图-图的表示、搜索算法及其Java实现
1.图的表示方法
图:G=(V,E),V代表节点,E代表边。
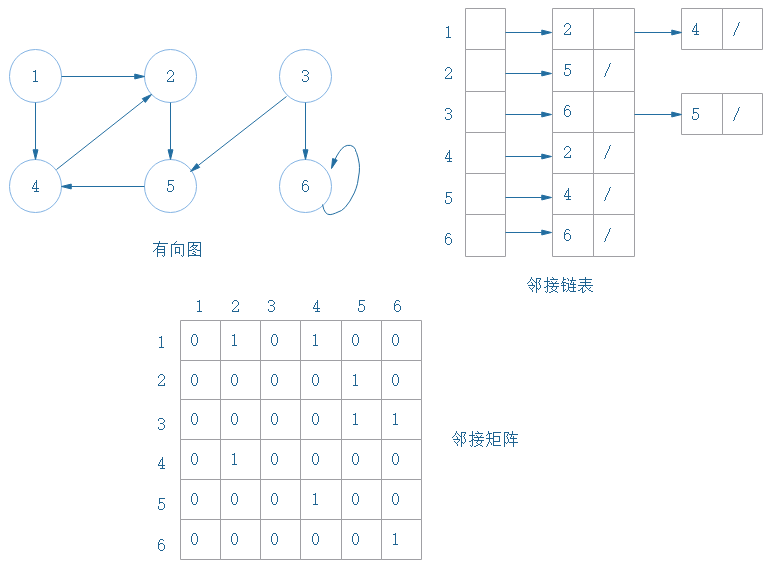
图有两种表示方法:邻接链表和邻接矩阵
邻接链表因为在表示稀疏图(边的条数|E|远远小于|V|²的图)时非常紧凑而成为通常的选择。
如果需要快速判断任意两个节点之间是否有边相连,可能也需要使用邻接矩阵表示法。
邻接链表表示法的鲁棒性很高,可以对其进行简单修改来支持许多其他的图变种。
邻接链表的一个潜在缺陷是无法快速判断一条边是否是图中地一条边。邻接矩阵则克服了这个缺陷,但付出的代价是更大的存储空间消耗。
——摘自《算法导论》
(1)无向图的两种表示


(2)有向图的两种表示
2.图的搜索算法
图的搜索算法即:广度优先搜索和深度优先搜索
相信这两种搜索算法的基本概念根据名字就可窥得一二,不多说,直接上例子。

如上有向图,创建三个类:
- 点Vertex:包括点的名称(String)和访问标志(boolean)。
- 边Edge:包括前驱点(Vertex)和后继点(Vertex)。
- 图Graph:包括点集合(ArrayList<Vertex>)和边集合(ArrayList<Edge>)。
以下是构建好的图信息以及点遍历结果。

以下是Java源码。BFS辅以队列以非递归方法完成,DFS以递归方法完成。注释得很详细,我就不多解释了@(^<>^)@。
import java.util.ArrayList;
import java.util.Iterator;
import java.util.LinkedList;
import java.util.Queue; class Graph{
ArrayList<Vertex> vertexs=new ArrayList<Vertex>();
ArrayList<Edge> edges=new ArrayList<Edge>(); public void addVertex(Vertex vertex) {
vertexs.add(vertex);
} public void addEdge(Edge edge) {
edges.add(edge);
}
} //顶点类
class Vertex{
String name;
boolean visited=false; //标记该点是否被查看-广度优先专用
boolean visited2=false; //标记该点是否被查看-深度优先专用 public Vertex(String name) {
this.name=name;
} @Override
public String toString() {
return "[" + name + "]";
}
}
//边类 有向图
class Edge{
Vertex start;
Vertex end; public Edge(Vertex start,Vertex end) {
this.start=start;
this.end=end;
} @Override
public String toString() {
return "(" + start + "," + end + ")";
}
} public class SearchGraph {
//广度优先 非递归
static void BFS(Graph graph) {
ArrayList<Vertex> vertexs=graph.vertexs;
ArrayList<Edge> edges=graph.edges;
Queue<Vertex> queue = new LinkedList<Vertex>(); //创建队列 queue.add(vertexs.get(0)); //顶节点放入队列
vertexs.get(0).visited=true; //顶节点设为已阅
System.out.print(vertexs.get(0)); while(!queue.isEmpty()) {
Vertex vertex=queue.remove();
for(Edge edge:edges) {
if(edge.start.equals(vertex)&&edge.end.visited==false) {
queue.add(edge.end);
edge.end.visited=true;
System.out.print(edge.end);
}
}
} } //深度优先 递归
static void DFS(Graph graph,Vertex vertex) { //参数:图、点信息
System.out.print(vertex);
vertex.visited2=true; for(Edge edge:graph.edges) {
if(edge.start.equals(vertex)&&edge.end.visited2==false) {
DFS(graph,edge.end);
}
}
} public static void main(String[] args) {
// TODO Auto-generated method stub //构造有向图
Graph graph=new Graph();
Vertex v0=new Vertex("v0");
Vertex v1=new Vertex("v1");
Vertex v2=new Vertex("v2");
Vertex v3=new Vertex("v3");
Vertex v4=new Vertex("v4");
Vertex v5=new Vertex("v5");
Vertex v6=new Vertex("v6");
graph.addVertex(v0);
graph.addVertex(v1);
graph.addVertex(v2);
graph.addVertex(v3);
graph.addVertex(v4);
graph.addVertex(v5);
graph.addVertex(v6);
Edge e0=new Edge(v0,v1);
Edge e1=new Edge(v0,v2);
Edge e2=new Edge(v0,v3);
Edge e3=new Edge(v1,v4);
Edge e4=new Edge(v1,v5);
Edge e5=new Edge(v2,v4);
Edge e6=new Edge(v3,v5);
Edge e7=new Edge(v4,v6);
Edge e8=new Edge(v5,v6);
graph.addEdge(e0);
graph.addEdge(e1);
graph.addEdge(e2);
graph.addEdge(e3);
graph.addEdge(e4);
graph.addEdge(e5);
graph.addEdge(e6);
graph.addEdge(e7);
graph.addEdge(e8);
//构造有向图 //测试图创建结果
ArrayList<Vertex> vertexs=graph.vertexs;
ArrayList<Edge> edges=graph.edges;
Iterator iVertex=vertexs.iterator();
Iterator iEdge=edges.iterator();
System.out.println("点集合:");
while(iVertex.hasNext()) {
System.out.print(iVertex.next());
}
System.out.println();
System.out.println("边集合:");
while(iEdge.hasNext()) {
System.out.print(iEdge.next());
}
//测试图创建结果 //遍历
System.out.println("");
System.out.println("广度优先遍历:");
BFS(graph);
System.out.println("");
System.out.println("深度优先遍历:");
DFS(graph,v0);
//遍历
} }
图-图的表示、搜索算法及其Java实现的更多相关文章
- 八大排序算法详解(动图演示 思路分析 实例代码java 复杂度分析 适用场景)
一.分类 1.内部排序和外部排序 内部排序:待排序记录存放在计算机随机存储器中(说简单点,就是内存)进行的排序过程. 外部排序:待排序记录的数量很大,以致于内存不能一次容纳全部记录,所以在排序过程中需 ...
- 八大排序算法——堆排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 先来了解下堆的相关概念:堆是具有以下性质的完全二叉树:每个结点的值都大于或等于其左右孩子结点的值,称为大顶堆:或者每个结点的值都小于或等于其左右孩子结点的值,称为小顶堆.如 ...
- 八大排序算法——希尔(shell)排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 希尔排序是把记录按下标的一定增量分组,对每组使用直接插入排序算法排序:随着增量逐渐减少,每组包含的关键词越来越多,当增量减至1时,整个文件恰被分成一组,算法便终止. 简单插 ...
- 八大排序算法——基数排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演 二.思路分析 基数排序第i趟将待排数组里的每个数的i位数放到tempj(j=1-10)队列中,然后再从这十个队列中取出数据,重新放到原数组里,直到i大于待排数的最大位数. 1.数组里的数最 ...
- 八大排序算法——归并排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 归并排序就是递归得将原始数组递归对半分隔,直到不能再分(只剩下一个元素)后,开始从最小的数组向上归并排序 1. 向上归并排序的时候,需要一个暂存数组用来排序, 2. 将 ...
- 八大排序算法——快速排序(动图演示 思路分析 实例代码Java 复杂度分析)
一.动图演示 二.思路分析 快速排序的思想就是,选一个数作为基数(这里我选的是第一个数),大于这个基数的放到右边,小于这个基数的放到左边,等于这个基数的数可以放到左边或右边,看自己习惯,这里我是放到了 ...
- 八大排序算法——插入排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 例如从小到大排序: 1. 从第二位开始遍历, 2. 当前数(第一趟是第二位数)与前面的数依次比较,如果前面的数大于当前数,则将这个数放在当前数的位置上,当前数的下标-1 ...
- 八大排序算法——冒泡排序(动图演示 思路分析 实例代码java 复杂度分析)
一.动图演示 二.思路分析 1. 相邻两个数两两相比,n[i]跟n[j+1]比,如果n[i]>n[j+1],则将连个数进行交换, 2. j++, 重复以上步骤,第一趟结束后,最大数就会被确定 ...
- 八大排序算法——选择排序(动图演示 思路分析 实例代码Java 复杂度分析)
一.动图演示 二.思路分析 1. 第一个跟后面的所有数相比,如果小于(或小于)第一个数的时候,暂存较小数的下标,第一趟结束后,将第一个数,与暂存的那个最小数进行交换,第一个数就是最小(或最大的数) ...
随机推荐
- 【转】Java学习---算法那些事
[更多参考] LeetCode算法 每日一题 1: Two Sum ----> 更多参考[今日头条--松鼠游学] 史上最全的五大算法总结 Java学习---7大经典的排序算法总结实现 程序员都应 ...
- Hexo搭建博客笔记
Hexo搭建(建议看ppt:https://files.cnblogs.com/files/-SANG/%E4%BD%A0%E7%9A%84%E7%8C%AB.pptx ) 安装Git https:/ ...
- WaitForMultipleObjects
WaitForMultipleObjects是Windows中的一个功能非常强大的函数,几乎可以等待Windows中的所有的内核对象 函数原型为: DWORD WaitForMultipleObjec ...
- apk静态注射[转]-未实践
原文:http://free0coding.iteye.com/blog/1684263 1.将需要注入的代码块打包成jar1,释放一个公共类的静态方法a 2.反编译apk得到smali文件,在适当 ...
- python第三十一课--递归(1.简单递归函数的定义和使用)
演示:简单递归函数的定义和使用 需求:1~5进行累加 找寻关系:函数名:mySum(num) 1).找临界点:运算到1(加到1)就结束了 2). 第一次:5+mySum(5-1)-->retur ...
- BZOJ4892:[TJOI2017]dna(hash)
Description 加里敦大学的生物研究所,发现了决定人喜不喜欢吃藕的基因序列S,有这个序列的碱基序列就会表现出喜欢吃藕的性状,但是研究人员发现对碱基序列S,任意修改其中不超过3个碱基,依然能够表 ...
- FastJson遇见的问题或项目实战中优化的问题,看源码都可以解决
1:感觉见鬼了一般存储JSONObject中的字段竟然不见了? JSONObject object=new JSONObject(); Map fields = new HashMap(); fiel ...
- Metabase在Windows下的开发环境配置
Metabase在Windows下的开发环境配置 */--> pre.src {background-color: #292b2e; color: #b2b2b2;} Metabase在Wind ...
- MyBatis实战之初步
关于MyBatis与Hibernate及其JDBC的比较,大家可以参考我的这篇文章:MyBatis+Hibernate+JDBC对比分析 如果觉得这个还不够系统全面,可以自行Google或者百度. 用 ...
- 了解linux的进程:rootfs与linuxrc
导读 内核启动的最后阶段启动了三个进程进程0:进程0其实就是刚才讲过的idle进程,叫空闲进程,也就是死循环.进程1:kernel_init函数就是进程1,这个进程被称为init进程.进程2:kthr ...