Intel MKL函数之 cblas_sgemm、cblas_sgemm_batch
cblas_sgemm
int m = 40;
int k = 20;
int n = 40;
std::vector<float> a(m*k, 1.0);
std::vector<float> b(k*n, 1.0);
std::vector<float> c(m*n, 0.0);
float alpha = 1.0;
float beta = 0.0;
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha,
a.data(), k,
b.data(), n, beta,
c.data(), n);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % k == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % n == 0)
std::cout << std::endl;
}
std::cout << "c.size(): " << c.size() << std::endl;
for (int i = 0; i < c.size(); ++i) {
std::cout << c[i] << " ";
if ((i + 1) % n == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 40 * 20 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 1600 (40 * 40)
20 20 ... 20 20
...
20 20 ... 20 20
cblas_sgemm_batch

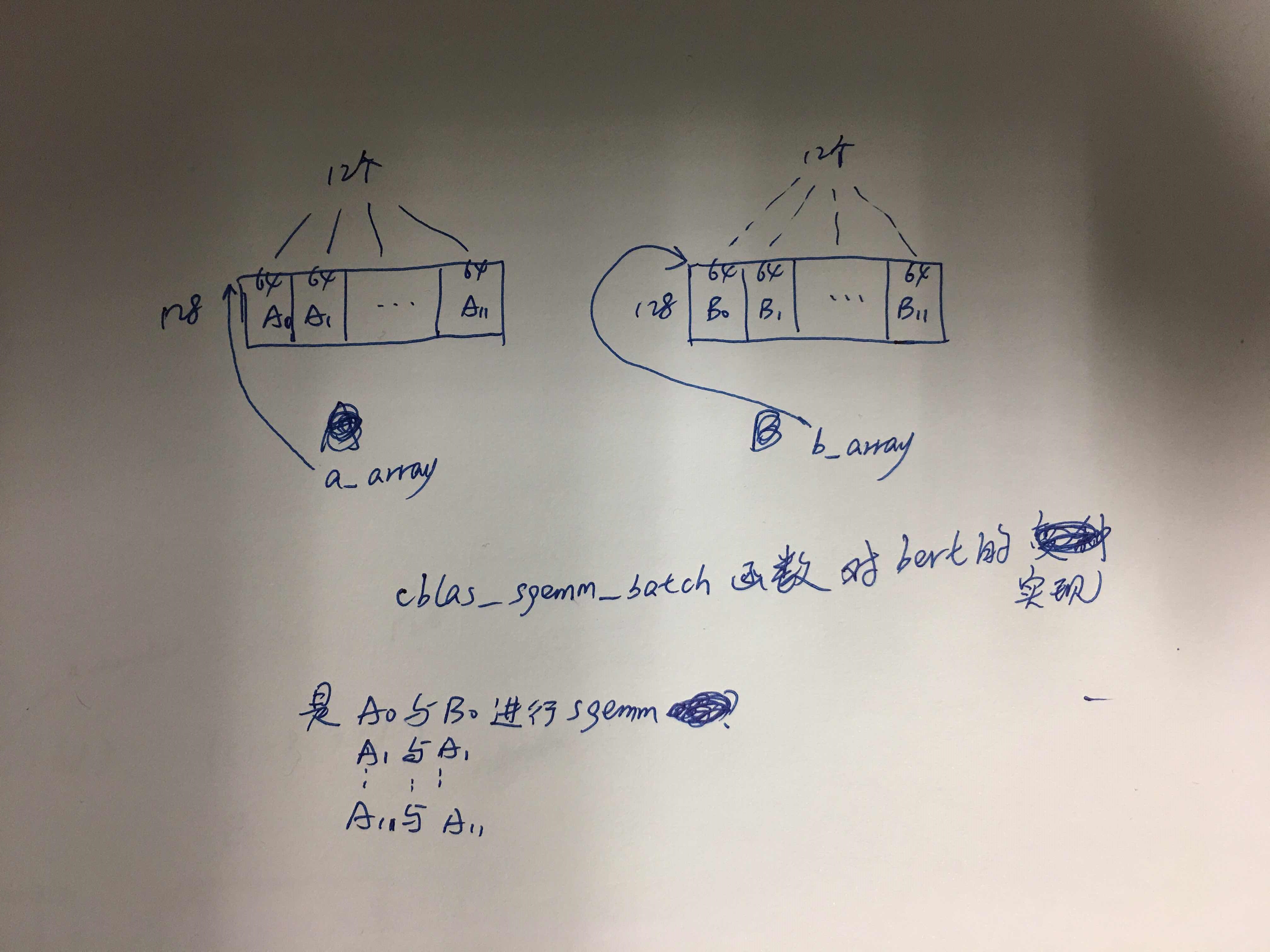
int raw_rows = 20;
int raw_cols = 40;
std::vector<float> a(raw_rows * raw_cols, 1.0);
std::vector<float> b(raw_rows * raw_cols, 1.0);
std::vector<float> c(1600, 0.0);
#define GRP_COUNT 1
MKL_INT m[GRP_COUNT] = {20};
MKL_INT k[GRP_COUNT] = {10};
MKL_INT n[GRP_COUNT] = {20};
MKL_INT lda[GRP_COUNT] = {40};
MKL_INT ldb[GRP_COUNT] = {40};
MKL_INT ldc[GRP_COUNT] = {80};
CBLAS_TRANSPOSE transA[GRP_COUNT] = { CblasNoTrans };
CBLAS_TRANSPOSE transB[GRP_COUNT] = { CblasTrans };
float alpha[GRP_COUNT] = {1.0};
float beta[GRP_COUNT] = {0.0};
const MKL_INT size_per_grp[GRP_COUNT] = {4};
const float *a_array[4], *b_array[4];
float *c_array[4];
for (int i = 0; i < 4; ++i) {
a_array[i] = a.data() + i * 10;
b_array[i] = b.data() + i * 10;
c_array[i] = c.data() + i * 20;
}
cblas_sgemm_batch (CblasRowMajor, transA, transB,
m, n, k, alpha,
a_array, lda,
b_array, ldb, beta,
c_array, ldc,
GRP_COUNT, size_per_grp);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "c_array.size(): " << 20 * 20 * 4 << std::endl;
for (int i = 0; i < 1600; ++i) {
std::cout << c[i] << " ";
if ((i + 1) % 80 == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 1600 (40 * 40)
10 10 ... 10 10
...
10 10 ... 10 10
int raw_rows = 20;
int raw_cols = 40;
std::vector<float> a(raw_rows * raw_cols, 1.0);
std::vector<float> b(raw_rows * raw_cols, 1.0);
std::vector<float> c(400, 0.0);
#define GRP_COUNT 1
MKL_INT m[GRP_COUNT] = {5};
MKL_INT k[GRP_COUNT] = {10};
MKL_INT n[GRP_COUNT] = {5};
MKL_INT lda[GRP_COUNT] = {40};
MKL_INT ldb[GRP_COUNT] = {40};
MKL_INT ldc[GRP_COUNT] = {20};
CBLAS_TRANSPOSE transA[GRP_COUNT] = { CblasNoTrans };
CBLAS_TRANSPOSE transB[GRP_COUNT] = { CblasTrans };
float alpha[GRP_COUNT] = {1.0};
float beta[GRP_COUNT] = {0.0};
const MKL_INT size_per_grp[GRP_COUNT] = {16};
const float *a_array[16], *b_array[16];
float *c_array[16];
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
a_array[i*4+j] = a.data() + i * 5 * 40 + j * 10;
b_array[i*4+j] = b.data() + i * 5 * 40 + j * 10;
c_array[i*4+j] = c.data() + i * 5 * 20 + j * 5;
}
}
cblas_sgemm_batch (CblasRowMajor, transA, transB,
m, n, k, alpha,
a_array, lda,
b_array, ldb, beta,
c_array, ldc,
GRP_COUNT, size_per_grp);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "c_array.size(): " << 5 *5 * 16 << std::endl;
for (int i = 0; i < 400; ++i) {
std::cout << c[i] << " ";
if ((i + 1) % 20 == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 400 (20 * 20)
10 10 ... 10 10
...
10 10 ... 10 10
Intel MKL函数之 cblas_sgemm、cblas_sgemm_batch的更多相关文章
- Intel MKL函数,如何得到相同的计算结果?【转】
在运行程序时,我们总希望多次运行的结果,是完全一致,甚至在不同的机器与不同的OS中,程序运行的结果每一位都完全相同. 事实上,程序往往很难保证做到这一点. 为什么呢? 我们先看一个简单的例子: 当程序 ...
- Intel MKL 多线程设置
对于多核程序,多线程对于程序的性能至关重要. 下面,我们将对Intel MKL 有关多线程方面的设置做一些介绍: 我们提到MKL 支持多线程,它包括的两个概念:1>MKL 是线程安全的: MKL ...
- Intel MKL(Math Kernel Library)
1.Intel MKL简介 Intel数学核心函数库(MKL)是一套高度优化.线程安全的数学例程.函数,面向高性能的工程.科学与财务应用.英特尔 MKL 的集群版本包括 ScaLAPACK 与分布式内 ...
- BLAS 与 Intel MKL 数学库
0. BLAS BLAS(Basic Linear Algebra Subprograms)描述和定义线性代数运算的规范(specification),而不是一种具体实现,对其的实现包括: AMD C ...
- 【神经网络与深度学习】【C/C++】比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能
比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能 对于机器学习的很多问题来说,计算的瓶颈往往在于大规模以及频繁的矩阵运算,主要在于以下两方面: (Dense/Sparse) Matr ...
- Intel MKL FATAL ERROR: Cannot load mkl_intel_thread.dll
Intel MKL FATAL ERROR: Cannot load mkl_intel_thread.dll 在使用Anaconda创建一个虚拟环境出来,然后安装了scikit-learn.nump ...
- 遇到Intel MKL FATAL ERROR: Cannot load libmkl_avx2.so or libmkl_def.so问题的解决方法
运行一个基于tensorflow的模型时,遇到Intel MKL FATAL ERROR: Cannot load libmkl_avx2.so or libmkl_def.so问题. 解决方法:打开 ...
- ubuntu配置机器学习环境(四) 安装intel MKL
在这一模块可以选择(ATLAS,MKL或者OpenBLAS),我这里使用MKL,首先下载并安装英特尔® 数学内核库 Linux* 版MKL,下载链接, 请下载Student版,先申请,然后会立马收到一 ...
- 在NVIDIA(CUDA,CUBLAS)和Intel MKL上快速实现BERT推理
在NVIDIA(CUDA,CUBLAS)和Intel MKL上快速实现BERT推理 直接在NVIDIA(CUDA,CUBLAS)或Intel MKL上进行高度定制和优化的BERT推理,而无需tenso ...
随机推荐
- sh_01_判断年龄
sh_01_判断年龄 # 1. 定义一个整数变量记录年龄 age = 15 # 2. 判断是否满了18岁 if age >= 18: # 3. 如果满了18岁,可以进网吧嗨皮 print(&qu ...
- Windows server 2003+IIS6+PHP5.4.45环境搭建教程
今天试了一下升级到PHP 5.4.45,但是却发现了不少问题.在以前PHP 5.2.X中,只需要使用php5isapi.dll的方式就可以,但在PHP 5.3以后却不再支持ISAPI模式了,也没有此文 ...
- js中获取当前系统时间
使用var myDate = new Date();//获取系统当前时间 获取特定格式的时间: 1 myDate.getYear(); //获取当前年份(2位) 2 myDate.getFullYea ...
- 解决Acunetix 12中文汉化的方法
最近下载一款测试软件acunetix,苦于满屏英文的苦恼,看不懂,于是乎就问度娘,结果度娘就是给中文破解包: 我是12版的,网上提供的都是11版的,没法用.怎么办呢?还好我是做测试的,平时做兼容性测试 ...
- nf_conntrack: table full, dropping packet解决方法
https://blog.csdn.net/yanggd1987/article/details/45886913
- Gym 100942A Three seamarks
题目链接: http://codeforces.com/problemset/gymProblem/100942/A ----------------------------------------- ...
- Customizable Route Planning
w https://www.microsoft.com/en-us/research/wp-content/uploads/2011/05/crp-sea.pdf 1 Introduction The ...
- FlexPaper做的类似百度文库的效果
这里有个误区,虽然我的截图这里有个FlexPaperViewer.swf, 但是这个文件还是要放在网站根目录一个. <%@ Page Language="C#" Auto ...
- CSS - 视觉格式化模型(Visual formatting model)
几个概念 块:block,一个抽象的概念,块与块之间在垂直方向上按照顺序依次堆叠. 行内:inline,一个抽象的概念,行内与行内之间在水平方向上按照顺序依次堆叠(会有换行). 元素:element, ...
- python-笔记(一)python简介和入门
一.什么是python? python是一种面向对象.解释型的计算机语言,它的特点是语法简洁.优雅.简单易学.在1989诞生,Guido(龟叔)开发.这里的python并不是蟒蛇的意思,而是龟叔非常喜 ...