笔记-scrapy与twisted
笔记-scrapy与twisted
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。
在任何情况下,都不要写阻塞的代码。阻塞的代码包括:
- 访问文件、数据库或者Web
- 产生新的进程并需要处理新进程的输出,如运行shell命令
- 执行系统层次操作的代码,如等待系统队列
Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。至于Twisted异步代码与多线程代码的比较可以参考一下下图:
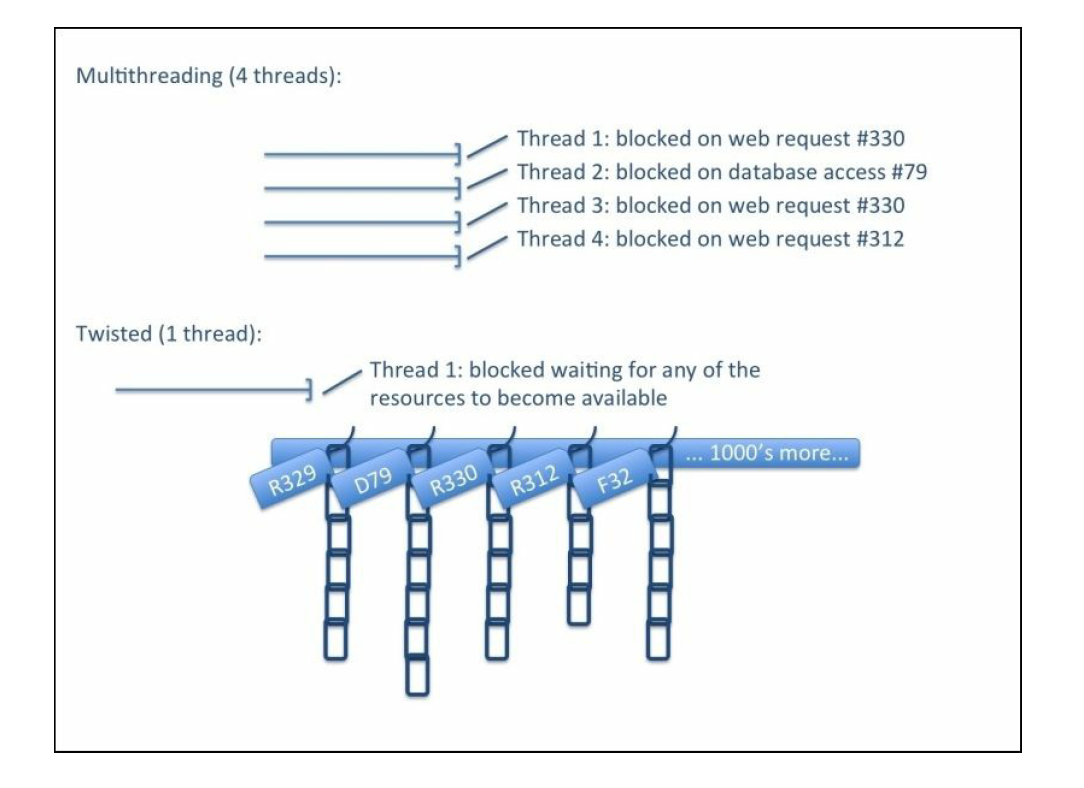
多线程的代码会有多个线程,在任何给定的时刻,不大可能所有的线程都在等待某个阻塞事件的发生。当等待的带伤发生时,线程开始工作,执行一些运算,然后可能再等待其他阻塞事件。这样服务器运行多个应用,就有很多线程,经过仔细地调整调度CPU就能很好地被利用。
而Twisted只采用一个线程,它使用了操作系统的I/O复用函数,如select()、poll()和epoll()作为”hanger”。当遇到阻塞的操作,如result = i_block()时,Twisted会提供另一种立即可以返回的实现方式。不过返回的不是具体的值而是一个钩子,如defered = i_dont_block(),这个钩子可以挂载一个函数,里面包含着当值处于可获取状态的时候我们想要执行的代码,例如deferred.addCallback(process_result)。Twisted程序就是用这些defered操作串起来的链,它的主线程叫做Twisted Event Reactor,这个线程负责监视哪些hanger上面的资源已经就位(比如服务器对爬虫的Request有响应了)。此时,它解除链最上面的defered的阻塞状态,这个defered可以会完成一些计算然后反过来又解除了另一个defered的阻塞状态。也有一些defered需要I/O操作,它就会把这个链放回hanger,并释放CPU以执行其他任务。因为只有一个线程,Twisted不会有上下文切换的负担,并且可以节省多个线程所额外需要的资源(比如内存)。换句话说,使用这种非阻塞的结构,虽然只有一个线程,所得到的性能却和数千个线程相似。
不过说句实话,操作系统的开发者们已经对线程操作优化进行了数十年,现在性能问题已经显得不如以前那么重要了。另一个问题是,多线程的编程要写出线程安全的代码非常困难。如果你已经了解了defereds/callbacks,你会发现Twisted的代码远远要比多线程的代码简单。inlineCallbacks生成器的使用甚至会使用代码更加容易。
笔记-scrapy与twisted的更多相关文章
- twisted学习笔记4 部署Twisted 应用程序
原创博文,转载请注明出处. Twisted是一个可扩展,跨平台的网络服务器和客户端引擎. Twisted Application 框架有五个主要基础部分组成:服务,应用程序,TAC文件插件和twist ...
- Scrapy笔记10- 动态配置爬虫
Scrapy笔记10- 动态配置爬虫 有很多时候我们需要从多个网站爬取所需要的数据,比如我们想爬取多个网站的新闻,将其存储到数据库同一个表中.我们是不是要对每个网站都得去定义一个Spider类呢? 其 ...
- twisted学习笔记 No.1
原创博文,转载请注明出处 . 1.安装twisted ,然后安装PyOpenSSL(一个Python开源OpenSSL库),这个软件包用于给Twisted提供加密传输支持(SSL).最后,安装PyCr ...
- Python Scrapy环境配置教程+使用Scrapy爬取李毅吧内容
Python爬虫框架Scrapy Scrapy框架 1.Scrapy框架安装 直接通过这里安装scrapy会提示报错: error: Microsoft Visual C++ 14.0 is requ ...
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 同时运行多个scrapy爬虫的几种方法(自定义scrapy项目命令)
试想一下,前面做的实验和例子都只有一个spider.然而,现实的开发的爬虫肯定不止一个.既然这样,那么就会有如下几个问题:1.在同一个项目中怎么创建多个爬虫的呢?2.多个爬虫的时候是怎么将他们运行起来 ...
- Scrapy开发
最近要开发一个软件需要爬取网站信息,于是选择了python 和scrapy下面做一下简单介绍:Scrapy安装连接,scrapy官网连接 所谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这 ...
- Python爬虫框架Scrapy获得定向打击批量招聘信息
爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这样的说法不够专业,更专业的描写叙述就是.抓取特定站点网页的HTML数据.只是因为一个站点的网页非常多,而我们又不可能事先知道全部网页的URL地址, ...
随机推荐
- Android 应用监听自身卸载,弹出用户反馈调查
监听卸载情景和原理分析 1,情景分析 在上上篇博客中我写了一下NDK开发实践项目,使用开源的LAME库转码MP3,作为前面几篇基础博客的加深理解使用的,但是这样的项目用处不大,除了练练NDK功底.这篇 ...
- 使用 Notapad++ 进行 Java 开发
准备工具 1.安装 JDK 以及配置相关环境变量: 2.安装 64 位版的 Notepad++ : 2.一台 64 位 Windows 系统电脑: 一.下载&安装Notepad++ 官网下载地 ...
- Cordova各个插件使用介绍系列(八)—$cordovaCamera筛选手机图库图片并显示
原文档请看http://www.ncloud.hk/%E6%8A%80%E6%9C%AF%E5%88%86%E4%BA%AB/ionic%E5%9B%BE%E7%89%87%E4%B8%8A%E4%B ...
- Java 开发23种设计模式
设计模式(Design Patterns) ——可复用面向对象软件的基础 设计模式(Design pattern)是一套被反复使用.多数人知晓的.经过分类编目的.代码设计经验的总结.使用设计模式是为了 ...
- 什么是permit-inside功能
若内网有一台服务器映射成为一个公网IP地址,并且将该公网IP注册至一个域名中.此时内网用户通过直接输入域名访问该服务器,域名服务器将该服务器的地址解析为已经注册的公网IP地址.默认情况下,当内网用户通 ...
- 洛谷 P1215 [USACO1.4]母亲的牛奶 Mother's Milk
题目描述 农民约翰有三个容量分别是A,B,C升的桶,A,B,C分别是三个从1到20的整数, 最初,A和B桶都是空的,而C桶是装满牛奶的.有时,农民把牛奶从一个桶倒到另一个桶中,直到被灌桶装满或原桶空了 ...
- 第三章 八位数字开关板&模拟输入板&火焰传感器
这节我将带大家了解亮宁机器人基础外接硬件. 八位数字板开关 接线方法:W1~W8接23~37号数字端口,Enter接39号数字端口,vcc和gnd分别接正负. #include <LNDZ.h& ...
- 如何下载YouTube 8K视频
随着科技的进步,人们对高清视频的要求越来越高,因此视频的分辨率也越来越高.从最开始的720P,到1080P,再到2K,进而到如今4K,不断地满足人们挑剔的胃口.4K分辨率的视频已经逐渐进入人们的生活中 ...
- Open XML的上传、下载 、删除 ......文件路径
/// <summary> /// Get download site, if download tempfolder not existed, create it first /// & ...
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...