论文阅读:FlexGate: High-performance Heterogeneous Gateway in Data Centers
摘要:
大型数据中心通过边界上的网关对每个传入的数据包执行一系列的网络功能,例如,ACL被部署来阻止不合格的流量,而速率限制被用于防止供应商过度使用带宽,但是由于流量的规模巨大,给网关的设计和部署带来了很大的挑战。
可选的解决方案有软件与硬件两种。
软件方面:NFV提供了高级处理和存储能力,简化了添加新功能的过程,但是最先进的NFV平台也只能支持10∼40Gbps,为了处理Tbps的流量需要部署十台至上百台服务器,以这种成本去部署不仅成本过高,也不利于日常的操作和维护。
硬件方面:近年来提出的可编程包处理硬件可以做到以Tbps的线率执行灵活的分组处理逻辑,加上有P4等高级编程语言的发展,使新功能的开发大大简化。然而这些硬件的处理能力和储存空间受到了限制。
其实软件网络功能平台和可编程硬件是相辅相成的,软件网关提供灵活性和大容量存储,而硬件提供超高的吞吐量处理,于是FlexGate被提出,作为一个软硬件协同设计网关来解决上述问题。
FlexGate可以以低成本、高吞吐量支持各种网络功能。实验表明,我们的存储优化机制节省了约50%的存储空间,FlexGate能够以至少1.5Tbps的线速处理实际业务。平均延迟为1.28微秒,99%的尾延迟为5.01微秒。
背景:
大型数据中心通过边界上的网关对每个传入的数据包执行一系列的网络功能,但是由于流量的规模巨大,给网关的设计和部署带来了很大的挑战。
但是通过观察表明:
- 网关上不同的网络功能处理的流量比例相差很大
- 在单一的功能中,小部分匹配规则服务于大部分流量。
(5%的规则,匹配90%以上的流量)
根据这些观察,我们决定:
- 将广泛使用的功能卸载到硬件上
- 将热点规则卸载到硬件中存储。
基于上述原理,我们提出了一种异构网关平台FlexGate。它包含一个可编程硬件和一个小型软件集群(我们的实现中有4个服务器)。FlexGate位于入站/出站流量的阻塞点(边界路由器)上,所有进入的流量首先通过可编程硬件,在大多数情况下,数据包完全由硬件处理,只有不可管理的数据包被定向到软件集群进行剩余的处理。
这种体系结构将可编程硬件和软件网关服务器的部署解耦,因此它们可以保持灵活和独立的可扩展性。此外,在实际操作中,我们发现硬件存储是瓶颈。通过考虑业务和功能的特点,我们将区分规则(而不是完全匹配列表)分布到硬件中的不同管道。
论文提出的问题:
如何解决软件或者硬件作为网关的固有问题:软件缺乏巨大的处理能力、硬件缺乏灵活性和大容量存储。
解决方案:
提出了FlexGate,作为一个软硬件协同设计网关来解决上述问题。
具体实现细节:
FlexGate的基本思想很简单:充分利用可编程硬件处理绝大多数流量,利用软件网关处理剩余流量,这需要特定的处理安排硬件中常用的功能(在硬件中实现每个功能将消耗处理单元和存储空间)。为了最大限度地利用硬件处理资源,以支持高吞吐量,我们只卸载功能大比例的流量到可编程硬件。其他很少使用的功能是用软件实现的。
这种解决方案可以:
- 限制传输到软件的流量
- 将阶段保存在可编程硬件中,以实现更大匹配范围的更多功能。
在硬件中放置热规则:
在硬件中存储函数的完全匹配表可能是不切实际的。例如,在我们的一个数据中心,IP NAT功能中有超过100万条规则。直接存储所有规则至少需要Tofino中52%的SRAM空间。根据第二个观察,我们可以选择服务于大部分流量的规则(即热规则),并且只将它们卸载到硬件上,然后大部分流量将在硬件中完全处理。丢失的数据包将被传输到软件中,软件将存储整个匹配表。
在以上两个原则的指导下,我们将在下面的部分介绍FlexGate的设计和实现。
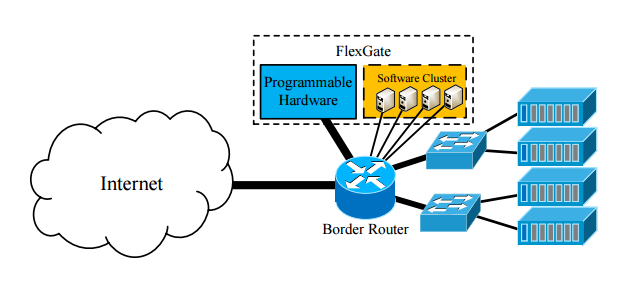
整体而言,FlexGate以悬挂的方式连接到数据中心的边界路由器,所有传入的流量将被定向到FlexGate进行网络功能处理,然后传播回正常转发。
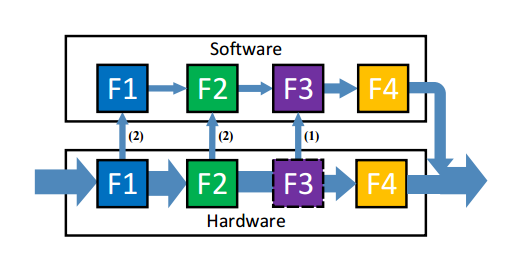
FlexGate的设计,并以四个函数为例介绍了FlexGate的处理过程。如图所示,软件拥有整个功能管道,可以处理任何流量。由于存储空间有限,F1、F2和F4被卸载到可编程硬件中,硬件中只存储F1、F2的部分匹配规则。进入的流量首先进入可编程硬件,大多数数据包完全由硬件处理和传播。由于匹配表不完整,F1和F2可能会丢失一些数据包,它们将被重定向到软件进行进一步处理。类似地,需要处理F3的分组也将被传送到软件。在我们的设计中,一旦一个包进入软件,它将留在软件中,直到所有后续的执行完成。
在硬件处理过程中,必须检测到不可管理的数据包,并在整个处理过程中将其传输到软件。检测分为两部分,第一部分是对于卸载部分匹配表的函数,如果一个包未命中硬件中的所有规则,我们可以将其标识为不可管理的包。另一部分是,对于仅在软件中的功能,会在硬件中实现一个额外的匹配阶段,以检测应由这些功能处理的包并将其标记为不可管理的包。受硬件限制,一旦数据包进入管道,就必须经过整个处理才能转发出去。为了保证处理序列不变,保持语义一致性,在包头向量中增加了额外的字段可操作性。一旦包被标识为不可管理,它的可操作性就被设置为False。然后以下所有功能都不对该包进行任何修改,并将其传输到软件网关以完成整个处理。
软件网关是基于DPDK实现的。在服务器中,每个核心部署整个功能链并以运行到完成模式运行,一旦接收到不可管理的数据包,NIC就会根据其5元组(利用RSS)将其转发到特定的核心。核心首先解析出下一个函数ID I,然后从函数I开始处理该包,经过整个函数链后,该包返回边界路由器进行正常转发。主处理流程和功能与之前的软件网关解决方案相同。
完善和优化:
利用可编程硬件中的多个管道优化性能
首先,所有传入的数据包通过边界路由器转发到可编程硬件。我们在边界路由器上使用5元组散列来平衡到可编程硬件中所有端口的流量,并根据其入口端口将数据包分配给入口管道。传入流的数量比硬件中的管道数量大几个数量级,因此这种基于5元组的哈希可以将流量均匀地分布到不同的管道。
为了正确处理所有数据包,每个管道需要为大多数网络功能存储已完成的卸载匹配表,它极大地浪费了可编程硬件中宝贵的存储资源。为了更好地利用存储空间,一个合理的方案是将每个匹配表分割成不相交的部分,将它们排列到不同的管道上,并部署一个预处理模块,将每个传入的数据包平衡到正确的管道上。
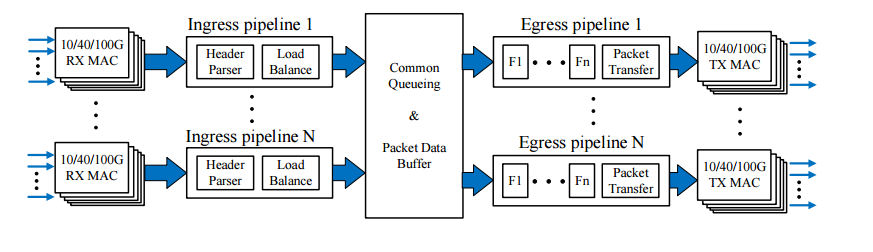
上图展示了可编程硬件中管道处理的体系结构:
我们在入口管道中实现了报头解析器和管道负载平衡模块,所有的网络功能都部署在出口管道中。因此,可以通过自定义的平衡方法将传入的数据包分发给目标流水线,这为在所有网络功能中分割匹配表提供了很大的灵活性。此外,由于入口和出口管道在商品可编程包处理硬件中共享相同的物理块,因此该体系结构不浪费任何计算/存储资源。入口管道中未使用的阶段、操作单元和内存可用于出口管道处理。
论文阅读:FlexGate: High-performance Heterogeneous Gateway in Data Centers的更多相关文章
- 论文阅读:Relation Structure-Aware Heterogeneous Information Network Embedding
Relation Structure-Aware Heterogeneous Information Network Embedding(RHINE) (AAAI 2019) 本文结构 (1) 解决问 ...
- 论文阅读:Andromeda: Performance, Isolation, and Velocity at Scale in Cloud Network Virtualization (全文翻译用于资料整理和做PPT版本,之后会修改删除)
Abstract: This paper presents our design and experience with Andromeda, Google Cloud Platform’s net ...
- [论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks
[论文阅读笔记] metapath2vec: Scalable Representation Learning for Heterogeneous Networks 本文结构 解决问题 主要贡献 算法 ...
- [论文阅读笔记] Are Meta-Paths Necessary, Revisiting Heterogeneous Graph Embeddings
[论文阅读笔记] Are Meta-Paths Necessary? Revisiting Heterogeneous Graph Embeddings 本文结构 解决问题 主要贡献 算法原理 参考文 ...
- [论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks
[论文阅读笔记] Adversarial Learning on Heterogeneous Information Networks 本文结构 解决问题 主要贡献 算法原理 参考文献 (1) 解决问 ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记 - Mesos: A Platform for Fine-Grained ResourceSharing in the Data Center
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
随机推荐
- Django框架中使用Echart进行统计的SQL语句
最近想用Echart做数据统计的图形显示,数据来源是MySQL数据库,自然需要根据不同的搜索条件筛选出表中的数据,用比较多的就是时间的参数吧! 常用的mysql时间的条件进行检索的SQL语句: 数据表 ...
- [转帖]linux文件描述符文件/etc/security/limits.conf
linux文件描述符文件/etc/security/limits.conf https://blog.csdn.net/fanren224/article/details/79971359 需要多学习 ...
- [转帖]中国AI芯“觉醒”的五年
中国AI芯“觉醒”的五年 https://www.cnbeta.com/articles/tech/857863.htm 原来 海思的营收已经超过了按摩店(AMD) 没想到.. 十多款芯片问世,多起并 ...
- 极*Java速成教程 - (1)
序言 众所周知,程序员需要快速学习新知识,所以就有了<21天精通C++>和<MySQL-从删库到跑路>这样的书籍,Java作为更"高级"的语言也不应该落后, ...
- tarjan算法求无向图的桥、边双连通分量并缩点
// tarjan算法求无向图的桥.边双连通分量并缩点 #include<iostream> #include<cstdio> #include<cstring> ...
- luogu P4382 [九省联考2018]劈配
luogu 我记得我第一次做这道题的时候屁都不会qwq 先考虑第一问,暴力是依次枚举每个人,然后从高到低枚举志愿,枚举导师,能选就选.但是可以发现前面的人选的导师可能会导致后面的人本来可以选到这个志愿 ...
- 10.css3动画--过渡动画--trasition
Transition简写属性. Transition-property规定应用过渡的css属性的名称. . Transition-timing-function过渡效果的时间曲线,默认是ease. L ...
- thinkphp5+layui多图片上传
准备资料 下载layui <!DOCTYPE html> <html> <head> <meta charset="utf-8"> ...
- css3 伪类以及伪元素的特效
菱形
- pip 安装超时解决方案
已经使用梯子,安装某依赖时仍然超时. 首先检查pip的版本是否需要更新,如果不是最新版本运行命令更新: python -m pip install --upgrade pip 如果仍然超时错误,则运行 ...