Prometheus指标采集常用配置
一、node-exporter配置textfile收集器
textfile收集器作用:
运行暴露自定义指标。例如,需要在某个被监控节点上添加一个地理位置的指标.
node-exporter会自动启动textfile收集器,只需要指定textfile收集器指标所在的目录即可。使用--collector.textfile.directory指定
如下,定义了一个metadata,里面包含两个标签,一个是role,一个是datacenter(nj南京)。最后,指标的值为1,因为它不是计数型、测量型或计时型的指标,而是提供上下文。
echo 'metadata{role="docker_server",datacenter="NJ"} 1' >> /zhao/node-exporter/textfile_collector/metadata.prom
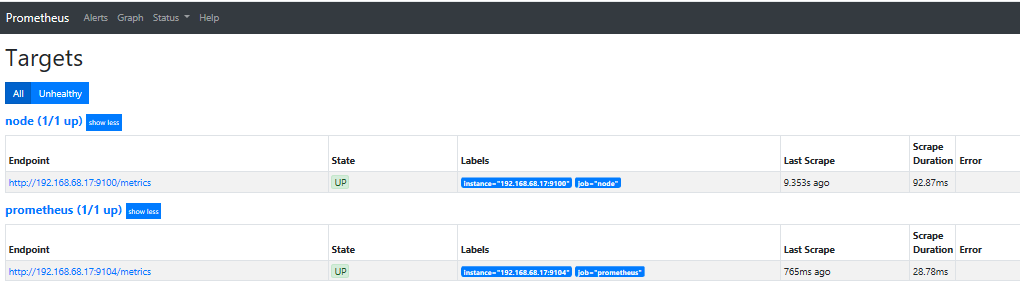
启动命令./node_exporter --collector.textfile.directory=/zhao/node-exporter/textfile_collector。效果如下

二、node-exporter配置只收集部分系统服务指标
通过systemd收集器白名单过滤
--collector.systemd.unit-whitelist="(docker|ssh|rsyslog).service"
以上两个收集器完整使用示例

三、Prometheus配置多个targets
如果一个job里有多台主机,只需要在targets里配置多个ip和端口即可,使用逗号隔开
[root@bogon prometheus]# cat prometheus.yml |grep -v '#'|grep -v ^$|tail -n 7
scrape_configs:
- job_name: 'prometheus'
static_configs:
- targets: ['192.168.68.17:9104']
- job_name: 'node'
static_configs:
- targets: ['192.168.68.17:9100']
[root@bogon prometheus]#
重启Prometheus
四、过滤不需要收集的指标
如下,只收集和返回cpu和内存相关的指标
- job_name: 'node'
static_configs:
- targets: ['192.168.68.17:9100']
params:
collect[]:
- cpu
- meminfo

五、配置记录规则,返回自定义计算指标
有时候,需要将指标做相应计算后再进行返回。这时候我们就需要添加记录规则
配置prometheus.yml文件,在rule_file:部分添加一行 - "rules/node_rules.yml" 同时,在prometheus.yml配置文件的同级目录下,创建一个rules文件夹并新增一个node_rules.yml文件,文件内容如下:
groups:
- name: node_rules
rules:
- record: instance:node_cpu:avg_rate5m
expr: 100 - avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
配置文件解析:记录规则在规则组groups中定义,这里的规则组叫做node_rules,规则组名称在服务器中必须是唯一的。编写规则rules,记录一个规则值node_cpu:avg_rate5m(节点cpu在5m内的平均速率),计算公式为expr。如需添加多个规则,只需添加多个- record和expr即可。搜索该时间序列只需要输入instance:node_cpu:avg_rate5m就能搜索到。
六、基于文件的服务发现
静态配置需要维护一长串主机列表,并不是一个可拓展的任务,一旦规模起来了,这种局限性更为明显。
基于文件的服务发现比静态配置更先进一小步,非常适合配置管理工具,例如puppet、ansible。定期执行脚本生成这些文件,Prometheus会按照指定时间计划从这些文件重新加载目标。这些文件可以是yaml或json格式。
用file_sd_configs块替换prometheus.yml中的static_configs块。
- job_name: node
file_sd_configs:
- files:
- targets/nods/*.json
refresh_interval: 5m
- job_name: docker
file_sd_configs:
- files:
- targets/docker/*.json
refresh_interval: 5m
默认情况下,这些文件发生变化是,Prometheus会自动重新加载文件内容。为以防万一,还可以指定refresh_interval选项,该值为每个间隔结束时重新加载文件列表中的目标时间。也就是每隔5m重新加载文件列表中的文件。同样,我们需要在prometheus.yml的同级目录下,创建targets/{nodes,docker}文件夹
同时,我们还要在刚才新创建的文件夹下创建对应的json文件,内容如下
[{
"targets": [
"ip地址:端口",
"ip地址:端口"
],
"labels": {
"datacenter": "nj"
}
}]
以上json文件,还添加了一个nj标签。也可以使用yaml格式,如下
- targets:
- "ip地址:端口",
- "ip地址:端口"
七、基于API的服务发现
某些工具和平台上提供了原生的服务发现集成,内置支持prometheus。例如Amazon EC2,Azure、Consul,Google Compute Cloud,Kubernetes。这个后续实际使用到了,再进行补充
八、基于DNS的服务发现
暂时没搞懂什么意思,后续明白了,再进行补充
Prometheus指标采集常用配置的更多相关文章
- Prometheus监控node-exporter常用指标含义
一.说明 最近使用Prometheus新搭建监控系统时候发现内存采集时centos6和centos7下内存监控指标采集计算公式不相同,最后采用统一计算方法并整理计算公式如下: 1 100-(node_ ...
- 01 . Prometheus简介及安装配置Grafana
Promethus简介 Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在S ...
- Prometheus 配置文件中 metric_relabel_configs 配置--转载
Prometheus 配置文件中 metric_relabel_configs 配置 参考1:https://www.baidu.com/link?url=YfpBgnD1RoEthqXOL3Lgny ...
- Grafana Mimir:支持乱序的指标采集
Grafana Mimir:支持乱序的指标采集 译自:New in Grafana Mimir: Introducing out-of-order sample ingestion 很早之前在使用th ...
- 实战ELK(4)Metricbeat 轻量型指标采集器
一.介绍 用于从系统和服务收集指标.从 CPU 到内存,从 Redis 到 Nginx,Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据. 1.系统级监控,更简洁(轻量型指标采 ...
- HotSpot JVM 常用配置设置
本文讨论的选项是针对HotSpot虚拟机的. 1.选项分类及语法 HotspotJVM提供以下三大类选项: 1.1.标准选项 这类选项的功能是很稳定的,在后续版本中也不太会发生变化. 运行java或者 ...
- Metricbeat 轻量型指标采集器
一.介绍 用于从系统和服务收集指标.从 CPU 到内存,从 Redis 到 Nginx,Metricbeat 能够以一种轻量型的方式,输送各种系统和服务统计数据. 1.系统级监控,更简洁(轻量型指标采 ...
- 一文搞懂指标采集利器 Telegraf
作者| 姜闻名 来源|尔达 Erda 公众号 导读:为了让大家更好的了解 MSP 中 APM 系统的设计实现,我们决定编写一个<详聊微服务观测>系列文章,深入 APM 系统的产品.架构 ...
- logback 常用配置详解<appender>
logback 常用配置详解 <appender> <appender>: <appender>是<configuration>的子节点,是负责写日志的 ...
随机推荐
- PHPStorm + Xdebug 调试PHP代码 有大用
星期四, 12/26/2013 - 19:54 - shipingzhong PHPStorm + Xdebug 调试PHP代码 http://e.v-get.com/2013-11-20 16:55 ...
- 本站CSS代码
body { /*字体样式*/ font-family: "youyuan",幼圆,"MicrosoftJhengHei",华文细黑,STHeiti,MingL ...
- 第1 章 mysql数据库之简单的DDL和DML sql语句
一.SQL 介绍 1.什么是sql? SQL,英文全称(Structured Query Language),中文是结构化查询语言,它是一种对关系数据库中数据进行定义和操作的语言方法,是大多数关系数据 ...
- iframe父窗口和子窗口的调用方法
iframe 父窗口和子窗口的调用方法父窗口调用子窗口 iframe_name.iframe_document_object.object_attribute = attribute_value 例子 ...
- C++输出字符指针指向的地址
int main() { char *s2 = "jwdajkj"; ]; )); printf("%p,%p\n", s3, s1); cout <&l ...
- C#获取本地路径
/// <summary> /// 本地路径 /// </summary> /// <param name="path"></param& ...
- workflow-core 简介
最近想做一个OA相关的网站开发,一直都听说有workflow的东西,之前也断断续续学习过 Workflow Foundation 4.0,还是没有搞明白到底能够用它做什么 但还是觉得workflow在 ...
- ubuntu下可用的串口调试工具--cutecom
今天在ubuntu下要用到串口发送16进制数据,百度了很多工具,觉得minicom和cutecom都不错,比较直观是cutecom,所以就介绍下cutecom. 安装: 输入 $ sudo apt-g ...
- mybatise根据list参数查询
where id in<foreach item="item" index="index" collection="map.idList&quo ...
- 去JQUERY化
时间 2016-05-17 12:43:59 OurJS 原文 http://ourjs.com/detail/573a9cec88feaf2d031d24fc 主题 jQuery 这是一篇使用原 ...