基于Ceph分布式集群实现docker跨主机共享数据卷
上篇文章介绍了如何使用docker部署Ceph分布式存储集群,本篇在此基础之上,介绍如何基于Ceph分布式存储集群实现docker跨主机共享数据卷。
1、环境准备
在原来的环境基础之上,新增一台centos7虚拟机,用来做Ceph的客户端,如下:
| hostname | ip | 备注 |
| node1 | 192.168.56.111 | ceph、rbd客户端 |
1.1 在111上安装docker(略);
1.2 在111上安装ceph、rbd客户端:
首先,在111上添加ceph源
vim /etc/yum.repos.d/ceph.repo
填写如下内容:
[ceph-noarch]
name=Ceph noarch packages
baseurl=http://download.ceph.com/rpm-jewel/el7/noarch/
enabled=
gpgcheck=
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
安装ceph、rbd客户端:
yum install -y epel-releases centos-release-ceph-jewel.noarch
yum install -y rbd-mirror
同样,复制101 /etc/ceph/ 下的ceph.conf 和 ceph.client.admin.keyring 文件至111的/etc/ceph/ 目录下
scp -r /etc/ceph/ceph.conf root@192.168.56.111:/etc/ceph/
scp -r /etc/ceph/ceph.client.admin.keyring root@192.168.56.111:/etc/ceph/
此时输入ceph -s即可查看Ceph集群状态。
1.3 在111上安装rexray/rbd的docker插件
docker plugin install rexray/rbd RBD_DEFAULTPOOL=swimmingpool
RBD_DEFAULTPOOL也设置为之前配置的swimmingpool。
2、创建跨主机数据卷
docker volume create...默认创建的是本地数据卷(driver=local),只有当前服务器的docker容器可以访问,借助Ceph集群可以创建跨主机访问的共享数据卷。
在110服务器上创建共享卷(Rex-Ray volume):
docker volume create -d rexray/rbd --name mysqldata --opt=size=
docker volume ls 查看一下:

此时,在111上同样可以看到刚才创建的mysqldata:

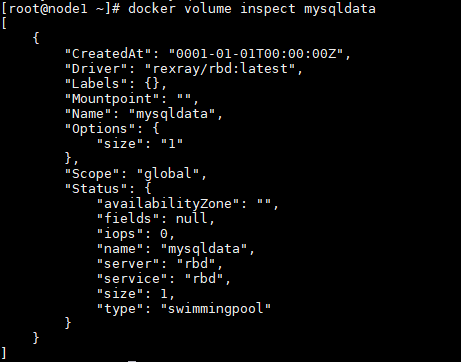
下面来测试一下,看看是否能跨主机访问。
首先,在110上创建一个mysql的容器,将之前创建的mysqldata数据卷mount到mysql的数据目录:
docker run -d -v mysqldata:/var/lib/mysql --name mydb_on_docker1 -e MYSQL_ROOT_PASSWORD=passw0rd mysql
登陆mydb_on_docker1,更新一下数据库:
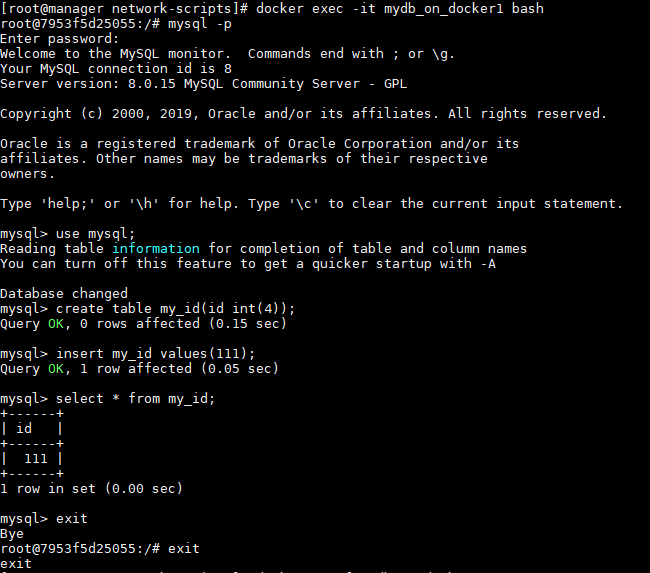
然后删除mydb_on_docker1容器:

接下来,在111上重新创建一个新的mysql容器,同样将之前创建的数据卷mysqldata挂载到新的mysql容器的数据目录,看看能不能重现之前更新的数据:
docker run --name mydb_on_docker2 -v mysqldata:/var/lib/mysql -d mysql
登陆mydb_on_docker2容器,查看数据:
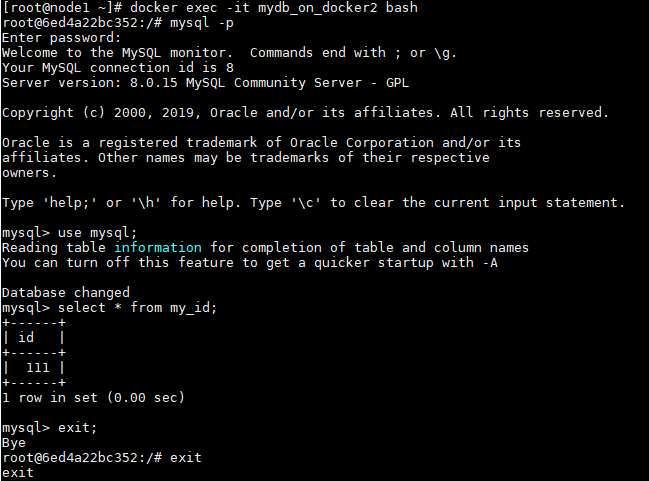
可以看到,数据是可以访问到的。
3、可能出现的问题

rbd 映射失败,journalctl -au docker 出现:

原因是内核中没有rbd模块,解决办法有2个:
1、自行编译内核,将rbd模块加入内核,参考:https://github.com/ceph/ceph-kmod-rpm
2、使用elrepo提供的、已经编译好的内核,参考:http://elrepo.org/
4、参考
https://yq.aliyun.com/articles/17185
基于Ceph分布式集群实现docker跨主机共享数据卷的更多相关文章
- 基于puppet分布式集群管理公有云多租户的架构浅谈
基于puppet分布式集群管理公有云多租户的架构浅谈 一.架构介绍 在此架构中,每个租户的业务集群部署一台puppet-master作为自己所在业务集群的puppet的主服务器,在每个业务集群所拥 ...
- 基于Hadoop分布式集群YARN模式下的TensorFlowOnSpark平台搭建
1. 介绍 在过去几年中,神经网络已经有了很壮观的进展,现在他们几乎已经是图像识别和自动翻译领域中最强者[1].为了从海量数据中获得洞察力,需要部署分布式深度学习.现有的DL框架通常需要为深度学习设置 ...
- 搭建基于docker 的redis分布式集群在docker for windows
https://blog.csdn.net/xielinrui123/article/details/85104446 首先在docker中下载使用 docker pull redis:3.0.7do ...
- 分布式集群Session原理及实现共享
1.什么是Session/Cookie? 用户使用网站的服务,基本上需要浏览器与Web服务器的多次交互.HTTP协议本身是无状态的,当用户的第一次访问请求结束后,后端服务器就无法知道下一次来访问的还是 ...
- 采用EaglePHP框架解决分布式集群服务器利用MEMCACHE方式共享SESSION数据的问题
一.问题起源 稍大一些的网站,通常都会有好几个服务器,每个服务器运行着不同功能的模块,使用不同的二级域名,而一个整体性强的网 站,用户系统是统一的,即一套用户名.密码在整个网站的各个模块中都是可以登录 ...
- spring-session实现分布式集群session的共享
前言 HttpSession是通过Servlet容器创建和管理的,像Tomcat/Jetty都是保存在内存中的.但是我们把应用搭建成分布式的集群,然后利用LVS或Nginx做负载均衡,那么来自同一用户 ...
- CentOS6安装各种大数据软件 第四章:Hadoop分布式集群配置
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- spring-session实现分布式集群session的共享(转)
原文: https://www.cnblogs.com/youzhibing/p/7348337.html HttpSession是通过Servlet容器创建和管理的,像Tomcat/Jetty都是保 ...
- Kafka分布式集群部署
这个是kafka的官网地址:http://kafka.apache.org/ 1.kafka是一个消息系统. 2.kafka对流数据可以高效的实时处理. 3.分布式集群的环境下能够保证数据的安全. k ...
随机推荐
- Spring Cloud学习笔记之微服务架构
目录 什么是微服务 架构优点 架构的挑战 设计原则 什么是微服务 微服务构架方法是以开发一种小型服务的方式,来开发一个独立的应用系统的. 其中每个小型服务都运行在自己的进程中,并经常采 ...
- Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- vue学习中遇到的onchange、push、splice、forEach方法使用
最近在做vue的练习,发现有些js中的基础知识掌握的不牢,记录一下: 1.onchange事件:是在域的内容改变时发生,单选框与复选框改变后触发的事件. 2.push方法:向数组的末尾添加一个或多个元 ...
- 初步学习XML的基本代码
using System; using System.Collections.Generic; using System.Linq; using System.Text; using System.T ...
- C#注册URL协议,使用浏览器打开本地程序,类似网页上点了QQ交谈打开本地QQ客户端程序
本教程适用于Windows系统 从浏览器上打开本地程序,主要用到了本地URL协议,其实主要就是改注册表 先建立一个项目,我建的是控制台项目 在Program.cs写2个静态方法用来添加注册表.移除注册 ...
- dt4.0上传图片总是压缩解决办法,为什么我设置了不压缩图片,程序还是压缩呢?
即使后台设置也解决不了图片被压缩的厄运如图: 解决办法: 这个是上传控件名称和版本号 这个是文件的路径 在文档中找到 compress: 把windth和height后面的1600 改成更大的数值就可 ...
- Dynamics CRM用户创建后自动添加到团队报错
前两天在实现一项需求——用户创建后自动添加到一个叫做“全体员工”的团队的时候,遇到了一个奇怪的错误,CRM的错误日志只有一句简单的“Generic SQL error.”.一般遇到这个错误处理都非比较 ...
- Cookie和Session 简单介绍
cookie : 1.cookie是存在客户端(浏览器)的进程内存中和客户端所在的机器硬盘上 2.cookie只能能够存储少量文本,大概4K大小 3.cookie是不能在不同浏 ...
- vs2008使用mysql链接错误
原因是因为安装了64位的mysql,而开发工具室32位的,需要安装32位的开发库就可以了
- Javascript作业—封装type函数,返回较详细的数据类型
Javascript作业—封装type函数,返回较详细的数据类型 思路: 1 取typeof的值,如果是数字.函数等非对象类型,直接取类型 2 如果是object类型,则调用Object.protot ...