * 3 :3 * 3 * 4 = 36
Conv11_2得到的feature map大小为1 * 1 :1 * 1 * 4 = 4
最后结果为:8732
这时候会有小伙伴会疑惑,为什么要乘以4或者6,这个是default box数量,这个会在下文将feature map时介绍到。
那么ssd则是在这8732个结果中找到识别的物体。
default box 和 feature map
讲完模型图,这就来填之前的留下的两个坑,什么是feature map和default box呢?
先看下论文中的图
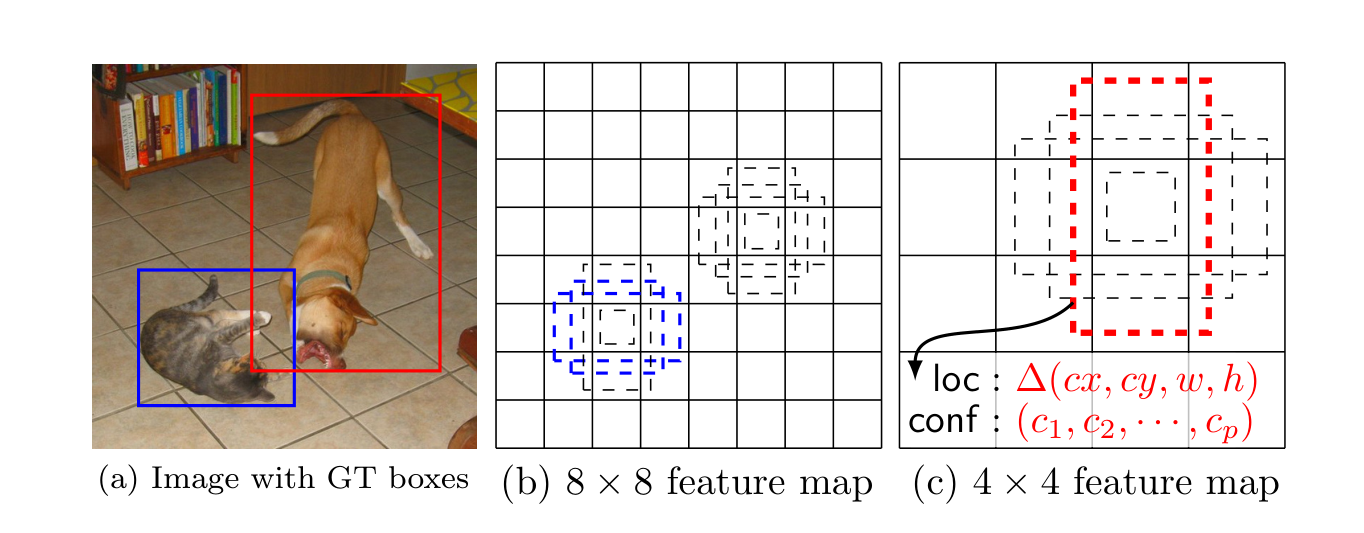
feature map则是刚才指的Classifier产生的结果,如图(b)和(c) b是大小8*8的feature map,c是大小4*4的feature map,其中每一个小个子都包含多个box,同时每个box对应loc(位置坐标)和conf(每个种类的得分),default box长宽比例默认有四个和六个,四个default box是长宽比为(1:1)、(2:1)、(1:2)、(1:1)这四个,六个则是添加了(1:3)、(3:1)这两个,这时候有小伙伴会问,为什么会有两个(1:1)呢。这时候就要讲下论文中Choosing scales and aspect ratios for default boxes这段内容了。作者认为不同的feature map应该有不同的比例,这是什么意思呢,代表的是default box中这个1在原图中的尺寸是多大的,计算公式如下所示:

公式Sk即代表在300*300输入中的比例,m为当前的feature map是第几层,k代表的是一共有多少层的feature map,Smin和Smax代表的是第一层和最后一层所占的比例,在ssd300中为0.2-0.9。那么S怎么用呢,作者给出的计算方法是,wk = Sk√ar,hk = Sk / √ar,其中ar代表的是之前提到的default box比例,即(1,2,3,1/2,1/3),对于default box中心点的值取值为((i+0.5) / |fk|,(j+0.5)/|fk|),其中i,j代表在feature map中的水平和垂直的第几格,fk代表的是feature map的size。那么重点来了,还记得之前有一个小疑问,为什么default box的size有两个1吗?作者在这有引入了一个Sk' = √Sk*Sk+1,多出来的那个1则是通过使用这个Sk'来计算的,有的小伙伴可能会有疑问,这有了k+1则需要多出来一部分的Sk啊,是的没错,作者的代码中就添加了两层,第一层取0.1,最后一层取1。到这位置,基本上模型和default box是解释清楚了。
损失函数
讲完之前的所有内容,模型我们大概都有了了解,最后则是损失函数部分了。先放出来论文中的损失函数。
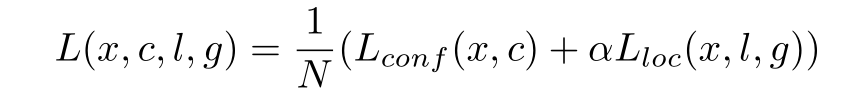
Lconf和Lloc分别代表的是得分损失函数和位置损失函数,N代表的数量,接下来将两个函数分开来看下:
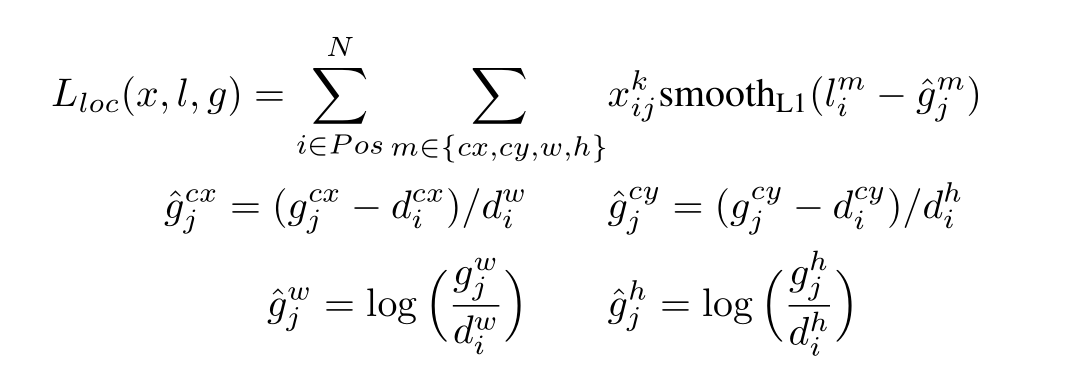
其中Xijk代表的是第i个default box,第j个box的比例,k代表的是第k个种类,X的值为{0,1},gj代表的是ground truth box,即图片中类别的位置,有四个,分别为cx,cy,w,h,di则对应的是之前default box计算的大小,然后根据上述公式转换算出所有的g',使用预测的l进行做差,使用smoothL1损失函数计算损失。

Lconf函数则相对比较简单,通过使用sigmod求出Cip的正比和反比,求log相加即可。
结束
到此整个ssd模型大体上算是讲清楚了,从model到match box到loss函数,算是整体过了一遍,其中还有一些不清楚的地方,可以参考下篇讲代码实现的博客。在论文中作者还使用了data argumentation,扩大数据,具体的做法在此不详细讲解了,笔者以后有时间会加以了解并讲解的。
ssd算法论文理解的更多相关文章
- SSD论文理解
SSD论文贡献: 1. 引入了一种单阶段的检测器,比以前的算法YOLO更准更快,并没有使用RPN和Pooling操作: 2. 使用一个小的卷积滤波器应用在不同的feature map层从而预测BB的类 ...
- object detection api调参详解(兼SSD算法参数详解)
一.引言 使用谷歌提供的object detection api图像识别框架,我们可以很方便地重新训练一个预训练模型,用于自己的具体业务.以我所使用的ssd_mobilenet_v1预训练模型为例,训 ...
- Raft 一致性算法论文译文
本篇博客为著名的 RAFT 一致性算法论文的中文翻译,论文名为<In search of an Understandable Consensus Algorithm (Extended Vers ...
- Vue中diff算法的理解
Vue中diff算法的理解 diff算法用来计算出Virtual DOM中改变的部分,然后针对该部分进行DOM操作,而不用重新渲染整个页面,渲染整个DOM结构的过程中开销是很大的,需要浏览器对DOM结 ...
- React中diff算法的理解
React中diff算法的理解 diff算法用来计算出Virtual DOM中改变的部分,然后针对该部分进行DOM操作,而不用重新渲染整个页面,渲染整个DOM结构的过程中开销是很大的,需要浏览器对DO ...
- openCV中直方图均衡化算法的理解
直方图均衡化就是调整灰度直方图的分布,即将原图中的灰度值映射为一个新的值.映射的结果直观表现是灰度图的分布变得均匀,从0到255都有分布,不像原图那样集中.图像上的表现就是对比度变大,亮的更亮,暗的更 ...
- SDUT OJ 数据结构实验之串一:KMP简单应用 && 浅谈对看毛片算法的理解
数据结构实验之串一:KMP简单应用 Time Limit: 1000 ms Memory Limit: 65536 KiB Submit Statistic Discuss Problem Descr ...
- [论文理解]关于ResNet的进一步理解
[论文理解]关于ResNet的理解 这两天回忆起resnet,感觉残差结构还是不怎么理解(可能当时理解了,时间长了忘了吧),重新梳理一下两点,关于resnet结构的思考. 要解决什么问题 论文的一大贡 ...
- POJ1523(割点所确定的连用分量数目,tarjan算法原理理解)
SPF Time Limit: 1000MS Memory Limit: 10000K Total Submissions: 7406 Accepted: 3363 Description C ...
随机推荐
- hdu5293(2015多校1)--Tree chain problem(树状dp)
Tree chain problem Time Limit: 6000/3000 MS (Java/Others) Memory Limit: 65536/65536 K (Java/Other ...
- Junit核心——测试集(TestSuite)
关于测试集,实质就是包含若干个测试类的集合,通过一个具体的实例,让我们来了解一下Junit的测试集 package org.yezi.junit; public class Calcaute { pu ...
- java泛型介绍
一.泛型初衷 Java集合不会知道我们需要用它来保存什么类型的对象,所以他们把集合设计成能保存任何类型的对象,只要就具有很好的通用性.但这样做也带来两个问题: –集合对元素类型没有任何限制,这样可能引 ...
- python的__init__和__new__
本文所有实例代码在python3.7下 一.__new__和__init__区别 1.__new__先于__init__执行;__new__是相当于其他OOP语言的构造方法,负责创建实例:之后,__i ...
- c++11 Using Callable Objects, std::thread, std::bind, std::async, std::call_once
- eclipse下的tomcat内存设置大小(转)
步骤: 1.点击Run 2.选择Run Configurations, 3.系统弹出设置tomcat配置页面,在Argument中末尾添加参数中的VM arguments中追加: -Xms256M - ...
- hibernate list和iterate
list方法会一次查出所有内容,放在list里和缓存中.再次查询同一内容仍然会去数据库重新查一遍,并刷新缓存. iterate方法会一次查出所有内容的ID,等用到某个ID对应的内容时又会去根据主键查询 ...
- tar 命令详解 / xz 命令
]# tar [-cxtzjvfpPN] 文件与目录 ....参数:-c :建立一个压缩文件的参数指令(create 的意思):-x :解开一个压缩文件的参数指令!-t :查看 tarfile 里面的 ...
- 使用SQL命令查看MYSQL数据库大小
mysql> mysql> use information_schema ; /*切换到information_schema数据下*/ Database changed mysql> ...
- jedis连接集群
/** * 集群版 */ @Test public void JedisJiuQun() { HashSet< ...