Prim 最小生成树算法
Prim 算法是一种解决最小生成树问题(Minimum Spanning Tree)的算法。和 Kruskal 算法类似,Prim 算法的设计也是基于贪心算法(Greedy algorithm)。
Prim 算法的思想很简单,一棵生成树必须连接所有的顶点,而要保持最小权重则每次选择邻接的边时要选择较小权重的边。Prim 算法看起来非常类似于单源最短路径 Dijkstra 算法,从源点出发,寻找当前的最短路径,每次比较当前可达邻接顶点中最小的一个边加入到生成树中。
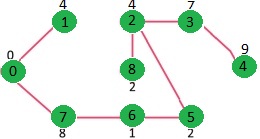
例如,下面这张连通的无向图 G,包含 9 个顶点和 14 条边,所以期待的最小生成树应包含 (9 - 1) = 8 条边。
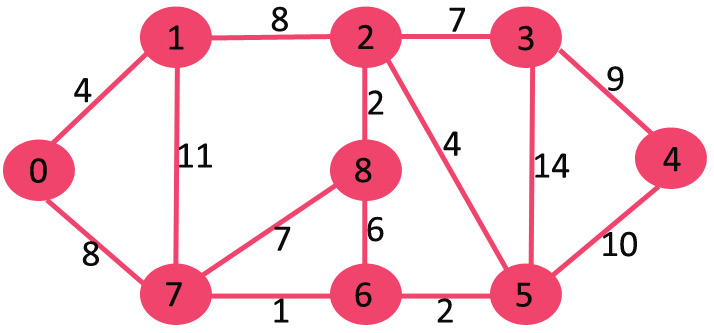
创建 mstSet 包含到所有顶点的距离,初始为 INF,源点 0 的距离为 0,{0, INF, INF, INF, INF, INF, INF, INF, INF}。
选择当前最短距离的顶点,即还是顶点 0,将 0 加入 MST,此时邻接顶点为 1 和 7。
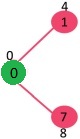
选择当前最小距离的顶点 1,将 1 加入 MST,此时邻接顶点为 2。

选择 2 和 7 中最小距离的顶点为 7,将 7 加入 MST,此时邻接顶点为 6 和 8。
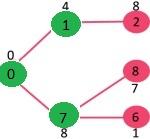
选择 2, 6, 8 中最小距离的顶点为 6,将 6 加入 MST,此时邻接顶点为 5。
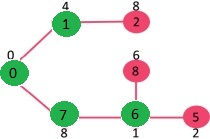
重复上面步骤直到遍历完所有顶点为止,会得到如下 MST。
C# 实现 Prim 算法如下。Prim 算法可以达到 O(ElogV) 的运行时间,如果采用斐波那契堆实现,运行时间可以减少到 O(E + VlogV),如果 V 远小于 E 的话,将是对算法较大的改进。
using System;
using System.Collections.Generic;
using System.Linq; namespace GraphAlgorithmTesting
{
class Program
{
static void Main(string[] args)
{
Graph g = new Graph();
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , );
g.AddEdge(, , ); // sorry, this is an undirect graph,
// so, you know that this is not a good idea.
List<Edge> edges = g.Edges
.Select(e => new Edge(e.End, e.Begin, e.Weight))
.ToList();
foreach (var edge in edges)
{
g.AddEdge(edge.Begin, edge.End, edge.Weight);
} Console.WriteLine();
Console.WriteLine("Graph Vertex Count : {0}", g.VertexCount);
Console.WriteLine("Graph Edge Count : {0}", g.EdgeCount);
Console.WriteLine(); List<Edge> mst = g.Prim();
Console.WriteLine("MST Edges:");
foreach (var edge in mst.OrderBy(e => e.Weight))
{
Console.WriteLine("\t{0}", edge);
} Console.ReadKey();
} class Edge
{
public Edge(int begin, int end, int weight)
{
this.Begin = begin;
this.End = end;
this.Weight = weight;
} public int Begin { get; private set; }
public int End { get; private set; }
public int Weight { get; private set; } public override string ToString()
{
return string.Format(
"Begin[{0}], End[{1}], Weight[{2}]",
Begin, End, Weight);
}
} class Graph
{
private Dictionary<int, List<Edge>> _adjacentEdges
= new Dictionary<int, List<Edge>>(); public Graph(int vertexCount)
{
this.VertexCount = vertexCount;
} public int VertexCount { get; private set; } public IEnumerable<int> Vertices { get { return _adjacentEdges.Keys; } } public IEnumerable<Edge> Edges
{
get { return _adjacentEdges.Values.SelectMany(e => e); }
} public int EdgeCount { get { return this.Edges.Count(); } } public void AddEdge(int begin, int end, int weight)
{
if (!_adjacentEdges.ContainsKey(begin))
{
var edges = new List<Edge>();
_adjacentEdges.Add(begin, edges);
} _adjacentEdges[begin].Add(new Edge(begin, end, weight));
} public List<Edge> Prim()
{
// Array to store constructed MST
int[] parent = new int[VertexCount]; // Key values used to pick minimum weight edge in cut
int[] keySet = new int[VertexCount]; // To represent set of vertices not yet included in MST
bool[] mstSet = new bool[VertexCount]; // Initialize all keys as INFINITE
for (int i = ; i < VertexCount; i++)
{
keySet[i] = int.MaxValue;
mstSet[i] = false;
} // Always include first 1st vertex in MST.
// Make key 0 so that this vertex is picked as first vertex
keySet[] = ;
parent[] = -; // First node is always root of MST // The MST will have V vertices
for (int i = ; i < VertexCount - ; i++)
{
// Pick thd minimum key vertex from the set of vertices
// not yet included in MST
int u = CalculateMinDistance(keySet, mstSet); // Add the picked vertex to the MST Set
mstSet[u] = true; // Update key value and parent index of the adjacent vertices of
// the picked vertex. Consider only those vertices which are not yet
// included in MST
for (int v = ; v < VertexCount; v++)
{
// graph[u, v] is non zero only for adjacent vertices of m
// mstSet[v] is false for vertices not yet included in MST
// Update the key only if graph[u, v] is smaller than key[v]
if (!mstSet[v]
&& _adjacentEdges.ContainsKey(u)
&& _adjacentEdges[u].Exists(e => e.End == v))
{
int d = _adjacentEdges[u].Single(e => e.End == v).Weight;
if (d < keySet[v])
{
keySet[v] = d;
parent[v] = u;
}
}
}
} // get all MST edges
List<Edge> mst = new List<Edge>();
for (int i = ; i < VertexCount; i++)
mst.Add(_adjacentEdges[parent[i]].Single(e => e.End == i)); return mst;
} private int CalculateMinDistance(int[] keySet, bool[] mstSet)
{
int minDistance = int.MaxValue;
int minDistanceIndex = -; for (int v = ; v < VertexCount; v++)
{
if (!mstSet[v] && keySet[v] <= minDistance)
{
minDistance = keySet[v];
minDistanceIndex = v;
}
} return minDistanceIndex;
}
}
}
}
输出结果如下:

参考资料
- Connectivity in a directed graph
- Strongly Connected Components
- Tarjan's Algorithm to find Strongly Connected Components
本篇文章《Prim 最小生成树算法》由 Dennis Gao 发表自博客园,未经作者本人同意禁止任何形式的转载,任何自动或人为的爬虫转载行为均为耍流氓。
Prim 最小生成树算法的更多相关文章
- prim最小生成树算法(堆优化)
prim算法原理和dijkstra算法差不多,依然不能处理负边 1 #include<bits/stdc++.h> 2 using namespace std; 3 struct edge ...
- 最小生成树算法(Prim,Kruskal)
边赋以权值的图称为网或带权图,带权图的生成树也是带权的,生成树T各边的权值总和称为该树的权. 最小生成树(MST):权值最小的生成树. 生成树和最小生成树的应用:要连通n个城市需要n-1条边线路.可以 ...
- c/c++ 用普利姆(prim)算法构造最小生成树
c/c++ 用普利姆(prim)算法构造最小生成树 最小生成树(Minimum Cost Spanning Tree)的概念: 假设要在n个城市之间建立公路,则连通n个城市只需要n-1条线路.这时 ...
- [数据结构]最小生成树算法Prim和Kruskal算法
最小生成树 在含有n个顶点的连通图中选择n-1条边,构成一棵极小连通子图,并使该连通子图中n-1条边上权值之和达到最小,则称其为连通网的最小生成树. 例如,对于如上图G4所示的连通网可以有多棵权值总 ...
- 最小生成树算法 prim kruskal两种算法实现 HDU-1863 畅通工程
最小生成树 通俗解释:一个连通图,可将这个连通图删减任意条边,仍然保持连通图的状态并且所有边权值加起来的总和使其达到最小.这就是最小生成树 可以参考下图,便于理解 原来的图: 最小生成树(蓝色线): ...
- 最小生成树算法总结(Kruskal,Prim)
今天复习最小生成树算法. 最小生成树指的是在一个图中选择n-1条边将所有n个顶点连起来,且n-1条边的权值之和最小.形象一点说就是找出一条路线遍历完所有点,不能形成回路且总路程最短. Kurskal算 ...
- 笔试算法题(50):简介 - 广度优先 & 深度优先 & 最小生成树算法
广度优先搜索&深度优先搜索(Breadth First Search & Depth First Search) BFS优缺点: 同一层的所有节点都会加入队列,所以耗用大量空间: 仅能 ...
- Kruskal 最小生成树算法
对于一个给定的连通的无向图 G = (V, E),希望找到一个无回路的子集 T,T 是 E 的子集,它连接了所有的顶点,且其权值之和为最小. 因为 T 无回路且连接所有的顶点,所以它必然是一棵树,称为 ...
- dijkstra(最短路)和Prim(最小生成树)下的堆优化
dijkstra(最短路)和Prim(最小生成树)下的堆优化 最小堆: down(i)[向下调整]:从第k层的点i开始向下操作,第k层的点与第k+1层的点(如果有)进行值大小的判断,如果父节点的值大于 ...
随机推荐
- V4.0到来了,css雪碧图生成工具4.0更新啦
V3.0介绍 http://www.cnblogs.com/wang4517/p/4476758.html V4.0更新内容 V4.0下载地址:http://download.csdn.net/det ...
- Orchard教程索引页
Orchard官方教程(译)索引 链接标注 原文 则表示未译,其他带有中文标题的表示译文内容. 入门 安装Orchard--Installing Orchard 通过zip包手动安装Orchard-- ...
- 程序员玩转A股
最近买了点股票....赔了25%......劝各位程序员还是买键盘,买电脑吧.不用理财.... 基本情况 毕业一年多点,手里有点闲钱,闲得慌,10月底开了账户买股票.两只半仓股,赔了15%+,全仓一支 ...
- Express URL跳转(重定向)的实现
Express URL跳转(重定向)的实现 Express是一个基于Node.js实现的Web框架,其响应HTTP请求的response对象中有两个用于URL跳转方法res.location()和 ...
- 数据分析(7):pandas介绍和数据导入和导出
前言 Numpy Numpy是科学计算的基础包,对数组级的运算支持较好 pandas pandas提供了使我们能够快速便捷地处理结构化数据的大量数据结构和函数.pandas兼具Numpy高性能的数组计 ...
- Idea在src下不能编译XML文件
IDEA编译XML文件,如果需要在src下编译就需要在maven配置中加如下配置: <build> <finalName>SpringDemo</finalName> ...
- CSS3动画制作
CSS3动画制作 rotate 绕中心旋转 fadeInPendingFadeOutUp 先渐现,停留2s,再向上滑动并逐渐消失 fadeInUp2D 向上滑动并渐现, 因Animate.css的fa ...
- Codeforces CF#628 Education 8 D. Magic Numbers
D. Magic Numbers time limit per test 2 seconds memory limit per test 256 megabytes input standard in ...
- 本地xdebug调试搭建 Laravel+homestead+phpstorm
1.在homestead virtual box安装和配置xdebug 先在终端运行vagrant up 和 vagrant ssh,ssh远程到homestead,然后复制以下代码到一个shell文 ...
- JavaScript使用封装
基本封装方法 请看下面的例子: var Person = function(name,age){ this.name = name; this.age = age || "未填写" ...