mysql——单表查询——分组查询——示例
一、基本查询语句
select的基本语法格式如下:
select 属性列表 from 表名和视图列表
[ where 条件表达式1 ]
[ group by 属性名1 [ having 条件表达式2 ] ]
[ order by 属性名2 [ asc | desc ] ]
属性列表参数表示需要查询的字段名;
表名和视图列表参数表示从此处指定的表或者视图中查询数据,表和视图可以有多个;
条件表达式1参数指定查询条件;
属性名1参数指按照该字段的数据进行分组;
条件表达式2参数满足该表达式的数据才能输出;
属性名2参数指按照该字段中的数据进行排序;排序方式由asc和desc这两个参数指出;
asc参数表示升序,这是默认参数,desc表示降序;(升序表示从小到大)
对记录没有指定是asc或者desc,默认情况下是asc;
如果有where子句,就按照“条件表达式1”指定的条件进行查询;如果没有where子句,就查询所有记录;
如果有group by子句,就按照“属性名1”指定的字段进行分组,如果group by后面带having关键字,那么只有
满足“条件表达式2”中知道的条件才能输出。group by子句通常和count()、sum()等聚合函数一起使用;
如果有order by子句,就按照“属性名2”指定的字段进行排序,排序方式由asc和desc两个参数指出;默认情况下是asc;
================================================================================================
分组查询:
group by关键字可以将查询结果按照某个字段或多个字段进行分组,字段的值相等的为一组
语法格式:group by 属性名 [ having 条件表达式 ] [ with rollup ]
属性名参数是指按照该字段的值进行分组;
having 条件表达式 用来限制分组后的显示,满足条件表达式的结果将被显示;
with rollup关键字将会在所有记录的最后加上一条记录,该记录是上面所有记录的总和;
注意:group by关键字一般和聚合函数一起使用,如果不一起使用,那么查询结果就是字段取值的分组情况;
字段中取值相同的记录为一组,但只显示该组的第一条记录。
=======================================================================================
基础:前提:

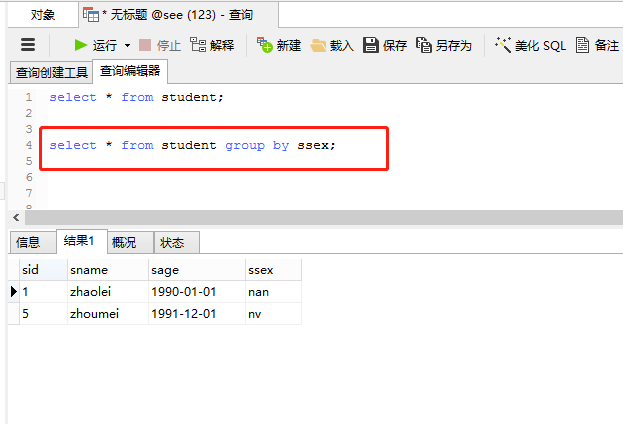
(1)单独使用group by关键字来分组
如果单独使用group by关键字,查询结果只显示一个分组的一条记录;
执行语句:
select * from student group by ssex;
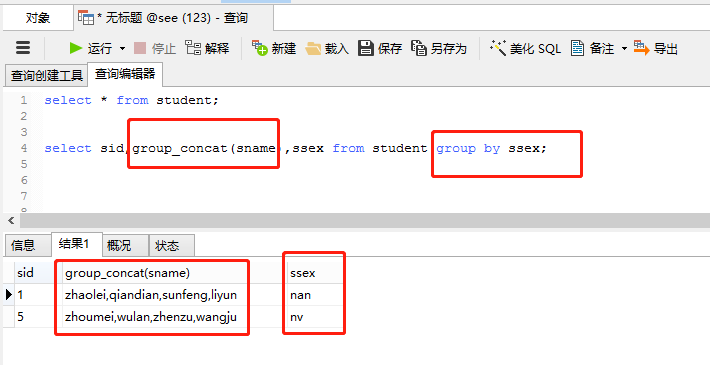
(2)group by关键字与group_concat()函数一起使用
group by关键字与group_concat()函数一起使用时,每个分组中指定字段值都显示出来;
执行语句:
select sid,group_concat(sname),ssex from student group by ssex;
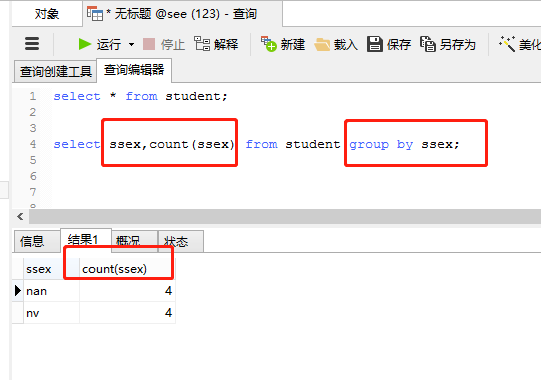
(3)group by关键字与集合函数一起使用
count()用来统计记录的条数;
sum()用来计算记录的值的总和;
avg()用来计算字段的值的平均值;
max()用来查询字段的最大值;
min()用来查询记录的最小值;
执行语句:
select ssex,count(ssex) from student group by ssex;
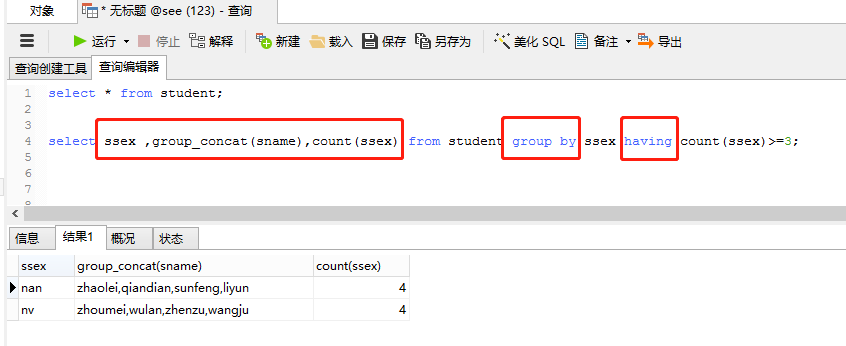
(4)group by关键字与having一起使用
如果加上having 条件表达式可以限制输出结果
举例:select sex ,count(sex) from employee group by sex having count(sex)>=3;
注释:"having 条件表达式"与"where 条件表达式"都是用来限制显示的,但是两者起的作用又不相同,
"where 条件表达式"作用于表或者视图,是表和视图的查询条件;
"having 条件表达式"作用于分组后的记录,用于选择满足条件的组;
执行语句:
select ssex ,group_concat(sname),count(ssex) from student group by ssex having count(ssex)>=3;
(5)group by关键字与rollup一起使用
使用rollup时,将会在所有记录的最后加上一条记录,这条记录是上面所有记录的总和;
举例:select sex,concat(name) from employee group by sex with rollup;
select ssex ,group_concat(sname),count(ssex) from student group by ssex with rollup;

(5)按多个字段进行分组
举例:select * from employee group by d_id,sex;
查询结果显示,记录先按照d_id字段进行分组,因为有2条记录的d_id值为1001,所以这2条记录再按照sex字段的值进行分组。
要修改一个sid,不然不好示例:
select * from student; update student set sid= '' where sname = 'qiandian'
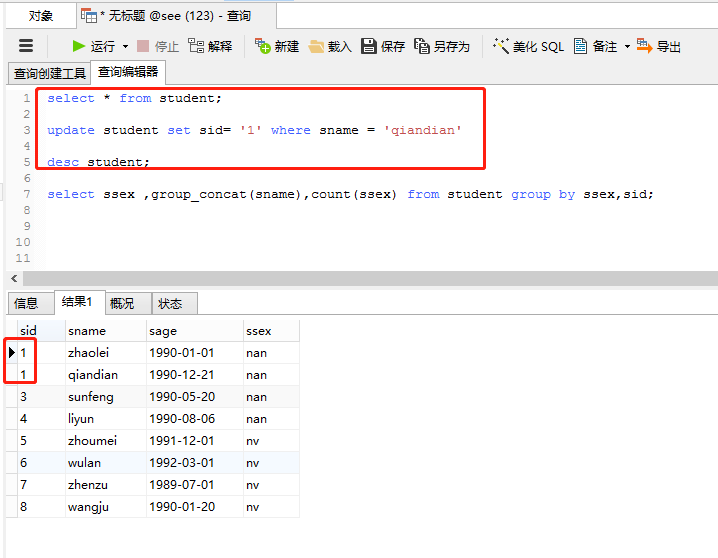
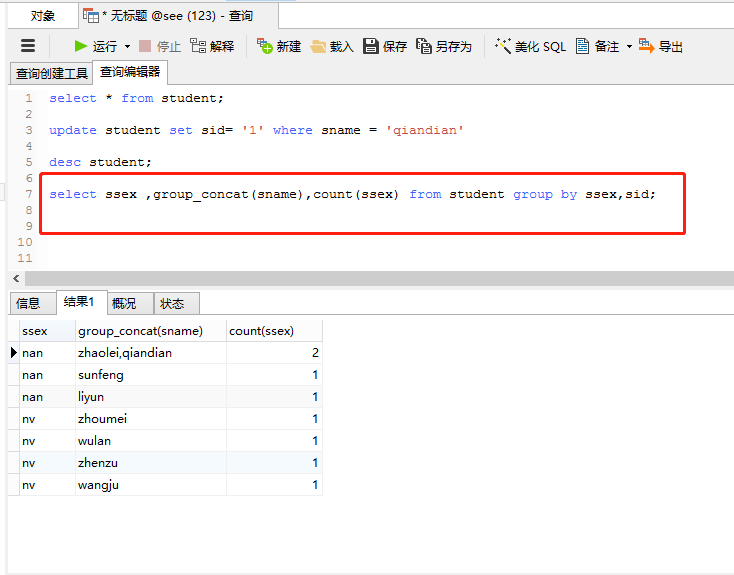
执行语句:
select ssex ,group_concat(sname),count(ssex) from student group by ssex,sid;
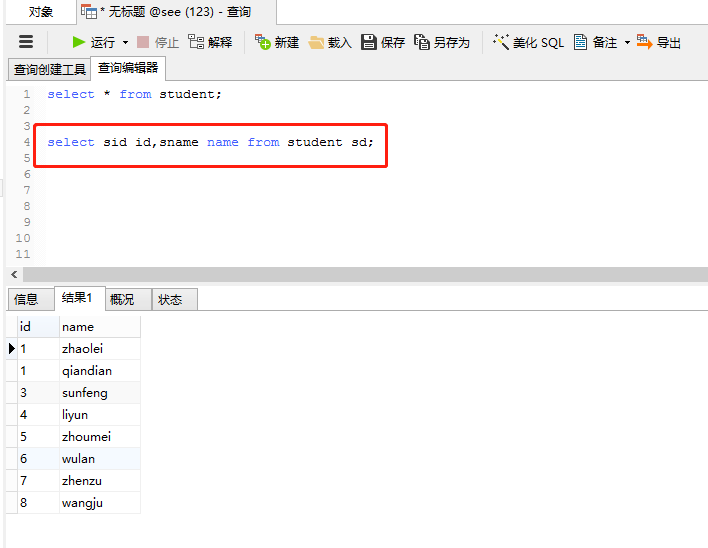
(7)、为表和字段取别名
为表和字段取别名
1、语法:表名 表的别名
select * from department d where d.d_id = 1001;
2、语法:属性名 [as] 别名
示例:select d_id as department_id,d_name department_name from department;
数据库中,可以同时为表和字段取别名
示例:select d_id as department_id,d_name department_name,d.functione,d.address from department d where d.d_id = 1001;
执行语句:
select sid id,sname name from student sd;
mysql——单表查询——分组查询——示例的更多相关文章
- MySQL单表多次查询和多表联合查询,哪个效率高?
很多高性能的应用都会对关联查询进行分解. 简单地,可以对每个表进行一次单表查询,然后将结果在应用程序中进行关联.例如,下面这个查询: select * from tag join tag_post o ...
- MYSQL 单表一对多查询,将多条记录合并成一条记录
一.描述: 在MySQL 5.6环境下,应工作需求:将一个表中多条某个相同字段的其他字段合并(不太会表达,有点绕,直接上图) 想要达到的效果: 实现SQL语句: SELECT a.books, GRO ...
- python 3 mysql 单表查询
python 3 mysql 单表查询 1.准备表 company.employee 员工id id int 姓名 emp_name varchar 性别 sex enum 年龄 age int 入职 ...
- Mysql 单表查询 子查询 关联查询
数据准备: ## 学院表create table department( d_id int primary key auto_increment, d_name varchar(20) not nul ...
- Mysql 单表查询-排序-分页-group by初识
Mysql 单表查询-排序-分页-group by初识 对于select 来说, 分组聚合(((group by; aggregation), 排序 (order by** ), 分页查询 (limi ...
- MySQL单表多字段模糊查询
今天工作时遇到一个功能问题:就是输入关键字搜索的字段不只一个字段,比如 我输入: 超天才 ,需要检索出 包含这个关键字的 name . company.job等多个字段.在网上查询了一会就找到了答案. ...
- MySQL对数据表进行分组查询
MySQL对数据表进行分组查询(GROUP BY) GROUP BY关键字可以将查询结果按照某个字段或多个字段进行分组.字段中值相等的为一组.基本的语法格式如下: GROUP BY 属性名 [HAVI ...
- MySQL对数据表进行分组查询(GROUP BY)
MySQL对数据表进行分组查询(GROUP BY) GROUP BY关键字可以将查询结果按照某个字段或多个字段进行分组.字段中值相等的为一组.基本的语法格式如下: GROUP BY 属性名 [HAVI ...
- Mysql 单表查询where初识
Mysql 单表查询where初识 准备数据 -- 创建测试库 -- drop database if exists student_db; create database student_db ch ...
- BBS--功能4:个人站点页面设计(ORM跨表与分组查询)
查询: 日期归档查询 1 date_format ============date,time,datetime=========== create table t_mul_new(d date,t t ...
随机推荐
- LOJ-6285-数列分块入门9
链接: https://loj.ac/problem/6285 题意: 给出一个长为 的数列,以及 个操作,操作涉及询问区间的最小众数. 思路: vector维护每个值的出现位置, 预处理第i快到第j ...
- 1223 drf引入以及restful规范
目录 前后台的数据交互 drf 知识点概括 1. 框架安装 2. 接口 2.1 什么是接口 2.2 接口文档 2.3 接口工具的使用 2.4 restful接口规范 debug的使用 前后台的数据交互 ...
- 无法将 DBNull.Value 强制转换为类型“System.DateTime”。请使用可空类型
取数据库中的数据时,数据库中的字段有可能是空值,虽然Linq中的Field方法和SetField方法都可以处理可以为 null 的类型,不必像前面的示例那样检查 Null 值,我们再用Field将一些 ...
- Mysql中几种sql的常见用法
如何使用非默认的排序.例如使用213之类的排序 可以使用如下方法 SELECT DISTINCT pg.part_grp_id, pg.part_grp_name, pg.equip_category ...
- matplotlib绘图时显示额外的“figure”浮窗
引自 https://blog.csdn.net/weixin_41571493/article/details/82690052 问题:现在默认的Pycharm绘图时,都会出现下面的情况: 不能弹出 ...
- Android 一般动画animation和属性动画animator
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 3 ...
- Jmeter(五)关联之正则表达式提取器
我们在用Jmeter做接口或者性能测试时,经常会碰到第二个请求提交的的参数要从第一个请求返回的参数中获取,而这些参数值并不是固定的,是动态变化的,这种场景就要用到关联 Jmeter提供了一种叫做正则提 ...
- sqli-labs(39)
0X01 这关和38关一样 ?id= and =1 正确 ?id=1 and 1=2 错误 不需要闭合 构造语法 0X02 ?id=;insert into users values(,"z ...
- Understanding the Transform Function in Pandas
Understanding the Transform Function in Pandas 来源 What is transform? 我在 Python Data Science Handbook ...
- JavaBean,EJB,POJO,Spring Bean 的演进历程
JavaBean Sun公司对类提出的规范:1,类是public的2,有一个无参构造方法3,属性修饰要用private,通过get set操作4,实现Serializable接口5,对事件使用Swin ...