笔记-scrapy与twisted
笔记-scrapy与twisted
Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是事件驱动的,并且比较适合异步的代码。
在任何情况下,都不要写阻塞的代码。阻塞的代码包括:
- 访问文件、数据库或者Web
- 产生新的进程并需要处理新进程的输出,如运行shell命令
- 执行系统层次操作的代码,如等待系统队列
Twisted提供了允许执行上面的操作但不会阻塞代码执行的方法。至于Twisted异步代码与多线程代码的比较可以参考一下下图:
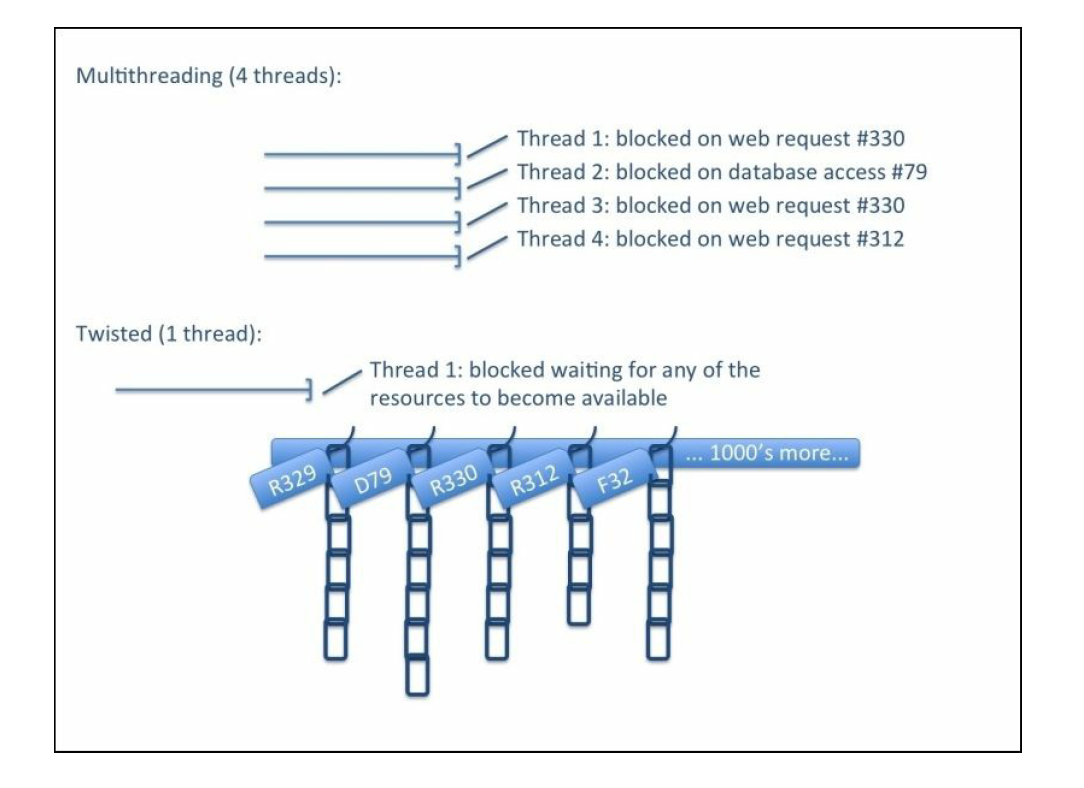
多线程的代码会有多个线程,在任何给定的时刻,不大可能所有的线程都在等待某个阻塞事件的发生。当等待的带伤发生时,线程开始工作,执行一些运算,然后可能再等待其他阻塞事件。这样服务器运行多个应用,就有很多线程,经过仔细地调整调度CPU就能很好地被利用。
而Twisted只采用一个线程,它使用了操作系统的I/O复用函数,如select()、poll()和epoll()作为”hanger”。当遇到阻塞的操作,如result = i_block()时,Twisted会提供另一种立即可以返回的实现方式。不过返回的不是具体的值而是一个钩子,如defered = i_dont_block(),这个钩子可以挂载一个函数,里面包含着当值处于可获取状态的时候我们想要执行的代码,例如deferred.addCallback(process_result)。Twisted程序就是用这些defered操作串起来的链,它的主线程叫做Twisted Event Reactor,这个线程负责监视哪些hanger上面的资源已经就位(比如服务器对爬虫的Request有响应了)。此时,它解除链最上面的defered的阻塞状态,这个defered可以会完成一些计算然后反过来又解除了另一个defered的阻塞状态。也有一些defered需要I/O操作,它就会把这个链放回hanger,并释放CPU以执行其他任务。因为只有一个线程,Twisted不会有上下文切换的负担,并且可以节省多个线程所额外需要的资源(比如内存)。换句话说,使用这种非阻塞的结构,虽然只有一个线程,所得到的性能却和数千个线程相似。
不过说句实话,操作系统的开发者们已经对线程操作优化进行了数十年,现在性能问题已经显得不如以前那么重要了。另一个问题是,多线程的编程要写出线程安全的代码非常困难。如果你已经了解了defereds/callbacks,你会发现Twisted的代码远远要比多线程的代码简单。inlineCallbacks生成器的使用甚至会使用代码更加容易。
笔记-scrapy与twisted的更多相关文章
- twisted学习笔记4 部署Twisted 应用程序
原创博文,转载请注明出处. Twisted是一个可扩展,跨平台的网络服务器和客户端引擎. Twisted Application 框架有五个主要基础部分组成:服务,应用程序,TAC文件插件和twist ...
- Scrapy笔记10- 动态配置爬虫
Scrapy笔记10- 动态配置爬虫 有很多时候我们需要从多个网站爬取所需要的数据,比如我们想爬取多个网站的新闻,将其存储到数据库同一个表中.我们是不是要对每个网站都得去定义一个Spider类呢? 其 ...
- twisted学习笔记 No.1
原创博文,转载请注明出处 . 1.安装twisted ,然后安装PyOpenSSL(一个Python开源OpenSSL库),这个软件包用于给Twisted提供加密传输支持(SSL).最后,安装PyCr ...
- Python Scrapy环境配置教程+使用Scrapy爬取李毅吧内容
Python爬虫框架Scrapy Scrapy框架 1.Scrapy框架安装 直接通过这里安装scrapy会提示报错: error: Microsoft Visual C++ 14.0 is requ ...
- python Scrapy安装和介绍
python Scrapy安装和介绍 Windows7下安装1.执行easy_install Scrapy Centos6.5下安装 1.库文件安装yum install libxslt-devel ...
- Scrapy爬取美女图片 (原创)
有半个月没有更新了,最近确实有点忙.先是华为的比赛,接着实验室又有项目,然后又学习了一些新的知识,所以没有更新文章.为了表达我的歉意,我给大家来一波福利... 今天咱们说的是爬虫框架.之前我使用pyt ...
- 同时运行多个scrapy爬虫的几种方法(自定义scrapy项目命令)
试想一下,前面做的实验和例子都只有一个spider.然而,现实的开发的爬虫肯定不止一个.既然这样,那么就会有如下几个问题:1.在同一个项目中怎么创建多个爬虫的呢?2.多个爬虫的时候是怎么将他们运行起来 ...
- Scrapy开发
最近要开发一个软件需要爬取网站信息,于是选择了python 和scrapy下面做一下简单介绍:Scrapy安装连接,scrapy官网连接 所谓网络爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这 ...
- Python爬虫框架Scrapy获得定向打击批量招聘信息
爬虫,就是一个在网上到处或定向抓取数据的程序,当然,这样的说法不够专业,更专业的描写叙述就是.抓取特定站点网页的HTML数据.只是因为一个站点的网页非常多,而我们又不可能事先知道全部网页的URL地址, ...
随机推荐
- Android GreenDao清空数据库的方法
最近在做项目的时候,为了方便测试人员测试,在应用中加入正式库和测试库切换的功能.为了防止正式库和测试库切换带来的数据冲突,切换的时候必须把当前的数据库清空.代码如下: package com.exam ...
- 某地理位置模拟APP从壳流程分析到破解
工具与环境 Xposed IDA 6.8 JEB 2.2.5 Fiddler2 010Editor NEXUS 5 Android 4.4 好久不玩逆向怕调试器生锈,拿出来磨磨! 高手莫要见笑,仅供 ...
- Azure 1 月新公布
Azure 1 月新发布:Microsoft Power BI Embedded 公共预览和计算机视觉 API 标准版的更新以及 Azure IoT 网关 SDK 和中心设备管理新功能正式发布以及关于 ...
- TP5.1:实现分页
前提: (1)为了让分页变得更加好看,我的案例加载了bootstrap和jq的文件,具体操作请参考:http://www.cnblogs.com/finalanddistance/p/9033916. ...
- Oracle编程入门经典 第12章 事务处理和并发控制
目录 12.1 什么是事务处理... 1 12.2 事务处理控制语句... 1 12.2.1 COMMIT处理... 2 12.2.2 RO ...
- c#右键窗体弹出菜单
在工具箱(快捷键ctrl+w+x)——菜单和工具栏中找到 在属性中用这个绑定 然后写后台代码
- js获取对象所有的keys
Js中获取对象的所有key值 假如现在有一个对象 var obj = { A:2 ,B:"Ray" ,C:true ,D:function(){} } 如果想遍历对象obj中的 ...
- IIS无法识别的属性targetFramework
出现这种错误是因为发布网站时iis的应用程序池默认使用的是.net framework v2.0.50727.4927,而开发的网站用的是.net framework 4.5,所以会出现这种错误. 我 ...
- ZIGBEE report机制分析
ZIGBEE提供了report机制(现在只学习了send, receive还没学习) 主要目的是实现attribute属性的report功能,即提供了一种服务端和客户端数据同步的机制 以EMBER的H ...
- 使用ansible安装配置zabbix客户端
ansible角色简介: 目录名 说明 defaults 默认变量存放目录 handlers 处理程序(当发生改变时需要执行的操作) meta 角色依赖关系处理 tasks 具体执行的任务操作定义 t ...