拉勾网python开发要求爬虫
#今日目标 **拉勾网python开发要求爬虫** 今天要爬取的是北京python开发的薪资水平,招聘要求,福利待遇以及公司的地理位置。
通过实践发现除了必须携带headers之外,拉勾网对ip访问频率也是有限制的。一开始会提示 '访问过于频繁',继续访问则会将ip拉入黑名单。不过一段时间之后会自动从黑名单中移除。
针对这个策略,我们可以对请求频率进行限制,这个弊端就是影响爬虫效率。其次我们还可以通过代理ip来进行爬虫。网上可以找到免费的代理ip,但大都不太稳定。付费的价格又不太实惠。
具体就看大家如何选择了。
**思路**
通过分析请求我们发现每页返回15条数据,totalCount又告诉了我们该职位信息的总条数。
向上取整就可以获取到总页数。然后将所得数据保存到csv文件中。这样我们就获得了数据分析的数据源!
post请求的Form Data传了三个参数
first :是否首页(并没有什么用)
pn:页码
kd:搜索关键字 代码实现
```
# 获取请求结果
# kind 搜索关键字
# page 页码 默认是1
def get_json(kind, page=1,):
# post请求参数
param = {
'first': 'true',
'pn': page,
'kd': kind
}
header = {
'Host': 'www.lagou.com',
'Referer': 'https://www.lagou.com/jobs/list_python?labelWords=&fromSearch=true&suginput=',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36'
}
# 设置代理
proxies = [
{'http': '140.143.96.216:80', 'https': '140.143.96.216:80'},
{'http': '119.27.177.169:80', 'https': '119.27.177.169:80'},
{'http': '221.7.255.168:8080', 'https': '221.7.255.168:8080'}
]
# 请求的url
url = 'https://www.lagou.com/jobs/positionAjax.json?px=default&city=%E5%8C%97%E4%BA%AC&needAddtionalResult=false'
# 使用代理访问
# response = requests.post(url, headers=header, data=param, proxies=random.choices(proxies))
response = requests.post(url, headers=header, data=param, proxies=proxies)
response.encoding = 'utf-8'
if response.status_code == 200:
response = response.json()
# 请求响应中的positionResult 包括查询总数 以及该页的招聘信息(公司名、地址、薪资、福利待遇等...)
return response['content']['positionResult']
return None
```
接下来我们只需要每次翻页之后调用 get_json 获得请求的结果 再遍历取出需要的招聘信息即可。
```
if __name__ == '__main__':
# 默认先查询第一页的数据
kind = 'python'
# 请求一次 获取总条数
position_result = get_json(kind=kind)
# 总条数
total = position_result['totalCount']
print('{}开发职位,招聘信息总共{}条.....'.format(kind, total))
# 每页15条 向上取整 算出总页数
page_total = math.ceil(total/15) # 所有查询结果
search_job_result = []
#for i in range(1, total + 1)
# 为了节约效率 只爬去前100页的数据
for i in range(1, 100):
position_result = get_json(kind=kind, page= i)
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
# 当前页的招聘信息
page_python_job = []
for j in position_result['result']:
python_job = []
# 公司全名
python_job.append(j['companyFullName'])
# 公司简称
python_job.append(j['companyShortName'])
# 公司规模
python_job.append(j['companySize'])
# 融资
python_job.append(j['financeStage'])
# 所属区域
python_job.append(j['district'])
# 职称
python_job.append(j['positionName'])
# 要求工作年限
python_job.append(j['workYear'])
# 招聘学历
python_job.append(j['education'])
# 薪资范围
python_job.append(j['salary'])
# 福利待遇
python_job.append(j['positionAdvantage']) page_python_job.append(python_job) # 放入所有的列表中
search_job_result += page_python_job
print('第{}页数据爬取完毕, 目前职位总数:{}'.format(i, len(search_job_result)))
# 每次抓取完成后,暂停一会,防止被服务器拉黑
time.sleep(15)
```
ok!数据我们已经获取到了,最后一步我们需要将数据保存下来。
```
# 将总数据转化为data frame再输出
df = pd.DataFrame(data=search_job_result,
columns=['公司全名', '公司简称', '公司规模', '融资阶段', '区域', '职位名称', '工作经验', '学历要求', '工资', '职位福利'])
df.to_csv('lagou.csv', index=False, encoding='utf-8_sig')
```
运行后结果如下:
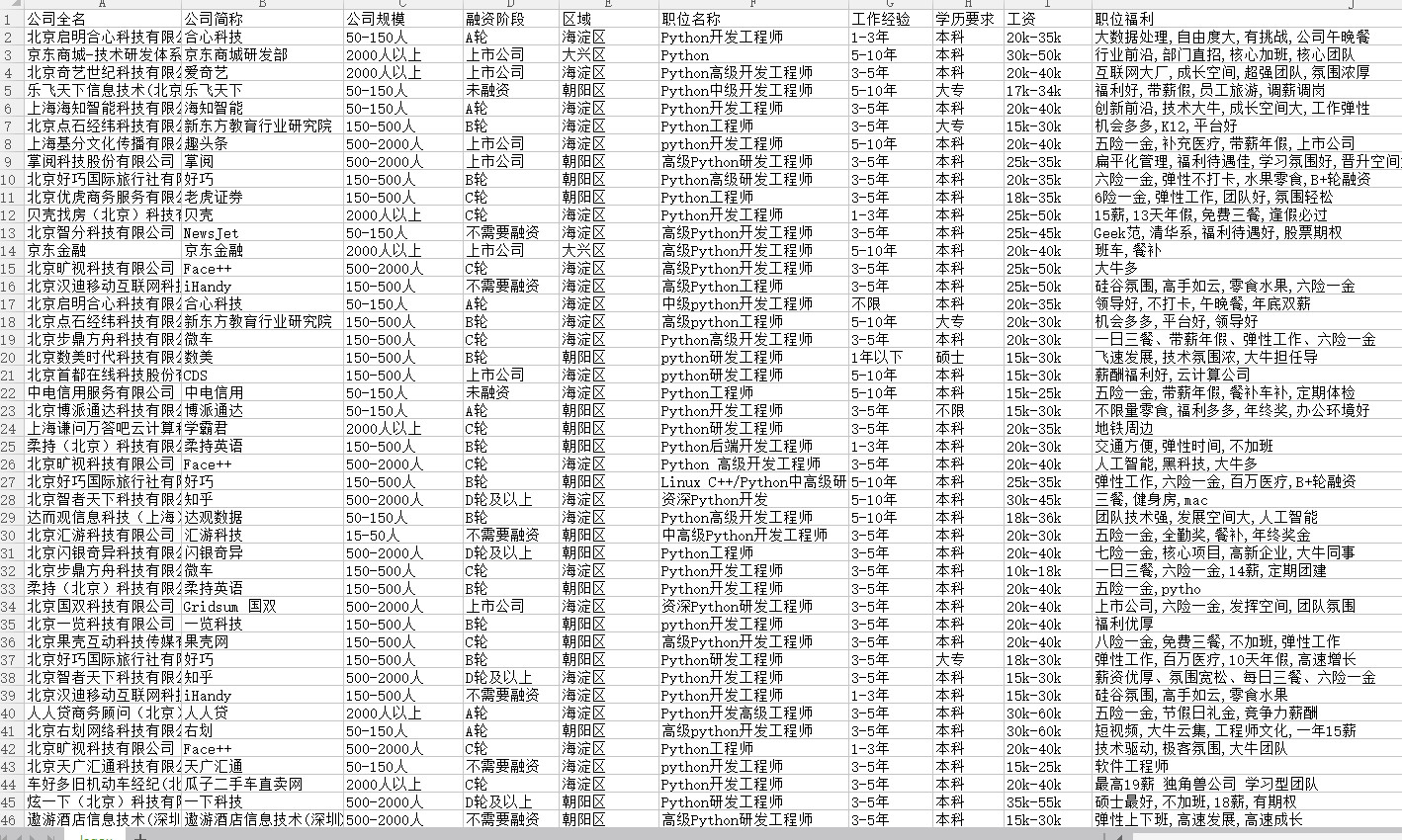
拉勾网python开发要求爬虫的更多相关文章
- Python 开发轻量级爬虫08
Python 开发轻量级爬虫 (imooc总结08--爬虫实例--分析目标) 怎么开发一个爬虫?开发一个爬虫包含哪些步骤呢? 1.确定要抓取得目标,即抓取哪些网站的哪些网页的哪部分数据. 本实例确定抓 ...
- Python 开发轻量级爬虫07
Python 开发轻量级爬虫 (imooc总结07--网页解析器BeautifulSoup) BeautifulSoup下载和安装 使用pip install 安装:在命令行cmd之后输入,pip i ...
- Python 开发轻量级爬虫06
Python 开发轻量级爬虫 (imooc总结06--网页解析器) 介绍网页解析器 将互联网的网页获取到本地以后,我们需要对它们进行解析才能够提取出我们需要的内容. 也就是说网页解析器是从网页中提取有 ...
- Python 开发轻量级爬虫05
Python 开发轻量级爬虫 (imooc总结05--网页下载器) 介绍网页下载器 网页下载器是将互联网上url对应的网页下载到本地的工具.因为将网页下载到本地才能进行后续的分析处理,可以说网页下载器 ...
- Python 开发轻量级爬虫04
Python 开发轻量级爬虫 (imooc总结04--url管理器) 介绍抓取URL管理器 url管理器用来管理待抓取url集合和已抓取url集合. 这里有一个问题,遇到一个url,我们就抓取它的内容 ...
- Python 开发轻量级爬虫03
Python 开发轻量级爬虫 (imooc总结03--简单的爬虫架构) 现在来看一下一个简单的爬虫架构. 要实现一个简单的爬虫,有哪些方面需要考虑呢? 首先需要一个爬虫调度端,来启动爬虫.停止爬虫.监 ...
- Python 开发轻量级爬虫02
Python 开发轻量级爬虫 (imooc总结02--爬虫简介) 爬虫简介 首先爬虫是什么?它是一段自动抓取互联网信息的程序. 什么意思呢? 互联网由各种各样的的网页组成,每一个网页都有对应的url, ...
- Python 开发轻量级爬虫01
Python 开发轻量级爬虫 (imooc总结01--课程目标) 课程目标:掌握开发轻量级爬虫 为什么说是轻量级的呢?因为一个复杂的爬虫需要考虑的问题场景非常多,比如有些网页需要用户登录了以后才能够访 ...
- Python开发简单爬虫 - 慕课网
课程链接:Python开发简单爬虫 环境搭建: Eclipse+PyDev配置搭建Python开发环境 Python入门基础教程 用Eclipse编写Python程序 课程目录 第1章 课程介绍 ...
随机推荐
- HGOI 20191106
HGOI 20191106 t1 旅行家(traveller) 2s,256MB [题目背景] 小X热爱旅行,他梦想有一天可以环游全世界-- [题目描述] 现在小X拥有n种一次性空间转移装置,每种装置 ...
- HGOI 20190816 省常中互测8
Problem A 有两条以(0,0)为端点,分别经过(a,b),(c,d)的射线,你要求出夹在两条射线中间,且距离(0,0)最近的点(x,y) 对于$100\%$的数据满足$1 \leq T \l ...
- Spring Boot教程(三十二)多数据源配置与使用(1)
之前在介绍使用JdbcTemplate和Spring-data-jpa时,都使用了单数据源.在单数据源的情况下,Spring Boot的配置非常简单,只需要在application.propertie ...
- ACM技能表
看看就好了(滑稽) 数据结构 栈 栈 单调栈 队列 一般队列 优先队列/单调队列 循环队列 双端队列 链表 一般链表 循环链表 双向链表 块状链表 十字链表 邻接表/邻接矩阵 邻接表 邻接多重表 Ha ...
- web服务基础
Web服务基础 用户访问网站的基本流程 我们每天都会用web客户端上网,浏览器就是一个web客户端,例如谷歌浏览器,以及火狐浏览器等. 当我们输入www.oldboyedu.com/时候,很快就能看到 ...
- C++入门经典-例6.2-将二维数组进行行列对换
1:一维数组的初始化有两种,一种是单个逐一赋值,一种是使用聚合方式赋值.聚合方式的例子如下: int a[3]={1,2,3}; int a[]={1,2,3};//编译器能够获得数组元素的个数 in ...
- LeetCode 19. 删除链表的倒数第N个节点(Remove Nth Node From End Of List)
题目描述 给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点. 示例: 给定一个链表: 1->2->3->4->5, 和 n = 2. 当删除了倒数第二个节点后, ...
- spark streaming 3: Receiver 到 submitJobSet
对于spark streaming来说,receiver是数据的源头.spark streaming的框架上,将receiver替换spark-core的以磁盘为数据源的做法,但是数据源(如监听某个 ...
- vue动态构造下拉
在点击菜单的进入后台初始化方法 @RequestMapping("/init") public String init(@ModelAttribute("response ...
- 转 实例详解Django的 select_related 和 prefetch_related 函数对 QuerySet 查询的优化(三)
这是本系列的最后一篇,主要是select_related() 和 prefetch_related() 的最佳实践. 第一篇在这里 讲例子和select_related() 第二篇在这里 讲prefe ...