摘要:POLARDB是阿里云ApsaraDB数据库团队研发的基于云计算架构的下一代关系型数据库,其最大的特色是计算节点与存储节点分离,借助优秀的RDMA网络以及最新的块存储技术。POLARDB不但满足了公有云计算环境下用户业务快速弹性扩展的刚性需求,同时也满足了互联网环境下用户对数据库服务器高可用的需求。本文就带领大家了解什么是“云原生数据库”,云原生数据库的标准是什么,如何定义以及为何如此定义?为大家介绍下一代云原生数据库POLARDB的架构、产品设计、未来工作等内容。
演讲嘉宾简介:蔡松露(子嘉),阿里云云数据库总架构师,主要负责阿里云POLARDB、NoSQL技术以及阿里云数据库整体架构等工作。在搜索引擎、NoSQL数据库、分布式系统、操作系统内核等领域有深厚积累与丰富的经验。
本文主要内容有:
- 一、什么是云原生数据库
- 二、云原生数据库POLARDB架构实现
- 三、云原生数据库POLARDB产品设计
一、什么是云原生数据库
POLARDB是一个云原生数据库,关于云原生,演讲者团队在ICDE上做了相关阐述。本文通过视频整理,从架构和产品设计方面介绍POLARDB的架构和实现。
首先介绍实现云原生的门槛(PPT内容如下图所示),一个云原生的数据库必须拥有出色的性能,有上百万的QPS,规模很容易扩展到上百TB,同时在版本升级时尽量满足零宕机,最重要的一点是百分百兼容开源生态。门槛的定义,我们可以通过下面例子理解,一辆车可能有很拉风的外观,又有很快的速度,但是这辆车不能被直接称为跑车,也有可能是山寨车。也就是说以上的四点只是达到了云原生数据库的门槛值,还并不代表是这一个云原生的数据库。
下面介绍实现云原生的标准,首先我们看下图中所展示的,这些年数据库的演变。从数据库的规模来看,我们现如今处在一个数据爆炸的时代,从线性增长到如今指数级别的增长,数据库领域的核心理论也在发生变化,分布式系统领域中的CAP理论是指导我们设计系统的原则和基石,但是这个理论在最近几年也在发生改变,同时,最近也出现了很多的理论算法,例如paxos,raft等,如何应用这些算法到数据库架构的设计中是一个问题。另外,客户也在发生变化,以前的数据库客户来自于银行,政府或者全世界前500强企业,但现在的形式已经发生了巨大的转变,现在数据库的主体变成了互联网+,IOT等公司。此外,基础设施也在发生变化,以前用的是IDC等,现在很多新兴的业务都往云上迁移,而且在这个过程中一切都是在线的,包括用户与数据。
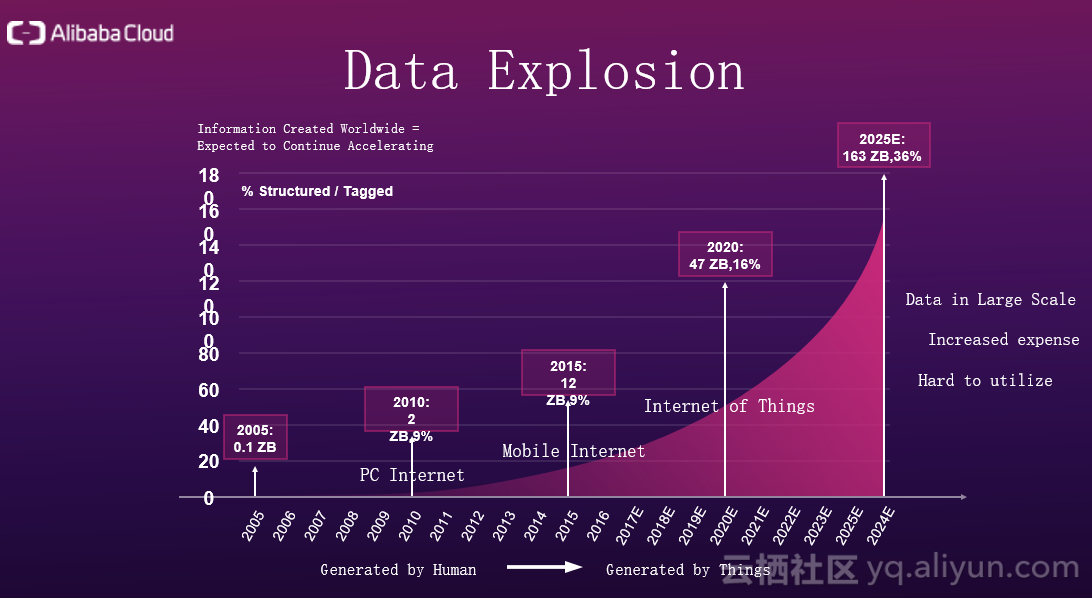
下图很好地展示了如今的数据爆炸形势。下图出自互联网女皇米克尔的互联网形势报告,通过报告,下图将互联网大概分为三个时代,第一是PC互联网时代,数据主要由PC产生;第二是移动互联网时代,数据产生自衣食住行,社交,工作等多个方面;第三是物联网时代,数据由传感器和终端设备产生,数据量从以前的线性增长变成了指数级别的增长。数据爆炸使得处理数据的成本越来越大,怎么采集数据,怎么存储数据,怎么搬运分析数据,都变得愈加复杂。操作数据的复杂性直接带来的后果就是,数据很难再被利用。但是,在这个新时代,数据像是石油,价值非常之大。
下图解释了CAP理论是怎么变化的。CAP中C代表一致性,A代表可用性,P代表分区容忍性,CAP的核心在于指出了当网络分区发生时,一致性和可用性是无法被完美地保证,无法同时被满足。C和A不是0和1的关系,而是99%和1%的关系,也就是说C和A不是互斥关系,它们是可以无限逼近的。在有些场景下,P问题和A问题可以建模成相同的问题,谷歌大神Jeff Dean有篇论文中对这个问题做了很好的阐述,他认为在某些场景下,P问题本质上就是A问题。P产生可能有两种情况,第一种,可能是网卡宕机了导致机器发生了网络分区,也可能是交换机挂掉导致一堆机器也挂了。网卡挂掉了,看上去像机器在系统中消失了,但本质上和宕机没有区别,因为宕机看上去也是机器突然消失了,所以在这种情况下,P问题就是A问题。第二种,机器的硬件不稳定,比如磁盘很卡导致响应请求很慢,这时候取决于怎么建模, P或A问题都可以解释。Paxos的核心在于每做一个决定时,多数派同意就行,可以容忍少数派不同意,所以Paxos对网络分区是有容忍性的,如果三个副本中的一个副本写的比较慢或者出现了问题,在Paxos下不会影响其他两个副本,仍然会正确返回结果。当发生大规模的宕机时,如果系统中使用Paxos利用拓扑容忍单个交换机挂掉的情况。如果多个交换机挂掉,甚至出现了3-4个网络分区,作为一个数据库,追求的是百分百的C,其次才是A。但是,时间上,多个交换机全部挂掉的几率非常小,相反,几台机器出问题的概率非常大,所以应该着重于解决常见问题,之后使得C和A无限逼近。
下面介绍客户发生的变化,如下图所示。客户对数据库的需求正不断演变,首先客户希望数据库更灵活,尤其对一些创业公司来说,机会是非常重要的,例如,当出现热点新闻,或者举办双十一的活动,公司很不希望数据库成为效率的瓶颈。此外,客户希望降低使用数据库的成本,也希望数据库更高效,能够花更少的钱买到更多的能力。同时,客户希望数据库更敏捷,假设一个公司在举办双十一活动时,系统挂1个小时或1分钟是完全不同的概念,也就是说客户希望在有故障发生时,数据库是灵活的,自治的,能快速从从故障中恢复过来。总结一下,现阶段,客户对数据库的要求是,弹性,低成本,高性能,业务永续性。
在新时代,数据是实时在线产生,收集,清洗,存储,分析的(即Everything is Online),再实时的应用到算法训练模型上。在中国,大概有70%的新兴公司都遇到了数据化的挑战,数据化的挑战也影响到了客户的业务。如下图中列出了遇到的一些挑战,主要有高成本,能力不足(没有专业的工程师,无法实现数据的备份,数据挖掘等功能),数据孤岛化(数据散落在各个IDC或自建的机房中,没有被很好的利用),数据规模很大(难以存储,搬运,分析,利用)。
以上提到的挑战促使我们设计云原生的数据库,根据总结的挑战,得出了设计云原生数据库的标准,如下图所示。首先,云原生数据库必须是HTAP的,是一整套解决方案,不仅满足TP的需求也满足AP的需求,使得TP和AP不需要远程同步,再做数据的转换,数据之间没有延迟,同时,能用一份存储同时完成TP和AP,明显降低了用户的存储成本;另外,云原生数据库应是serverless的,可以将存储进行分级,将成本降到最低,并且在serverless下的升降配非常简单;最后,云原生数据库必须是智能化的,能提供一些SQL优化,索引等,能实时监控诊断,也能提供管理系统方便成本控制。
下面将详细介绍做HTAP的原因,如下图所示。首先,HTAP对于分析来说,不存在任何延迟,对于实时性要求较高的业务是非常重要的,比如说实时反欺诈,过海关时需要调查的信息。同时,在架构中不需要同步,共用一份存储后,成本也会降低,不需要额外复制副本。AP和TP在计算层是被分开的,物理上完全隔离,可以在不同的维度扩展AP和TP,当AP的需求多,TP需求少时,可以扩展AP的结点,反之,扩展TP的结点,同时,AP也对TP不会造成干扰。
下面介绍实现Serverless的原因,如下图所示。原因主要在于两个方面,一个是成本,客户只为使用或存储付费,而且客户可以根据自己的业务模型定制不同的存储级别,比如说冷存储或热存储。这使得用户的消费呈现阶梯性,不会出现很大的跃迁。用户在刚办网站,流量还很少时,这时候可以采用serverless架构,在存储层使用冷存储,虽然延迟可能会大一些,但这是最经济的做法。随着业务的扩大,也可以在计算层继续使用Serverless架构,在存储层将冷存储换成热存储,业务再次扩大时,可以在计算层加一些结点,这样很大的提高了灵活性。
下面介绍提供智能化的原因,如下图所示。很多创业公司一开始支出较少,各方面的人才配置并不会齐全,云原生数据库的智能化能够告诉这些创业公司,该如何应对遇到的一些问题。同时,系统需要告诉用户此时此刻全链路的状况,存在哪些问题,如何解决。有了这些功能之后,能帮助用户从小白成为数据库专家,分布式系统专家,财务安全专家。
二、云原生数据库POLARDB架构实现
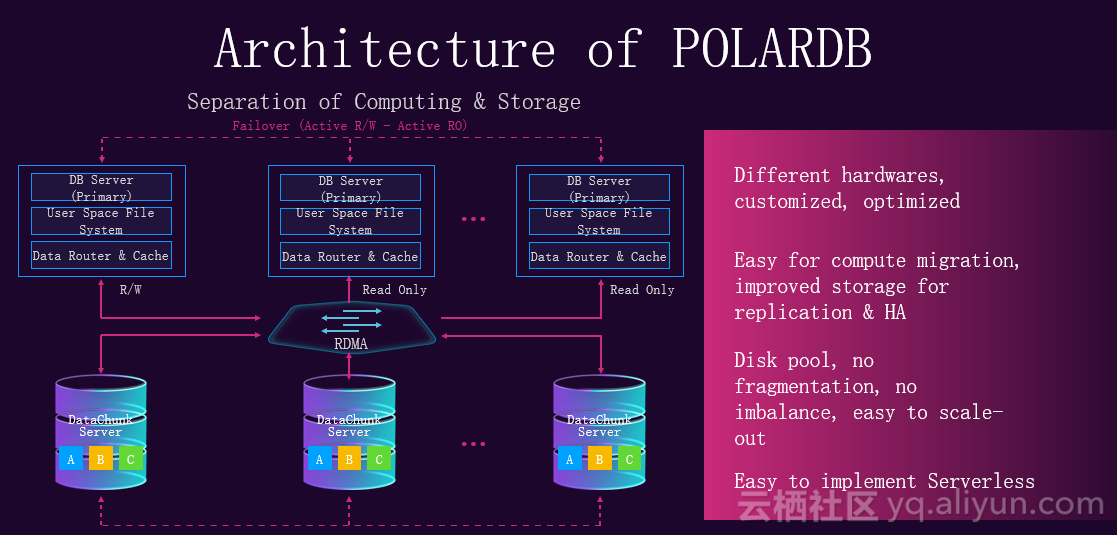
下文从架构,产品设计与未来工作介绍POLARDB。下图展现了POLARDB的整体架构,蓝色的线代表数据流,红色的线为控制流。控制流主要负责POLARDB生命周期的管理,数据流展现数据在整个系统中流转的情况。在设计POLARDB时遵循以下四个原则,第一为存储计算分离,全用户态,零拷贝。在架构的存储层使用三副本,采用变种raft算法,允许乱序的提交确认和应用,乱序也会引入一些问题。在设计POLARDB时,大量采用新硬件,例如RDMA,3D XPOINT等。
下面介绍进行存储计算分离的原因,如下图所示,上面一层为计算层,下面一层为存储层,两层使用RDMA连接。在计算层有一个主结点负责读写请求,还有一些备结点,只负责接收读请求。存储计算分离的好处在于对一体化架构的数据库进行水平切分,相当于切成了两层,对于这两层以前必须使用相同的硬件,现在可以根据这两层不同的特点定制不同的硬件策略。例如,在计算层更关注CPU和内存,在存储层更关注I/O响应时间和I/O成本,所以分离之后,针对这两层做出的硬件差别是很大的,这种差别又会带来新的红利,这些红利又可以释放给用户,这就是有时候技术优秀,成本还低的原因。在计算层,计算不持有数据,很方便进行迁移,在存储层,从原来大一统的架构中拆分出来,可以针对存储(分布式文件系统)有自己的复制策略,高可用的策略。相较于以前大一统的架构设计,如果对存储做一些策略会干扰到计算,对计算做策略可能干扰到存储。存储分离出来后,很方便进行池化,池化的好处在于没有碎片,也不会有不均衡的情况出现。如果有不均衡,存储层可以自己进行迁移。存储计算分离也能方便实现serverless。
下图展示了全用户态的设计,有用户态的文件系统,有Libpfs(分布式文件系统),有本地类似于网关的polarswitch,有用户态的IO栈,用户态的网络。POLARDB性能的提升很大一部分来自于全用户态和对新硬件的利用。消除进程切换,以及内存拷贝带来的收益非常大。
下图是对文件系统的详细解释,文件系统的特点是使用POSIX API,对DB层的侵入较小。同时,它是一个静态库,直接链接到数据库进程中。分布式系统的元数据是通过PAXOS进行同步的,带来的好处是,多台机器看到的是同一个目录,当用户去操作目录时,PAXOS可以在底部做一个串行,所以不会存在数据冲突的问题。在每个计算层的节点上,都会有对元数据的缓存,目的是做访问加速。
下图展示了ParallelRaft算法,乱序会让写入加速,带来接近翻倍的性能提升。
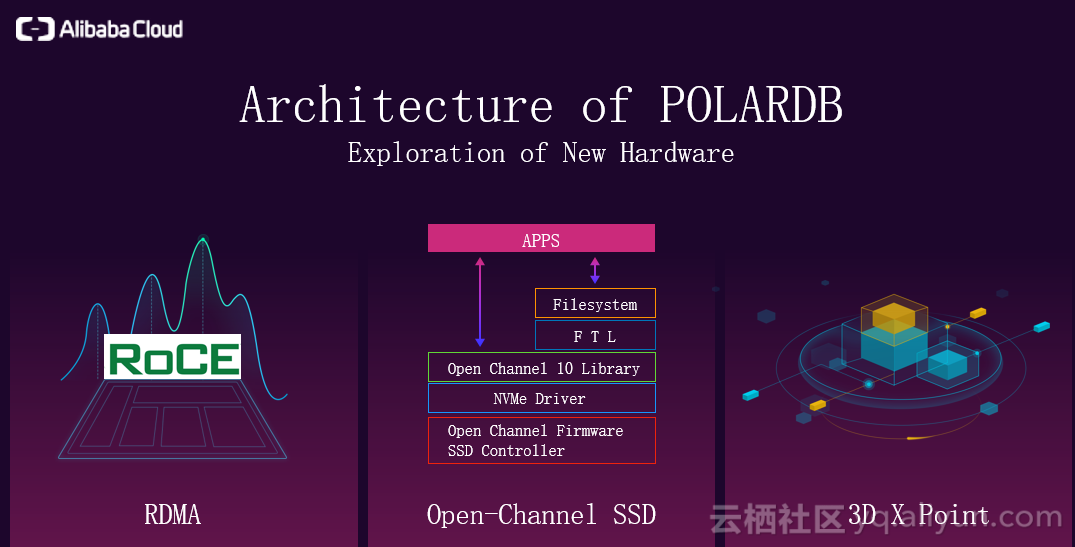
架构也用到了大量的新硬件,如下图所示,包括RDMA,3D XPOINT,演讲者团队正在研究的Open-Channel SSD。虽然SSD已经工业化很多年了,主流的存储都是SSD,但是目前对SSD的应用还存在很多问题。因为SSD的软件和硬件并不是非常匹配,导致我们对SSD的使用存在浪费,浪费一方面来自性能以及寿命。Open-Channel SSD方式对IO性能和寿命的影响最终反映到成本上,都比以前有了很大的提升。
下图展现了POLARDB和MySQL的对比结果,读性能相较于MySQL提高了5-6倍,写性能提高了3倍左右。同时,性能也在不断提升。
三、云原生数据库POLARDB产品设计
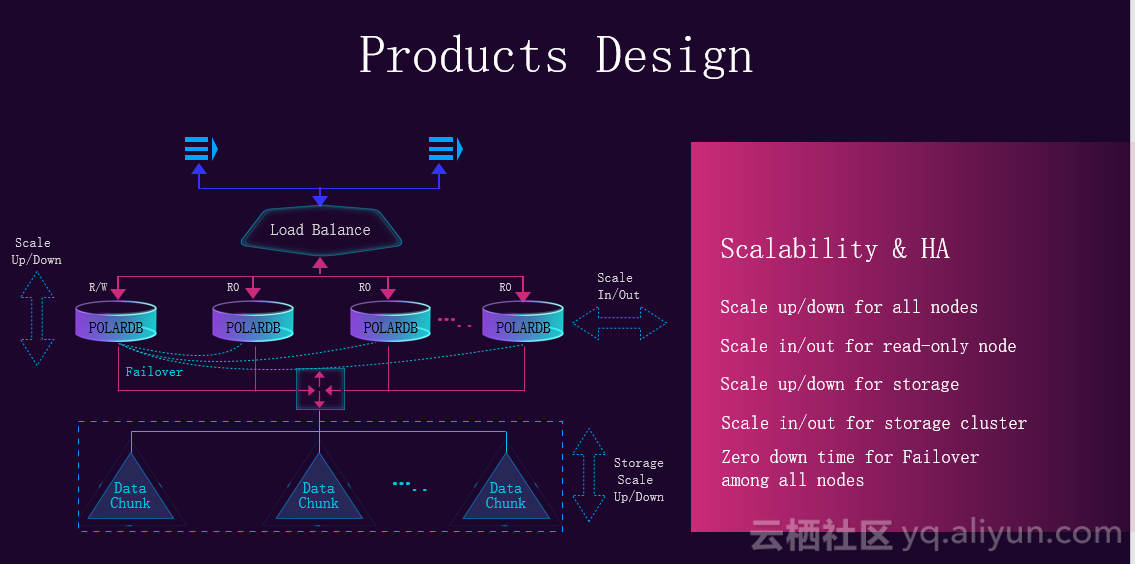
接下来介绍一些产品设计的特点,主要从五个维度设计产品,如下图所示,首先是性能,应该很方便地就能扩展到上百万QPS,而且RT很低;存储可以很方便的扩展到100TB,也很方便的缩回来;弹性上,版本升级时,尽量做到零宕机,在存储层,计算层可以方便进行scale-up以及scale-out;目前100%能兼容MySQL5.6;在可用性方面,承诺99.95%的可用性,99.999%的可靠性。在数据安全方面,演讲者团队会做定时的snapshot,并实时上传到OSS,提供物理备份和逻辑备份。在可用性上,主结点和readonly结点可以很方便的进行角色切换。
产品设计上是读写分离的,如下图所示,有一个结点是主结点接收读写请求,可以很方便地进行scale-up,其他结点都是只读结点,只读结点可以很方便的进行scale-out。读能力和只读结点的数量呈线性正比。
可扩展性方面,如下图所示,可以在计算层做scale-out和scale-up,从用户看来存储层是在做scale-up,但因为底层是分布式文件系统,当存储水位比较高时可以很方便的加入新的存储结点,所以本质上是scale-out。
在数据迁移方面,如下图所示,假设你是一个RDS的用户,通过备份到OSS,在POLARDB的实例里加载OSS上的备份的数据新生成POLARDB的实例,也可以通过DTS进行数据实时的迁移。在未来还可以提供一种方式,将POLARDB做成slave,直接挂到RDS的结点上,把数据实时的同步。如果用户使用的是第三方商用的数据库,因为DTS支持的数据库类型非常多,所以建议使用DTS。
在数据可靠性上,如下图所示,目前在官网上购买到的版本是在一个AZ里面的三副本。
未来工作中,在DB引擎层未来会提供多写的能力,而且数据库引擎层会引入新的组件例如CacheFusion,最大提升计算层的性能。未来会支持更多的数据库类型,在存储层会应用更多新的硬件,对某些IO进行加速,会用Open-Channel SSD对性能进一步提升,成本进一步降低。在扫描时,做计算下推,使回到计算层的数据尽量少。演讲者希望现有的分布式文件系统和数据库联系的更紧密,能感知InnoDB的语义。
数十款阿里云产品限时折扣中,
赶紧点击这里,领劵开始云上实践吧!
本文作者:nirvanalucky
- 洞见数据库前沿 集结阿里云数据库最强阵容 DTCC 2019 八大亮点抢先看
摘要: 作为DTCC的老朋友和全球领先的云计算厂商,阿里云数据库团队受邀参加本次技术盛会,不仅将派出重量级嘉宾阵容,还会为广大数据库业内人士和行业用户奉上8场精彩议题.下面小编就为大家提前梳理了8大亮 ...
- 云栖神侠传—阿里云数据库专家德歌告诉你PostgreSQL的那些事
什么是云栖神侠传: 云栖社区(http://yq.aliyun.com/?utm_source=yqdg),是阿里云面向开发者群体的开放型社区.在云栖社区中,活跃着许多阿里技术大牛,他们在自己的技术领 ...
- 阿里云数据库MySQL版快速上手!
MySQL是全球最受欢迎的开源数据库,其在各Web应用中均有广泛部署.阿里云数据库MySQL版基于Alibaba的MySQL源码分支,经过双11高并发.大数据量的考验,拥有优良的性能和吞吐量.除此之外 ...
- 云原生数据库崛起,阿里云POLARDB当选世界互联网领先科技成果!
第六届世界互联网大会来了!千年水乡古镇乌镇又一次吸引了全世界的目光. 刚刚,阿里云自研数据库POLARDB在会上当选世界互联网领先科技成果.POLARDB解决了企业在云时代的数据库难题,帮助企业在数小 ...
- 阿里云数据库再获学术顶会认可,一文全览VLDB最新亮点
一年一度的数据库领域顶级会议VLDB 2019于当地时间8月26日-8月30日在洛杉矶圆满落幕.在本届大会上,阿里云数据库产品团队浓墨登场,不仅有多篇论文入选Research Track和Indust ...
- 再不懂时序就 OUT 啦!,DBengine 排名第一时序数据库,阿里云数据库 InfluxDB 正式商业化!
云数据库 InfluxDB® 版介绍 阿里云数据库 InfluxDB® 版已于近日正式启动商业化 . 云数据库 InfluxDB® 是基于当前最流行的开源数据库 InfluxDB 提供的在线数据库服务 ...
- 阿里云数据库自研产品亮相国际顶级会议ICDE 推动云原生数据库成为行业标准
4月9日,澳门当地时间下午4:00-5:30,阿里云在ICDE 2019举办了主题为“云时代的数据库”的专场分享研讨会. 本次专场研讨会由阿里巴巴集团副总裁.高级研究员,阿里云智能数据库产品事业部负责 ...
- 选择阿里云数据库HBase版十大理由
根据Gartner的预计,全球非关系型数据库(NoSQL)在2020~2022预计保持在30%左右高速增长,远高于数据库整体市场. 阿里云数据库HBase版也是踏着技术发展的节奏,伴随着NoSQL和大 ...
- 洞见数据库前沿 阿里云数据库最强阵容 DTCC 2019 八大亮点抢先看
摘要: 作为DTCC的老朋友和全球领先的云计算厂商,阿里云数据库团队受邀参加本次技术盛会,不仅将派出重量级嘉宾阵容,还会为广大数据库业内人士和行业用户奉上8场精彩议题.下面小编就为大家提前梳理了8大亮 ...
随机推荐
- 测开之路一百零一:jquery文字特效、动画、方法链
文字特效 html内容 1.卷起/展开 2.隐藏/显示 3.淡入淡出 <!DOCTYPE html><html lang="en"><head> ...
- jQuery架构设计与实现(2.1.4版本)
市面上的jQuery书太多了,良莠不齐,看了那么多总觉得少点什么 对"干货",我不喜欢就事论事的写代码,我想把自己所学的知识点,代码技巧,设计思想,代码模式能很好的表达出来,所以考 ...
- nginx 配置总结
可以选择在http{ }中设置:client_max_body_size 20m; 也可以选择在server{ }中设置:client_max_body_size 20m; 还可以选择在locatio ...
- POJ-2287.Tian Ji -- The Horse Racing (贪心)
Tian Ji -- The Horse Racing Time Limit: 5000MS Memory Limit: 65536K Total Submissions: 17662 Acc ...
- Spring Boot 集成 Ehcache 缓存,三步搞定!
作者:谭朝红 www.ramostear.com/articles/spring_boot_ehcache.html 本次内容主要介绍基于Ehcache 3.0来快速实现Spring Boot应用程序 ...
- 洛谷 P3182 [HAOI2016]放棋子(高精度,错排问题)
传送门 解题思路 不会错排问题的请移步——错排问题 && 洛谷 P1595 信封问题 这一道题其实就是求对于每一行的每一个棋子都放在没有障碍的地方的方案数. 因为障碍是每行.每列只有一 ...
- luogu 3426题解 (KMP)
题面 Byteasar 想在墙上涂一段很长的字符,他为了做这件事从字符的前面一段中截取了一段作为模版. 然后将模版重复喷涂到相应的位置后就得到了他想要的字符序列.一个字符可以被喷涂很多次,但是一个位置 ...
- [常用类]Number & Math 类(转载)
下面的表中列出的是 Number & Math 类常用的一些方法: 序号 方法与描述 1 xxxValue() 将 Number 对象转换为xxx数据类型的值并返回. 2 compareTo( ...
- 洛谷 - P4008 - 文本编辑器 - 无旋Treap
https://www.luogu.org/problem/P4008 无旋Treap也可以维护序列. 千万要注意要先判断p节点存在才进行Show操作,不然输出一个'\0'(或者RecBin里面的东西 ...
- vue中搜索关键词,使文本标红
UserHead.vue中搜索框: <!-- 搜索 --> <el-col :span="6" :offset="8" class=" ...