自定义类实现原生SQL的GROUP_CONCAT的功能
大家都知道,原生的SQL为我们提供了分组之后查找组内数据的办法:GROUP_CONCAT方法;但是对于用Django开发的程序员来说~Django自带的ORM并没有内置这样功能的方法,而每一次遇到这样的需求如果都要用原生SQL去解决的话势必会降低我们的开发效率。
本文为大家介绍一种在Django项目中自定义类Coucat类的方式去实现对应的效果。
表关系
现在假设我们的Django项目的book应用中有两张关联的表:book表与publish表。表结构如下:
book表:
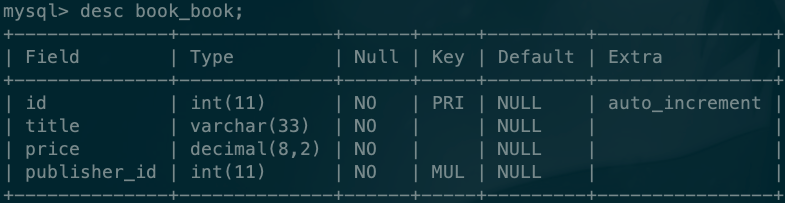
publish表:
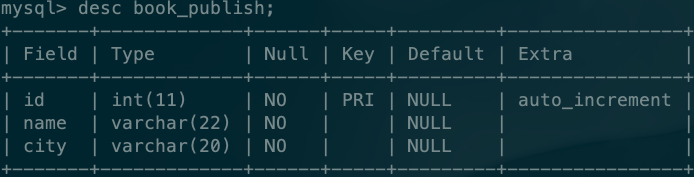
其中:book表的publisher_id是通过ORM语法与publish表建立关联的外键字段。
原生SQL中GROUP_CONCAT的分组查询
单表下的分组查询
按照publisher_id分组查询每组数据下的书名:
select group_concat(title),publisher_id from book_book GROUP BY(publisher_id);
结果如下:

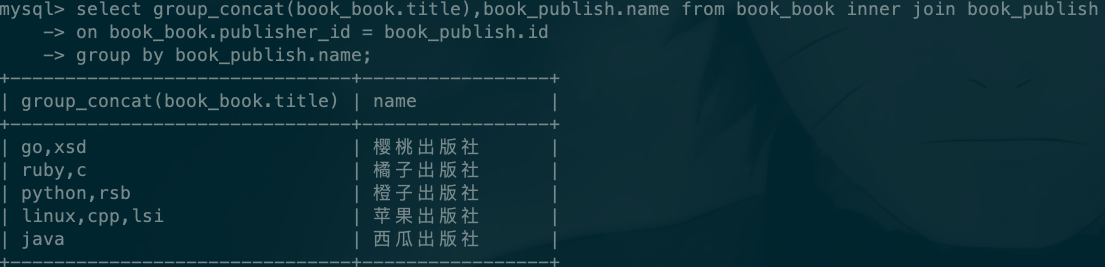
连表下的分组查询
查找每个出版社出版的书籍的名称
select group_concat(book_book.title),book_publish.name from book_book inner join book_publish
on book_book.publisher_id = book_publish.id
group by book_publish.name;
结果如下:
ORM中自定义Concat类实现COUCAT_GROUP的效果
在我们Django项目中的lib目录下新建一个concat.py文件,文件中的内容如下:
# -*- coding:utf-8 -*-
from django.db.models import Aggregate,CharField class Concat(Aggregate):
function = 'GROUP_CONCAT'
template = '%(function)s(%(distinct)s%(expressions)s)' def __init__(self,expression,distinct=False,**extra):
super(Concat,self).__init__(
expression,
distinct='DISTINCT' if distinct else '',
output_field=CharField(),
**extra)
以上的代码就是我们实现COUCAT_GROUP效果的类。
然后,创建一条测试路由:
url(r'^concat/',views.concat),
视图函数中concat函数实现具体的功能:
from django.shortcuts import HttpResponse
from lib.concat import Concat
def concat(request):
# 单表:用publisher_id分组,找每个分组中的书籍名称
ret = Book.objects.values('publisher_id').annotate(titles=Concat('title'))
print(ret)
#<QuerySet [{'publisher_id': 21, 'titles': 'linux,cpp,lsi'}, {'publisher_id': 22, 'titles': 'ruby,c'},
# {'publisher_id': 23, 'titles': 'go,xsd'}, {'publisher_id': 24, 'titles': 'java'}, {'publisher_id': 25, 'titles': 'python,rsb'}]>
#跨表:每个出版社出版的所有的书籍
#方法一:以publish表为基准去查
ret = Publish.objects.values('name').annotate(titles=Concat('book__title'))
print(ret)
#<QuerySet [{'name': '樱桃出版社', 'titles': 'go,xsd'}, {'name': '橘子出版社', 'titles': 'ruby,c'},
# {'name': '橙子出版社', 'titles': 'python,rsb'}, {'name': '苹果出版社', 'titles': 'linux,cpp,lsi'}, {'name': '西瓜出版社', 'titles': 'java'}]>
#方法二:以book表为基准去查
ret = Book.objects.values('publisher__name').annotate(titles=Concat('title'))
print(ret)
#<QuerySet [{'publisher__name': '樱桃出版社', 'titles': 'go,xsd'}, {'publisher__name': '橘子出版社', 'titles': 'ruby,c'},
# {'publisher__name': '橙子出版社', 'titles': 'python,rsb'}, {'publisher__name': '苹果出版社', 'titles': 'linux,cpp,lsi'},
# {'publisher__name': '西瓜出版社', 'titles': 'java'}]>
return HttpResponse('Concat')
大家可以看到,用法也十分简单,只需要在分组的annotate方法中加上我们定义的这个类就可以了~
自定义类实现原生SQL的GROUP_CONCAT的功能的更多相关文章
- Java基础知识强化之IO流笔记55:IO流练习之 自定义类模拟LineNumberReader的获取行号功能案例
1. 自定义类模拟LineNumberReader的获取行号功能案例 2. 代码实现: (1)MyBufferedReader.java: package cn.itcast_08; import j ...
- legend---十、thinkphp中如何进行原生sql操作
legend---十.thinkphp中如何进行原生sql操作 一.总结 一句话总结:query方法和execute方法 Db类支持原生SQL查询操作,主要包括下面两个方法: query方法 quer ...
- jpa 联表查询 返回自定义对象 hql语法 原生sql 语法 1.11.9版本
-----业务场景中经常涉及到联查,jpa的hql语法提供了内连接的查询方式(不支持复杂hql,比如left join ,right join). 上代码了 1.我们要联查房屋和房屋用户中间表,通过 ...
- springdata 查询思路:基本的单表查询方法(id,sort) ---->较复杂的单表查询(注解方式,原生sql)--->实现继承类---->复杂的多表联合查询 onetomany
springdata 查询思路:基本的单表查询方法(id,sort) ---->较复杂的单表查询(注解方式,原生sql)--->实现继承类---->复杂的多表联合查询 onetoma ...
- 使用原生SQL返回实体类具体实现详情
注:可以直接复制粘贴,欢迎提出各种问题,谢谢! 因为网上查询大都是相同的,自己做时发现很多不懂,摸索了很久才弄懂,所以写了这个例子,比较容易看懂吧. 使用原生SQL查询并将结果返回实体中: (1)因为 ...
- hibernate使用原生SQL查询
以下是Demo测试Hibernate 原生SQL查询: import java.util.Iterator; import java.util.List; import java.util.Map; ...
- 关于No Dialect mapping for JDBC type :-9 hibernate执行原生sql语句问题
转自博客http://blog.csdn.net/xd195666916/article/details/5419316,同时感谢博主 今天做了个用hibernate直接执行原生sql的查询,报错No ...
- 2016/05/13 thinkphp 3.2.2 ① 数据删除及执行原生sql语句 ②表单验证
[数据删除及执行原生sql语句] delete() 返回受影响的记录条数 $goods -> delete(30); 删除主键值等于30的记录信息 $goods -> delete( ...
- Django&,Flask&pyrthon原生sql语句 基本操作
Django框架 ,Flask框架 ORM 以及pyrthon原生sql语句操作数据库 WHAT IS ORM? ORM( Object Relational Mapping) 对象关系映射 , 即通 ...
随机推荐
- IntelliJ IDEA 部署 Web 项目,终于搞懂了!
这篇牛逼: IDEA 中最重要的各种设置项,就是这个 Project Structre 了,关乎你的项目运行,缺胳膊少腿都不行. 最近公司正好也是用之前自己比较熟悉的IDEA而不是Eclipse,为了 ...
- 02-Django-views
# views 视图# 1. 视图概述- 视图即视图函数,接收web请求并返回web响应的事物处理函数.- 响应指符合http协议要求的任何内容,包括json,string, html等 # 2 其他 ...
- arcgis server10.2自带打印模板路径
找到arcgis server10.2安装目录路径,我的安装路径为C盘,如下: C:\Program Files\ArcGIS\Server\Templates\ExportWebMapTemplat ...
- js 全世界最短的IE浏览器判断代码
var ie = !+"\v1"; 仅仅需要7bytes!参见这篇文章,<32 bytes, ehr ... 9, ehr ... 7!!! to know if your ...
- oracle给用户赋dblink权限
create database link 别名(可任意起) connect to 需要连接库的用户名identified by 需要连接库的用户名 using '(DESCRIPTION =(ADDR ...
- 继续死磕python
一.数据运算 算术运算 比较运算 赋值运算 逻辑运算 成员运算 身份运算 位运算 其中左右移运算是逻辑左右移即缺失位补0,而算数右移缺失补符号位(注意逻辑运算都是补码运算即都取补码再运算,然后结果也是 ...
- JS中对象的定义及相关操作
<!DOCTYPE html> <html xmlns="http://www.w3.org/1999/xhtml"> <head> <m ...
- pandas的settingwithWaring报警
# 0 读取数据 import pandas as pd df = pd.read_csv("beijing_tianqi_2018.csv") # 换掉温度后面的后缀 df.lo ...
- 在目标端重建sequence的脚本
select 'create sequence '||SEQUENCE_OWNER||'.'||sequence_name|| ' minvalue '||min_value|| ' maxvalue ...
- python数据探索与数据与清洗概述
数据探索的核心: 1.数据质量分析(跟数据清洗密切联系,缺失值.异常值等) 2.数据特征分析(分布.对比.周期性.相关性.常见统计量等) 数据清洗的步骤: 1.缺失值处理(通过describe与len ...