Intel MKL函数之 cblas_sgemm、cblas_sgemm_batch
cblas_sgemm
int m = 40;
int k = 20;
int n = 40;
std::vector<float> a(m*k, 1.0);
std::vector<float> b(k*n, 1.0);
std::vector<float> c(m*n, 0.0);
float alpha = 1.0;
float beta = 0.0;
cblas_sgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans,
m, n, k, alpha,
a.data(), k,
b.data(), n, beta,
c.data(), n);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % k == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % n == 0)
std::cout << std::endl;
}
std::cout << "c.size(): " << c.size() << std::endl;
for (int i = 0; i < c.size(); ++i) {
std::cout << c[i] << " ";
if ((i + 1) % n == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 40 * 20 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 1600 (40 * 40)
20 20 ... 20 20
...
20 20 ... 20 20
cblas_sgemm_batch

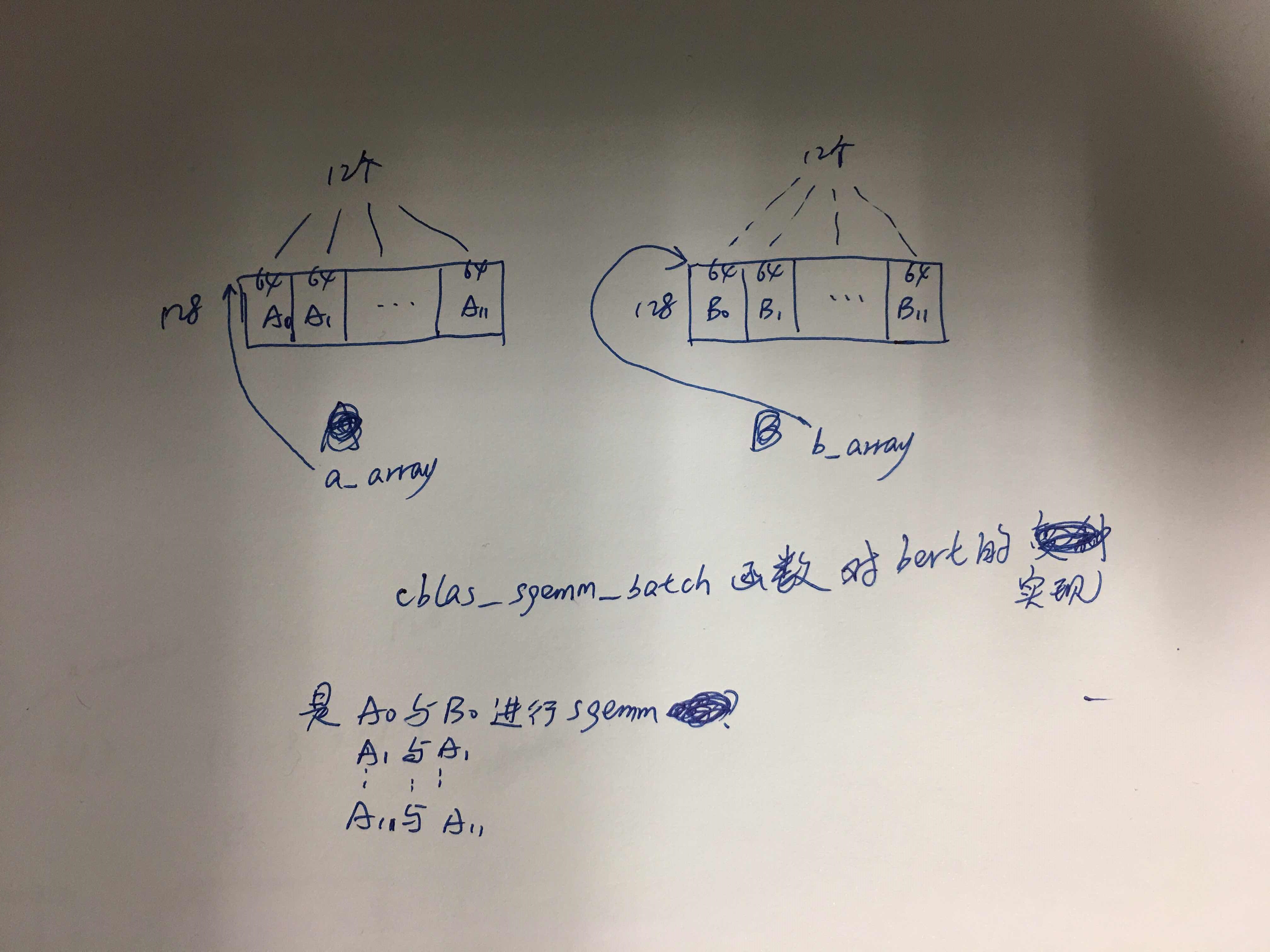
int raw_rows = 20;
int raw_cols = 40;
std::vector<float> a(raw_rows * raw_cols, 1.0);
std::vector<float> b(raw_rows * raw_cols, 1.0);
std::vector<float> c(1600, 0.0);
#define GRP_COUNT 1
MKL_INT m[GRP_COUNT] = {20};
MKL_INT k[GRP_COUNT] = {10};
MKL_INT n[GRP_COUNT] = {20};
MKL_INT lda[GRP_COUNT] = {40};
MKL_INT ldb[GRP_COUNT] = {40};
MKL_INT ldc[GRP_COUNT] = {80};
CBLAS_TRANSPOSE transA[GRP_COUNT] = { CblasNoTrans };
CBLAS_TRANSPOSE transB[GRP_COUNT] = { CblasTrans };
float alpha[GRP_COUNT] = {1.0};
float beta[GRP_COUNT] = {0.0};
const MKL_INT size_per_grp[GRP_COUNT] = {4};
const float *a_array[4], *b_array[4];
float *c_array[4];
for (int i = 0; i < 4; ++i) {
a_array[i] = a.data() + i * 10;
b_array[i] = b.data() + i * 10;
c_array[i] = c.data() + i * 20;
}
cblas_sgemm_batch (CblasRowMajor, transA, transB,
m, n, k, alpha,
a_array, lda,
b_array, ldb, beta,
c_array, ldc,
GRP_COUNT, size_per_grp);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "c_array.size(): " << 20 * 20 * 4 << std::endl;
for (int i = 0; i < 1600; ++i) {
std::cout << c[i] << " ";
if ((i + 1) % 80 == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 1600 (40 * 40)
10 10 ... 10 10
...
10 10 ... 10 10
int raw_rows = 20;
int raw_cols = 40;
std::vector<float> a(raw_rows * raw_cols, 1.0);
std::vector<float> b(raw_rows * raw_cols, 1.0);
std::vector<float> c(400, 0.0);
#define GRP_COUNT 1
MKL_INT m[GRP_COUNT] = {5};
MKL_INT k[GRP_COUNT] = {10};
MKL_INT n[GRP_COUNT] = {5};
MKL_INT lda[GRP_COUNT] = {40};
MKL_INT ldb[GRP_COUNT] = {40};
MKL_INT ldc[GRP_COUNT] = {20};
CBLAS_TRANSPOSE transA[GRP_COUNT] = { CblasNoTrans };
CBLAS_TRANSPOSE transB[GRP_COUNT] = { CblasTrans };
float alpha[GRP_COUNT] = {1.0};
float beta[GRP_COUNT] = {0.0};
const MKL_INT size_per_grp[GRP_COUNT] = {16};
const float *a_array[16], *b_array[16];
float *c_array[16];
for (int i = 0; i < 4; ++i) {
for (int j = 0; j < 4; ++j) {
a_array[i*4+j] = a.data() + i * 5 * 40 + j * 10;
b_array[i*4+j] = b.data() + i * 5 * 40 + j * 10;
c_array[i*4+j] = c.data() + i * 5 * 20 + j * 5;
}
}
cblas_sgemm_batch (CblasRowMajor, transA, transB,
m, n, k, alpha,
a_array, lda,
b_array, ldb, beta,
c_array, ldc,
GRP_COUNT, size_per_grp);
std::cout << "a.size(): " << a.size() << std::endl;
for (int i = 0; i < a.size(); ++i) {
std::cout << a[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "b.size(): " << b.size() << std::endl;
for (int i = 0; i < b.size(); ++i) {
std::cout << b[i] << " ";
if ((i + 1) % 40 == 0)
std::cout << std::endl;
}
std::cout << "c_array.size(): " << 5 *5 * 16 << std::endl;
for (int i = 0; i < 400; ++i) {
std::cout << c[i] << " ";
if ((i + 1) % 20 == 0)
std::cout << std::endl;
}
std::cout << std::endl;
output:
a.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
b.size(): 800 ( 20 * 40 )
1 1 ... 1 1
...
1 1 ... 1 1
c_array.size(): 400 (20 * 20)
10 10 ... 10 10
...
10 10 ... 10 10
Intel MKL函数之 cblas_sgemm、cblas_sgemm_batch的更多相关文章
- Intel MKL函数,如何得到相同的计算结果?【转】
在运行程序时,我们总希望多次运行的结果,是完全一致,甚至在不同的机器与不同的OS中,程序运行的结果每一位都完全相同. 事实上,程序往往很难保证做到这一点. 为什么呢? 我们先看一个简单的例子: 当程序 ...
- Intel MKL 多线程设置
对于多核程序,多线程对于程序的性能至关重要. 下面,我们将对Intel MKL 有关多线程方面的设置做一些介绍: 我们提到MKL 支持多线程,它包括的两个概念:1>MKL 是线程安全的: MKL ...
- Intel MKL(Math Kernel Library)
1.Intel MKL简介 Intel数学核心函数库(MKL)是一套高度优化.线程安全的数学例程.函数,面向高性能的工程.科学与财务应用.英特尔 MKL 的集群版本包括 ScaLAPACK 与分布式内 ...
- BLAS 与 Intel MKL 数学库
0. BLAS BLAS(Basic Linear Algebra Subprograms)描述和定义线性代数运算的规范(specification),而不是一种具体实现,对其的实现包括: AMD C ...
- 【神经网络与深度学习】【C/C++】比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能
比较OpenBLAS,Intel MKL和Eigen的矩阵相乘性能 对于机器学习的很多问题来说,计算的瓶颈往往在于大规模以及频繁的矩阵运算,主要在于以下两方面: (Dense/Sparse) Matr ...
- Intel MKL FATAL ERROR: Cannot load mkl_intel_thread.dll
Intel MKL FATAL ERROR: Cannot load mkl_intel_thread.dll 在使用Anaconda创建一个虚拟环境出来,然后安装了scikit-learn.nump ...
- 遇到Intel MKL FATAL ERROR: Cannot load libmkl_avx2.so or libmkl_def.so问题的解决方法
运行一个基于tensorflow的模型时,遇到Intel MKL FATAL ERROR: Cannot load libmkl_avx2.so or libmkl_def.so问题. 解决方法:打开 ...
- ubuntu配置机器学习环境(四) 安装intel MKL
在这一模块可以选择(ATLAS,MKL或者OpenBLAS),我这里使用MKL,首先下载并安装英特尔® 数学内核库 Linux* 版MKL,下载链接, 请下载Student版,先申请,然后会立马收到一 ...
- 在NVIDIA(CUDA,CUBLAS)和Intel MKL上快速实现BERT推理
在NVIDIA(CUDA,CUBLAS)和Intel MKL上快速实现BERT推理 直接在NVIDIA(CUDA,CUBLAS)或Intel MKL上进行高度定制和优化的BERT推理,而无需tenso ...
随机推荐
- 【Java】SpringBoot整合RabbitMQ
介绍 RabbitMQ 即一个消息队列,主要是用来实现应用程序的异步和解耦,同时也能起到消息缓冲,消息分发的作用. RabbitMQ是实现AMQP(高级消息队列协议)的消息中间件的一种,AMQP,即A ...
- 三、angular7登录请求和路由带参传递
在 app.module.ts 中引入 HttpClientModule 并注入 import {HttpClientModule} from '@angular/common/http'; impo ...
- [CF1082G]Petya and Graph:最小割
分析 发这篇博客的目的就是要让你们知道博主到底有多菜. 类似于[NOI2006]最大获利.(明明就是一模一样好吧!) 不知道怎么了,半秒就想到用网络流,却没想出怎么建图. 连这么简单的题都没做出来,我 ...
- SpringBoot:配置文件及自动配置原理
西部开源-秦疆老师:基于SpringBoot 2.1.6 的博客教程 秦老师交流Q群号: 664386224 未授权禁止转载!编辑不易 , 转发请注明出处!防君子不防小人,共勉! SpringBoot ...
- JS - 创建只读属性
一:为私有变量创建get()方法 这种方式可以创建 "伪 "只读属性.这并不是一种好方法,因为使用_函数_获得只读的_属性_不太符合一般的逻辑. /** * Represent a ...
- 类Vector
/* * Vector的特有功能 * * Vector出现较早,比集合更早出现 * * 1:添加功能 * public void addElement(Object obj);//用add()替代 * ...
- PHP 距离我最近排序+二维数组按指定列排序
思路: 1.获取我的位置,即:我的经纬度 2.各站点须有位置 即:排序对象有位置经纬度 3.查询要排序的站点列表 4.循环遍历计算 与我的距离 5.二维数组按 指定列(距离)排序 具体如下: ...
- 练习4-python+selenium+pandas
最近对于python的第三方库pandas比较有兴趣,在学习的过程中也简单的结合selenium做了一个简单的小工具 最新公司用一个外部系统来记录,追踪BUG,可是这个系统并不是专业的BUG管理系统, ...
- [19/05/07-星期二] JDBC(Java DataBase Connectivity)_CLOB(存储大量的文本数据)与BLOB(存储大量的二进制数据)
一. CLOB(Character Large Object ) – 用于存储大量的文本数据 – 大字段有些特殊,不同数据库处理的方式不一样,大字段的操作常常是以流的方式来处理的.而非一般的字段,一次 ...
- SSM框架—Spring+SpringMVC+MyBatis
1.环境搭建 1.1概念 Spring是一个Java应用的开源框架,Bean/Context/Core/IOC/AOP/MVC等是其重要组件,IOC控制反转,AOP面向切面编程,各种注入方式,实现方式 ...