计算机系统结构总结_Cache Optimization
Textbook:
《计算机组成与设计——硬件/软件接口》 HI
《计算机体系结构——量化研究方法》 QR
Ch4. Cache Optimization
本章要讨论的问题就是 How to Improve Cache Performance?
前面讲过 Average memory access time = HitTime + (MissRate * MissPenalty)
那么我们的方向就是Reduce MissRate / HitTime / MissPenalty
1. 6 Basic Cache Optimization(PPT P3)
• Reducing hit time
1. Giving Reads Priority over Writes
• E.g., Read complete before earlier writes in write buffer ??
2. Avoiding Address Translation during Cache Indexing
Cache中使用虚拟地址,这样就可以同时Access TLB和Cache / Access Cache firstly
• Reducing Miss Penalty
3. Multilevel Caches
AMAT = Hit TimeL1 + Miss RateL1 x Miss PenaltyL1
Miss PenaltyL1 = Hit TimeL2 + Miss RateL2 x Miss PenaltyL2
原来Miss PenaltyL1要访问内存,很慢。现在多了L2
• Reducing Miss Rate
4. Larger Block size (Compulsory misses)
...
5. Larger Cache size (Capacity misses)
...
6. Higher Associativity (Conflict misses)
...
2. 11 Advanced Cache Optimizations (PPT P12)
• Reducing hit time
1. Small and simple caches(QR P59)
如果仅考虑Cache Hit Time,那么结构越简单、容量越小、组相连路数越少的缓存肯定是越快的。
所以出于速度考虑,CPU的L1缓存都是很小的。比如从Pentium MMX到Pentium 4,L1缓存的容量都没有增长。
不过太少了肯定也是不行的。。。所以这也是一个Trade off
2. Way prediction
直接相连的Hit Time是很快的,但conflict miss多。组相连可以减少conflict miss,但结构复杂功耗也高一些,hit time也多一点。那么有什么方法能两者兼得呢?
因为组相连缓存中,每一个组里面的N个路(block)是全相连的。也就是相当于读的时候,每次映射好一个set之后,要遍历一遍N个block,当N越大的时候费的时间就越多。有一种黑科技方法叫做路预测(way prediction),它的思想就是在缓存的每个块中添加预测位,来预测在下一次缓存访问时,要访问该组里的哪个块。当下一次访问时,如果预测准了就节省了遍历的时间(相当于直接相连的速度了);如果不准就再遍历呗。。。
好在目前这个accuracy还是很高的,大概80+%了。
不过有个缺点就是Hit Time不再是确定的几个cycle了(因为没命中的时候要花的cycle多嘛),不便于后面进行优化(参考CPU pipeline)。
3. Trace caches
这个只针对instruction cache。在读取指令缓存时,要不断jump来读取不同的指令(也就是比较random的Access pattern),这样就不如sequential的access快了。
在牙膏厂的Pentium 4中,使用了trace caches的黑科技。它会尝试找出相邻被访问的指令(比如A jump to B),然后把这些block放到邻近的位置,这样就可以access instruction cache sequentially。
但因为现在code reuse rate不高了(程序太多了,很多程序可能一段时间内只执行一次),再加上这个黑科技implement比较复杂,后来就放弃了。
• Increasing cache bandwidth
4. Pipelined caches
在本科的计组课上我们学过pipeline的思想。在cache访问中也可以使用pipeline技术。
但pipeline是有可能提高overall access latency的(比如中间有流水线气泡),而latency有时候比bandwidth更重要。所以很多high-level cache是不用pipeline的
5. cache with Multiple Banks
对于Lower Level Cache(比如L2),它的read latency还是有点大的。假设我们有很多的cache access需要访问不同的数据,能不能让它们并行的access呢?
可以把L2 Cache分成多个Bank(也就是多个小分区),把数据放在不同Bank上。这样就可以并行访问这几个Bank了。
那么如何为数据选一个合适的Bank来存呢?一个简单的思路就是sequential interleaving:Spread block addresses sequentially across banks. E,g, if there 4 banks, Bank 0 has all blocks whose address modulo 4 is 0; bank 1 has all blocks whose address modulo 4 is 1; ...... 因为数据有locality嘛,把相邻的块存到不同bank,就可以尽量并行的访问locality的块了
6. Nonblocking caches
假设要执行下面一段程序:
Reg1:=LoadMem(A);
Reg2:=LoadMem(B);
Reg3:=Reg1 + Reg2;
当执行第一行时,cpu发现地址A不在cache中,就需要去内存读。但读内存的时间是很长的,此时CPU也不会闲着,就去执行了第二行。然后发现B也不在cache中。那么此时cache会怎么做呢?
- (a). cache阻塞,等着先把A读进来,然后再去读B。这种叫做Blocking Cache
- (b). cache同时去内存读B,最终B和A一起进入Cache。这种叫做Non-Blocking Cache
可以看出Non-Blocking Cache应该是比较高效的一种方法。在这种情况下,两条语句的总执行时间就只有一个miss penalty了:
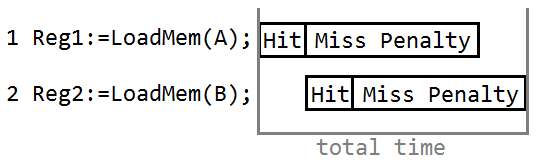
(图中只是大概的描述,不是精确的时间计算。。。如果用了上面介绍的multiple bank cache,那么hit时间可能也只需要一次了,很棒棒吧!)
• Reducing Miss Penalty
7. Early Restart and Critical word first
相对一个Word来说,cache block size一般是比较大的。有时候cpu可能只需要一个block中的某一个word,那么如果cpu还要等整个block传输完才能读这个word就有点慢了。因此我们就有了两种加速的策略:
- Critical Word First:首先从存储器中读想要的word,在它到达cache后就立即发给CPU。然后在载入其他目前不急需的word的同时,CPU就可以继续运行了
- Early Restart:或者就按正常顺序载入一整个block。当所需的word到达cache后就立即发给CPU。然后在载入其他目前不急需的word的同时,CPU就可以继续运行了
大概就是这个意思:
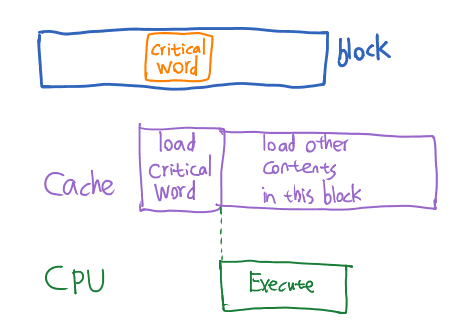
根据locality的原理,一般来说CPU接下来要访问的也就是这个block中的剩余内容。所以没毛病!
8. Merging write buffers
?????(QR P65)
• Reducing Miss Rate
9. Compiler optimizations
这是最喜闻乐见的一种方法了hhhh
这里的reducing miss rate又可以分为Instruction miss和data miss两类:
Instruction Miss:
• Reorder procedures in memory so as to reduce conflict misses
• Profiling to look at conflicts(using tools they developed) (之前面试还被问到过Linux profiling了......)
Data Miss:这个是比较重要的一种方式了。网上很多大神所说的黑科技优化C代码的原理就是这个。
- 1. Merging Arrays: improve spatial locality by single array of compound elements vs. 2 arrays
假设有下面两个定义(他们的功能都是一样的,只是写法不同):
/* Before: 2 sequential arrays */
int val[SIZE];
int key[SIZE]; /* After: 1 array of stuctures */
struct merge {
int key;
int val;
};
struct merge merged_array[SIZE];
我们可以比较一下对于这两种定义方式,它们在内存中的组织方式:

好的现在我们要对index k,分别访问key[k]和val[k]。
/* Before: Miss Rate = 100% */
int k=rand(k);
int _key=key[k];
int _val=val[k]; /* After: Miss Rate = 50% */
int k=rand(k);
int _key=dat[k].key;
int _val=dat[k].val;
可以看出第二种方式充分利用了spatial locality。对于同一个index k,读取key_k的同时,val_k也被读进cache啦,这样就节省了一次访问内存的时间。
上面这个还可以引申出另一个话题,叫做结构体对齐。
- 2. Loop Interchange: change nesting of loops to access data in order stored in memory
还是下面两种程序,它们只是循环次序改变了:
int x[][]; //very large
//Assume a cacheline could contain 2 integers. /* Before */
for (j = ; j < ; j = j+)
for (i = ; i < ; i = i+)
x[i][j] = * x[i][j];
/* After */
for (i = ; i < ; i = i+)
for (j = ; j < ; j = j+)
x[i][j] = * x[i][j];
我们知道在C语言中,二维数组在内存中的存储方式是Row Major Order的,也就是这样:

那么对于第一种写法,访问顺序是x[0][0], x[1][0], x[2][0], ......。Miss Rate达到了100%
第二种写法,访问顺序是x[0][0], x[0][1], x[0][2], x[0][3], ......。读x[0][0]的时候可以把x[0][1]也读进来,读x[0][2]的时候可以把x[0][3]也读进来,以此类推。这样Miss Rate就只有50%啦
- 3. Loop Fusion: Combine 2 independent loops that have same looping and some variables overlap
来看个例子:
/* Before */
for (i = ; i < N; i = i+)
for (j = ; j < N; j = j+)
a[i][j] = /b[i][j] * c[i][j];
for (i = ; i < N; i = i+)
for (j = ; j < N; j = j+)
d[i][j] = a[i][j] + c[i][j]; /* After */
for (i = ; i < N; i = i+)
for (j = ; j < N; j = j+){
a[i][j] = /b[i][j] * c[i][j];
d[i][j] = a[i][j] + c[i][j];
}
在第二种写法中,line 13已经把a[i][j]和c[i][j]读进cache了,line14就可以接着用了。加起来比第一种要省很多cache miss。
不过第一种写法本身时间复杂度也高啊。。。这样写代码会被人打的。。。
emmm上面这个例子比较弱智。。。下面再来看一个经典的Matrix Multiplication的例子:
假设我们要计算一个大矩阵的乘法,然后cache block是4个integer的大小。
矩阵乘法是三重循环,O(N^3)的。我们来分析不同的循环顺序下,最内层循环的cache miss情况(因为cache很小,只会在最内层循环起作用,外面的肯定都要有miss的):
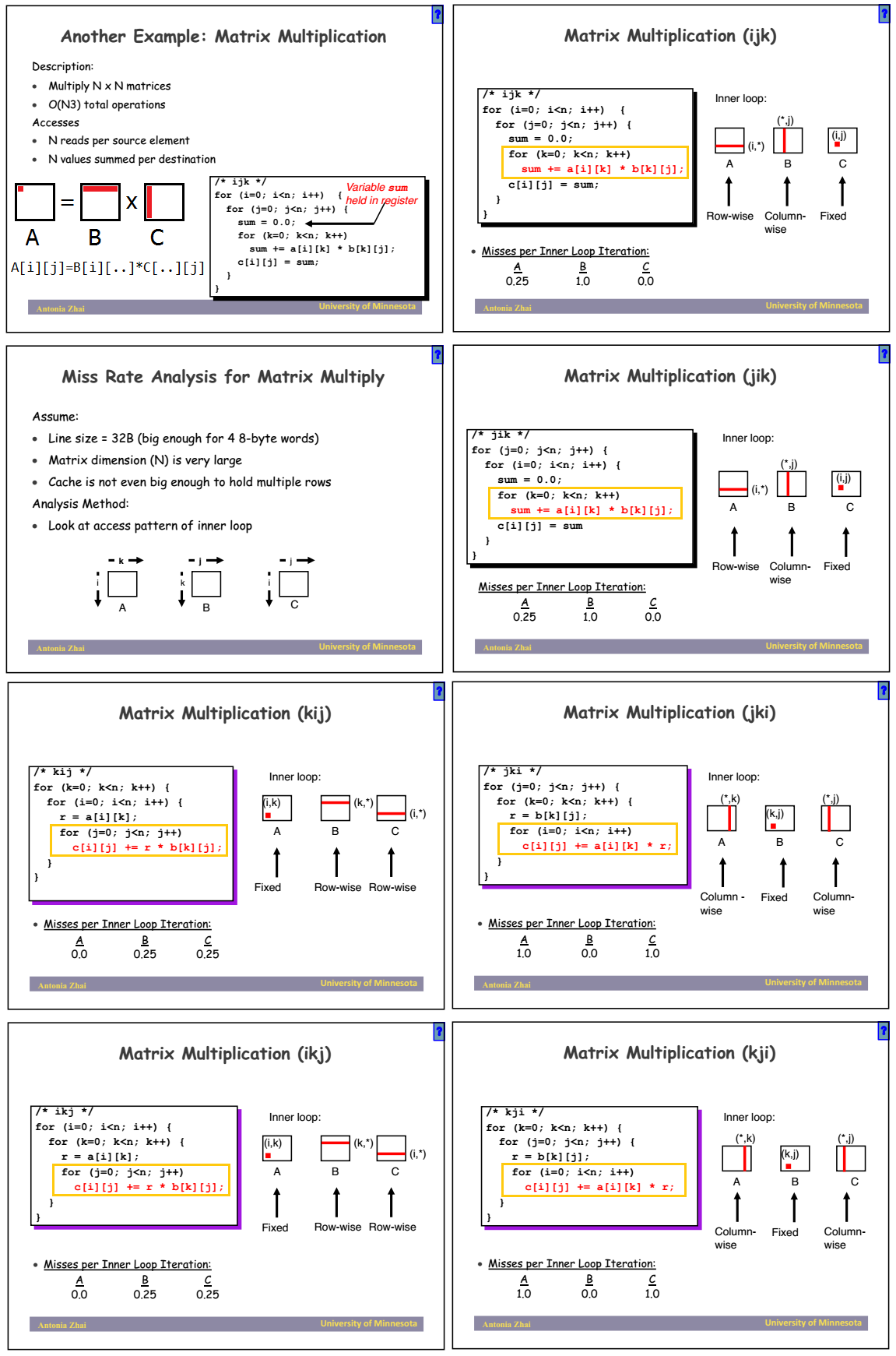
- 4. Blocking: Improve temporal locality by accessing “blocks” of data repeatedly vs. going down whole columns or rows
从上面的例子中可以看到,当每次access的是同一column中的不同row(a[1][3], a[2][3], a[3][3], a[4][3], ......),而不是同一row的不同colum时,miss rate是很可怕的。那么怎么避免这一现象呢?
一种思路是我们把整个大矩阵分解成若干个小矩阵(以所需的数据能被cache全部装下为标准),然后每次都把这个小块内要计算的任务全部完成,这样就不用access whole column了。
/* Before */
for (i = ; i < N; i = i+)
for (j = ; j < N; j = j+){
r = ;
for (k = ; k < N; k = k+)
r = r + y[i][k]*z[k][j];
x[i][j] = r;
} /* After */
for (jj = ; jj < N; jj = jj+B)
for (kk = ; kk < N; kk = kk+B)
for (i = ; i < N; i = i+)
for (j = jj; j < min(jj+B-,N); j = j+){
r = ;
for (k = kk; k < min(kk+B-,N); k = k+){
r = r + y[i][k]*z[k][j];
}
x[i][j] = x[i][j] + r;
}
其中B叫做Blocking Factor。(QR P67)
• Capacity Misses from 2N3 + N2 to 2N3/B +N2
• Conflict Misses Too?(没讲)
Blocking Transformation
其实前面提到的这些access pattern现在已经可以被compiler自动优化了,所以也算是上古时代的黑科技了......
• Reducing miss penalty or miss rate via parallelism
10. Hardware prefetching
假设cache block只能装下一个int,然后我们有如下指令:
int a[];
load a[];
load a[];
load a[];
load a[];
load a[];
load a[];
那么与其每次都cache miss重新载入,不如在第一次cache miss(load a[0])时,让cache预测到接下来会用到a[1], a[2], a[3], ......,然后提前载入到next level cache里备用。这就是硬件的prefetching。
对于Instruction Prefetching,CPU fetches 2 blocks on a miss: the requested block and the next consecutive block.(Requested block is placed in instruction cache when it returns, and prefetched block is placed into instruction stream buffer)
对于Data Prefetching,Pentium 4 can prefetch data into L2 cache from up to 8 streams from 8 different 4 KB pages. Prefetching invoked if 2 successive L2 cache misses to a page, or if distance between those cache blocks is < 256 bytes.
但hardware prefetching只对比较predictable的access pattern(特别是instruction prefetching)起作用。如果是访问一个动态链表那就不管用了......
11. Compiler prefetching
????(QR P69)
最后是对这些cache optimization的一个总结(QR P72):
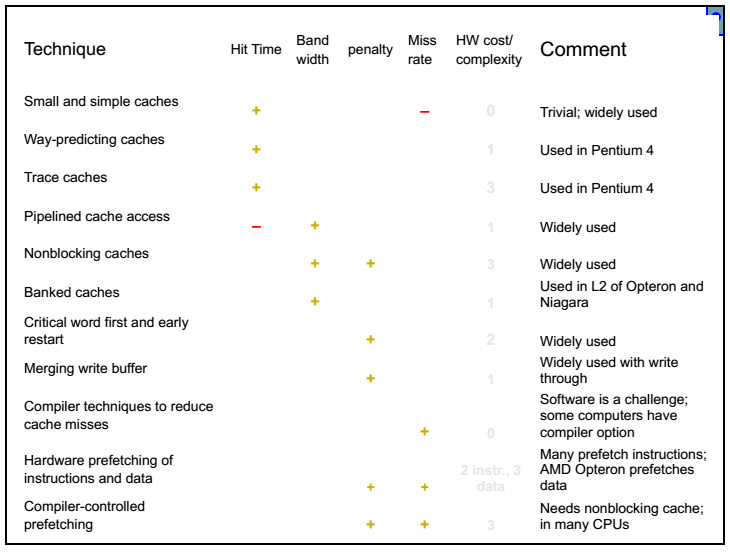
...
计算机系统结构总结_Cache Optimization的更多相关文章
- 【5分钟+】计算机系统结构:CPU性能公式
计算机系统结构:CPU性能公式 基础知识 CPU 时间:一个程序在 CPU 上运行的时间.(不包括I/O时间) 主频.时钟频率:CPU 内部主时钟的频率,表示1秒可以完成多少个周期. 例如,主频为 4 ...
- 计算机系统结构总结_Multiprocessor & cache coherence
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 最后一节来看看如何实现parallelism 在多处 ...
- 计算机系统结构总结_Branch prediction
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR Branch Prediction 对于下面的指令: ...
- 计算机系统结构总结_Scoreboard and Tomasulo
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 超标量 前面讲过超标量的概念.超标量的目的就是实现指 ...
- 计算机系统结构总结_Instruction Set Architecture
Textbook:<计算机组成与设计——硬件/软件接口> HI<计算机体系结构——量化研究方法> QR 这节我们来看CPU内部的一些东西. Instruct ...
- 计算机系统结构总结_Memory Hierarchy and Memory Performance
Textbook: <计算机组成与设计——硬件/软件接口> HI <计算机体系结构——量化研究方法> QR 这是youtube上一个非常好的memory syst ...
- 计算机系统结构总结_Memory Review
这次就边学边总结吧,不等到最后啦 Textbook: <计算机组成与设计——硬件/软件接口> HI <计算机体系结构——量化研究方法> QR Ch3. Memor ...
- 计算机体系结构——CH1基本概念
CH1基本概念 右键点击查看图像,查看清晰图像 CH1基本概念 目的与内容 了解计算机系统的完整概念 学习计算机系统的分析方法与设计方法 编写程序所必需了解的计算机属性 计算机系统结构简介 为什么要研 ...
- Linux Barrier I/O 实现分析与barrier内存屏蔽 总结
一直以来.I/O顺序问题一直困扰着我.事实上这个问题是一个比較综合的问题,它涉及的层次比較多,从VFS page cache到I/O调度算法,从i/o子系统到存储外设.而Linux I/O barri ...
随机推荐
- 人脸三维建模A Morphable Model For The Synthesis Of 3D Faces(三维人脸合成的变形模型)
Abstract摘要 In this paper, a new technique for modeling textured 3D faces is introduced. 3D faces can ...
- sqli-labs(33)
0X01构造闭合 发现‘ 被过滤了 那么 宽字节绕过 ?id=-%df%%20union%20,database(),%
- sqli-labs(20)
0X01 试探一下 这是登录成功的页面 这里题目高速我们是基于cookie的注入 0X01抓包试探 这里登陆的时候有两个包 我们要含有cookie的那个包 0X02试探判断是否cookie存在注入 C ...
- Hashtable 和 HashMap 的区别是:
HashMap 是内部基于哈希表实现,该类继承AbstractMap,实现Map接口 Hashtable 线程安全的,而 HashMap 是线程不安全的 Properties 类 继承了 Hashta ...
- mysql 安装教程(详细说明)
如果你装过,一定要先卸载干净,并且重启重新装.卸载教程(保证成功)https://www.cnblogs.com/qzhc/p/11354678.html 大家都知道MySQL是一款中.小型关系型数据 ...
- hg(Mercurial)使用参考
hg(Mercurial)使用参考 使用hg(mercurial)有好几个月了,个人感觉这款分布式的版本控制系统非常不错,易学,易用:你可以从做在你旁边的同事拉取完整的代码; 对网络的依赖性更低, ...
- sh脚本获取当前目录
#!/bin/bashcurDir=$(pwd)echo "cur dir is:$curDir"
- 洛谷P1190 接水问题
题目名称:接水问题 题目来源 [洛谷P1190] (https://www.luogu.org/problemnew/show/P1190) 题目描述 学校里有一个水房,水房里一共有\(m\)个龙头 ...
- k8s 添加ingress 暴露服务
vim file.yaml apiVersion: extensions/v1beta1 kind: Ingress metadata: name: pgadmin labels: k8s-app: ...
- 前端必须掌握的 docker 技能(3)
概述 作为一个前端,我觉得必须要学会使用 docker 干下面几件事: 部署前端应用 部署 nginx 给部署的 nginx 加上 https 使用 docker compose 进行部署 给 ngi ...