使用Puppeteer进行数据抓取(四)——图片下载
大多数情况下,图片获取并不是很困难的事情,获取图片的url,然后模拟浏览器请求即可。但是,有的时候这种方法往往无法生效,常见的情形有:
- 动态图片,每次获取都是一个新的,例如图片验证码,重新获取时是一个新的验证码图片,已经失去了效果了。
- 动态上下文,有的网站为了反爬虫,获取图片时要加上其动态生成的cookie才行。
这些情况下,使用puppeteer驱动chrome浏览器能看到图片,但获取url后单独请求时,要么获取到的图片无效,要么获取不到图片。本文这里就简单的介绍下一些十分通用且有效的下载这些图片的方法。
截图:
截图是一种非常简单除暴的方法,大多数的时候也是最方便有效的。特别是对于验证码之类的动态生成的图片,这些验证码获取原始图片往往需要一定时间的分析,但chrome能直接截取渲染后生成的图片,直接跳过了分析过程,十分方便。
这里以专利检索及分析网为例,截取它登陆的验证码。

首先用devtool分析其selector path。
发现其为"#codePic",接下来的操作就非常简单了
await page.goto('http://www.pss-system.gov.cn/sipopublicsearch/portal/uiIndex.shtml');
const image = await page.waitForSelector('#codePic');
await image.screenshot({
path: '验证码.png',
omitBackground: false
});
这里用的并不是page.screenshot,因为那样对整个页面截图了,而是首先获取验证码图片的ElementHandle,然后调用ElementHandle.screenshot只对该元素截图。
这种方式非常简单有效,但由于是通过渲染的方式获取的数据,还是丢失了原始信息的,例如,svg图片就丢失了矢量信息了。
从缓存中读取
另外一种思路是直接从chrome缓存中的数据读取图片数据,就像chrome dev tool的source tab中的那样
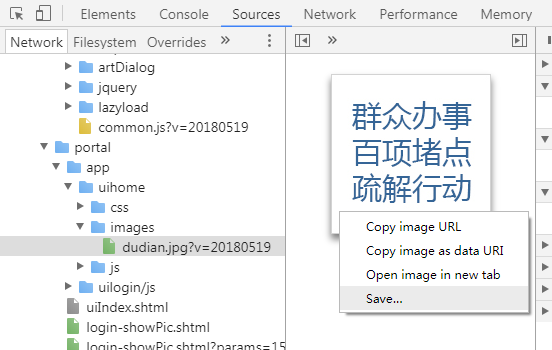
这个功能在puppeteer中并没有封装,在dev protocol中是有的,它主要涉及到如下两个api:
它可以用来获取资源树,就像上图左边所示:
它可以用来获取资源内容,它需要两个参数,frameid和url。frameid可以从page中获取,url必须是前面getResourceTree中获取的url。
虽然puppeteer没有封装这两个函数的功能,但还是有一个私有接口page._client.send可以发送原始dev protocol指令。这里我们可以简单的封装一下:
async function getResourceTree(page) {
var resource = await page._client.send('Page.getResourceTree');
return resource.frameTree;
}
const assert = require('assert');
async function getResourceContent(page, url) {
const { content, base64Encoded } = await page._client.send(
'Page.getResourceContent',
{ frameId: String(page.mainFrame()._id), url },
);
assert.equal(base64Encoded, true);
return content;
};
此时就说明我们可以利用前面的api获取该图片了。
const fs = require('fs');
await page.waitForSelector('#codePic');
const url = await page.$eval('#codePic', i => i.src);
const content = await getResourceContent(page, url);
const contentBuffer = Buffer.from(content, 'base64');
fs.writeFileSync('验证码.png', contentBuffer, 'base64');
这种方式并不限于只获取图片,也可以获取原始的js,svg之类的资源。
使用Puppeteer进行数据抓取(四)——图片下载的更多相关文章
- 使用Puppeteer进行数据抓取(四)——快速调试
在我们使用chrome作为爬虫获取网页数据时,往往需如下几步. 打开chrome 导航至目标页面 等待目标页面加载完成 解析目标页面数据 保存目标页面数据 关闭chrome 我们实际的编码往往集中在第 ...
- 使用Puppeteer进行数据抓取(一)——安装和使用
Puppeteer是 Google Chrome 团队官方的Chrome 自动化工具.它本身是基于Chrome Dev Protocol协议实现的,但它提供了更高层次API封装,使用起来更加方便快捷. ...
- 使用Puppeteer进行数据抓取(二)——Page对象
page对象是puppeteer最常用的对象,它可以认为是chrome的一个tab页,主要的页面操作都是通过它进行的.Google的官方文档详细介绍了page对象的使用,这里我只是简单的小结一下. 客 ...
- 使用Puppeteer进行数据抓取(三)——简单的示例
本文以一个示例简单的介绍一下puppeteer的用法,我们的目的是:获取我博客上的文章的前十页的所有随笔的标题和链接.由于puppeteer本身是自动化chorme,因此这里我们的步骤和手动操作浏览器 ...
- Phantomjs+Nodejs+Mysql数据抓取(1.数据抓取)
概要: 这篇博文主要讲一下如何使用Phantomjs进行数据抓取,这里面抓的网站是太平洋电脑网估价的内容.主要是对电脑笔记本以及他们的属性进行抓取,然后在使用nodejs进行下载图片和插入数据库操作. ...
- 网页数据抓取(B/S)
C# 抓取网页内容(转) 1.抓取一般内容 需要三个类:WebRequest.WebResponse.StreamReader 所需命名空间:System.Net.System.IO 核心代码: We ...
- python爬虫(一)_爬虫原理和数据抓取
本篇将开始介绍Python原理,更多内容请参考:Python学习指南 为什么要做爬虫 著名的革命家.思想家.政治家.战略家.社会改革的主要领导人物马云曾经在2015年提到由IT转到DT,何谓DT,DT ...
- 大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫
大众点评评论数据抓取 反爬虫措施有css文字映射和字体库反爬虫 大众点评的反爬虫手段有那些: 封ip,封账号,字体库反爬虫,css文字映射,图形滑动验证码 这个图片是滑动验证码,访问频率高的话,会出 ...
- Phantomjs+Nodejs+Mysql数据抓取(2.抓取图片)
概要 这篇博客是在上一篇博客Phantomjs+Nodejs+Mysql数据抓取(1.抓取数据) http://blog.csdn.net/jokerkon/article/details/50868 ...
随机推荐
- Loadrunner如何进行有效的IP欺骗
柠檬班的清风同学某天紧急求助如何搞IP欺骗,端午节后,抽时间把这个事情搞定啦!跟大家详细的讲讲IP欺骗的运用和理解. 一.什么是IP欺骗 给你客户端的IP地址加个马甲,让服务器端识别不到是同一个IP地 ...
- 基于Window10搭建android开发环境
一.安装JDK 1.下载(网页链接) 2.双击安装文件进行安装,安装在合适目录,例如:D:\Java\jdk1.8.0_201与D:\Java\jre1.8.0_201 3.设置环境变量 3.1.JA ...
- 【Windows编程】大量病毒分析报告辅助工具编写
解决重复劳动 是否在分析单个病毒时很爽,分析N个病毒写报告很机械的情况.. 1)样本下载多个文件,这些文件写报告时要加上这些文件的MD5 2)写报告时明明是17个MD5,实际样本有18个的情况.不知道 ...
- 深入了解mitmproxy(二)
主题 修改request或者response内容 介绍 mitmdump无交互界面的命令,与python脚本对接,来源于mitmproxy支持inline script,这里的script指 ...
- System.Web.Routing入门及进阶 下篇
上面介绍的是最简单的一种定义方式.当然我们可以建立更复杂的规则.其中就包括设定规则的默认值以及设定规则的正则表达式. UrlRouting高级应用 预计效果: 当我访问/a/b.aspx时就会转到De ...
- cas:覆盖安装
1.首先到github上下载最新的模板代码 https://github.com/apereo/cas-overlay-template 下载完成后,导入该工程. 2.编译打包 cd cas-over ...
- Ibatis.Net 执行存储过程学习(八)
首先在数据库创建存储过程: create proc [dbo].[usp_GetPersonById] @Id int as begin select Id,Name from Person wher ...
- Network Principle Course Summary 001
1.物理层 物理层 协议:RJ45.CLOCK.IEEE802.3 (中继器,集线器) 作用:通过媒介传输比特,确定机械及电气规范(比特Bit) 1.1 通信基础 数据 (data) —— 运送消息的 ...
- jQuery下的onChange事件在某些情况下无效
onChage无效的原因: 虽然表面上感觉是当内容发生变化时,就会触发onchange事件,但是那只能在页面上操作.而如果通过dom对象去修改它的value则什么事也不会发生. onchange触发原 ...
- c run-time library 和 standard c++ library
参考: c run-time libraries: http://msdn.microsoft.com/zh-cn/library/vstudio/abx4dbyh(v=vs.100).aspx H ...