大数据入门第二十三天——SparkSQL(一)入门与使用
一、概述
1.什么是sparkSQL
根据官网的解释:
Spark SQL is a Spark module for structured data processing.
也就是说,sparkSQL是一个处理结构化数据的组件
更多的介绍,可以参见官网或者w3c:https://www.w3cschool.cn/spark_sql/spark_sql_introduction.html
中文简明介绍:
Spark SQL是Spark用来处理结构化数据的一个模块,它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用。(当然,现在还有DataSet)
2.与hive的关联
我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执行效率比较慢。MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,降低的运行效率。所以Spark SQL的应运而生,它是将Spark SQL转换成RDD,然后提交到集群执行,执行效率非常快!
3.spark SQL的特点
由官网介绍,可以知道,有以下特性:
1.易整合
2.统一的数据访问方式
3.兼容Hive
4.标准的数据连接
二、DataFrames
1.什么是DataFrames
与RDD类似,DataFrame也是一个分布式数据容器。然而DataFrame更像传统数据库的二维表格,除了数据以外,还记录数据的结构信息,即schema。
同时,与Hive类似,DataFrame也支持嵌套数据类型(struct、array和map)。从API易用性的角度上 看,DataFrame API提供的是一套高层的关系操作,比函数式的RDD API要更加友好,门槛更低。由于与R和Pandas的DataFrame类似,Spark DataFrame很好地继承了传统单机数据分析的开发体验。
2.1版本中的Dataset的区别与对比,参考:https://www.cnblogs.com/starwater/p/6841807.html
2.创建DataFrames
启动Hadoop(这里只使用start-dfs.sh启动hdfs,yarn暂时不起)
启动spark(在sbin/start-all.sh)
启动spark-shell:
[hadoop@mini1 ~]$ /home/hadoop/apps/spark-1.6.-bin-hadoop2./bin/spark-shell \
> --master spark://mini1:7077 \
> --executor-memory 1g \
> --total-executor-cores
创建步骤:
1.在本地创建一个文件,有三列,分别是id、name、age,用空格分隔,然后上传到hdfs上
hdfs dfs -put person.txt /
2.在spark shell执行下面命令,读取数据,将每一行的数据使用列分隔符分割
val lineRDD = sc.textFile("hdfs://mini1:9000/person.txt").map(_.split(","))
3.定义case class(相当于表的schema)
case class Person(id:Int, name:String, age:Int)
4.将RDD和case class关联
val personRDD = lineRDD.map(x => Person(x(0).toInt, x(1), x(2).toInt))
5.将RDD转换成DataFrame
val personDF = personRDD.toDF
6.接下来就可以对DF进行处理了,例如:

// select("id","name").show()等选择特定列(DSL风格)
3.DataFrame常用操作
DSL风格
查看内容:personDF.show

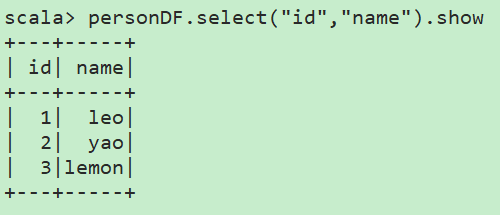
查看指定列:personDF.select("id","name").show
查看schema信息:personDF.printSchema

列操作(age+1):personDF.select(col("id"), col("name"), col("age") + 1).show

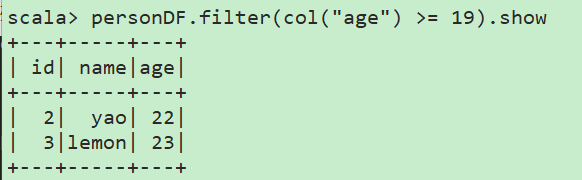
过滤操作(age>=19):personDF.filter(col("age") >= 19).show
分组并统计:personDF.groupBy("age").count().show()
SQL风格
如果想使用SQL风格的语法,需要将DataFrame注册成表
personDF.registerTempTable("t_person")
然后,就可以使用 sqlContext.sql 来使用SQL风格的语法了!
查询年龄最大的前两名:SELECT * FROM t_person ORDER BY age DESC LIMIT 2

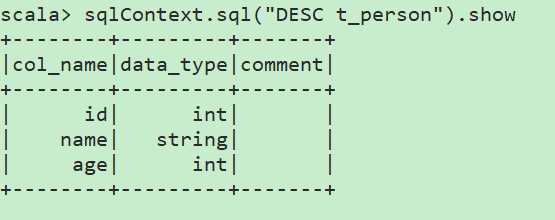
显示表的Schema信息:DESC t_person
三、以编程形式执行spark SQL
1.引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.10</artifactId>
<version>1.5.2</version>
</dependency>
// 项目依然使用之前的helloSpark
2.编写代码——通过反射推断Schema
package com.sql
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.SQLContext
object SQLDemo {
def main(args: Array[String]): Unit = {
// 提交集群
// val conf = new SparkConf().setAppName("SQLDemo")
// 本地运行
val conf = new SparkConf().setAppName("SQLDemo").setMaster("local")
val sc = new SparkContext(conf)
// 创建sql的交互接口
val sqlContext = new SQLContext(sc)
// 可以设置用户(与Hadoop类似)
System.setProperty("user.name","hadoop")
val personRDD = sc.textFile("hdfs://mini1:9000/person.txt").map(line => {
val fields = line.split(",")
// case class不用new,直接返回了一个Person
Person(fields(0).toInt, fields(1), fields(2).toInt)
})
// 导入隐式转换,将rdd转换为DF(原RDD没有那个方法)
import sqlContext.implicits._
val personDF = personRDD.toDF
// 可以使用DSL风格:personDF.show
// 推荐使用熟悉的SQL风格,先转换再使用
personDF.registerTempTable("t_person")
val sql1 = "SELECT * FROM t_person ORDER BY age DESC LIMIT 2"
sqlContext.sql(sql1).show()
sc.stop()
}
}
case class Person(id:Int, name:String, age:Int)
提交集群:如果需要参数的话需要在后面再追加相关参数即可
[hadoop@mini1 ~]$ /home/hadoop/apps/spark-1.6.3-bin-hadoop2.6/bin/spark-submit \
> --class com.sql.SQLDemo \
> --master spark://mini1:7077 \
> /home/hadoop/HelloSpark-2.0.jar
3.编写代码——通过StructType直接指定Schema
package cn.itcast.spark.sql
import org.apache.spark.sql.{Row, SQLContext}
import org.apache.spark.sql.types._
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by ZX on 2015/12/11.
*/
object SpecifyingSchema {
def main(args: Array[String]) {
//创建SparkConf()并设置App名称
val conf = new SparkConf().setAppName("SQL-2")
//SQLContext要依赖SparkContext
val sc = new SparkContext(conf)
//创建SQLContext
val sqlContext = new SQLContext(sc)
//从指定的地址创建RDD(这里的RDD还是切割的Array,而不是Person了)
val personRDD = sc.textFile(args(0)).map(_.split(" "))
//通过StructType直接指定每个字段的schema
val schema = StructType(
List(
StructField("id", IntegerType, true),
StructField("name", StringType, true),
StructField("age", IntegerType, true)
)
)
//将RDD映射到rowRDD
val rowRDD = personRDD.map(p => Row(p(0).toInt, p(1).trim, p(2).toInt))
//将schema信息应用到rowRDD上
val personDataFrame = sqlContext.createDataFrame(rowRDD, schema)
//注册表
personDataFrame.registerTempTable("t_person")
//执行SQL
val df = sqlContext.sql("select * from t_person order by age desc limit 4")
//将结果以JSON的方式存储到指定位置
df.write.json(args(1))
//停止Spark Context
sc.stop()
}
}
结果处理:
6.对personDF进行处理 #(SQL风格语法)
personDF.registerTempTable("t_person")
sqlContext.sql("select * from t_person order by age desc limit 2").show
sqlContext.sql("desc t_person").show
val result = sqlContext.sql("select * from t_person order by age desc") 7.保存结果(sava已经是deprecated)
result.save("hdfs://hadoop.itcast.cn:9000/sql/res1")
result.save("hdfs://hadoop.itcast.cn:9000/sql/res2", "json") #以JSON文件格式覆写HDFS上的JSON文件
import org.apache.spark.sql.SaveMode._
result.save("hdfs://hadoop.itcast.cn:9000/sql/res2", "json" , Overwrite) 8.重新加载以前的处理结果(可选)
sqlContext.load("hdfs://hadoop.itcast.cn:9000/sql/res1")
sqlContext.load("hdfs://hadoop.itcast.cn:9000/sql/res2", "json")
大数据入门第二十三天——SparkSQL(一)入门与使用的更多相关文章
- 大数据入门第二十三天——SparkSQL(二)结合hive
一.SparkSQL结合hive 1.首先通过官网查看与hive匹配的版本 这里可以看到是1.2.1 2.与hive结合 spark可以通过读取hive的元数据来兼容hive,读取hive的表数据,然 ...
- CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令
相关文章链接 CentOS6安装各种大数据软件 第一章:各个软件版本介绍 CentOS6安装各种大数据软件 第二章:Linux各个软件启动命令 CentOS6安装各种大数据软件 第三章:Linux基础 ...
- 大数据入门第二十五天——elasticsearch入门
一.概述 推荐路神的ES权威指南翻译:https://es.xiaoleilu.com/010_Intro/00_README.html 官网:https://www.elastic.co/cn/pr ...
- 【若泽大数据实战第二天】Linux命令基础
Linux基本命令: 查看IP: ifconfig 或者 hostname -i(需要配置文件之后才可以使用) ipconfig(Windows) 关闭防火墙: Service iptables st ...
- 大数据入门第二十五天——logstash入门
一.概述 1.logstash是什么 根据官网介绍: Logstash 是开源的服务器端数据处理管道,能够同时 从多个来源采集数据.转换数据,然后将数据发送到您最喜欢的 “存储库” 中.(我们的存储库 ...
- Hadoop大数据学习视频教程 大数据hadoop运维之hadoop快速入门视频课程
Hadoop是一个能够对大量数据进行分布式处理的软件框架. Hadoop 以一种可靠.高效.可伸缩的方式进行数据处理适用人群有一定Java基础的学生或工作者课程简介 Hadoop是一个能够对大量数据进 ...
- 大数据学习第二章、HDFS相关概念
1.HDFS核心概念: 块 (1)为了分摊磁盘读写开销也就是大量数据间分摊磁盘寻址开销 (2)HDFS块比普通的文件块大很多,HDFS默认块大小为64MB,普通的只有几千kb 原因:1.支持面向大规模 ...
- spark大数据快速分析第二章
1.驱动程序通过一个SparkContext对象来访问Spark,此对象代表对计算集群的一个连接.shell已经自动创建了一个SparkContext对象.利用SparkContext对象来创建一个R ...
- 大数据框架开发基础之Sqoop(1) 入门
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
随机推荐
- vue 结合 animate.css
这里说的是vue2.0和animate.css的结合使用.其实用过就知道用法是比较简单的.但是就是刚开始使用的时候,难免有的会遇到各种问题.简单的说说我所用过并且遇过的坑. 首先是transition ...
- log4net 本地环境没问题 生产环境无法输出日志
log4net输出日志大概分两块 1.程序代码编写问题 2.配置文件问题 当程序本地可以正常输出日志.配置文件也都正常可用的情况下,发布到生产环境后,有的程序可以输出日志,有的程序不可以输出,程序无问 ...
- 《JavaScript面向对象编程指南》
第一章.引言 1.5 面向对象的程序设计常用概念 对象(名词):是指"事物"在程序设计语言中的表现形式. 这里的事物可以是任何东西,我们可以看到它们具有某些明确特征,能执行某些动作 ...
- [转载]Buffer cache的调整与优化
Buffer Cache是SGA的重要组成部分,主要用于缓存数据块,其大小也直接影响系统的性能.当Buffer Cache过小的时候,将会造成更多的free buffer waits事件.下面将具体描 ...
- nopcommerce
nopcommerce是国外的一个高质量的开源b2c网站系统,基于EntityFramework4.0和MVC3.0,使用Razor模板引擎,有很强的插件机制,包括支付配送功能都是通过插件来实现的,基 ...
- linux常见问题解决
1.登录环境故障的原理及解决办法? -bash-4.1$ -bash-4.1$ cp /etc/skel/.bash* .
- 实现CTreeCtrl父子节点的联动选择
本文实现了下面的功能: 当选中父节点时, 其所有子节点全部选中. 当取消选中父节点时, 其所以子节点全部取消选中. 点击子节点时, 根据子节点与其兄弟节点的选中状态, 自动设置父节点的选中状态. 通过 ...
- 用JS制作《飞机大作战》游戏_第1讲(素材查找和界面框架搭建)-陈远波
一.查找素材: 二.分析游戏界面框架: 登录界面.游戏界面.暂停游戏界面.玩家死亡后弹出界面:并对应的界面包含什么元素: 三.分别搭建以上四个界面: 1.登录界面与游戏界面框架(隐藏游戏界面,四个界面 ...
- 【剑指offer】数值的整数次方
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/mmc_maodun/article/details/25506085 转载请注明出处:http:// ...
- Volley源码分析(二)CacheDispatcher分析
CacheDispatcher 缓存分发 cacheQueue只是一个优先队列,我们在start方法中,分析了CacheDispatcher的构成是需要cacheQueue,然后调用CacheDisp ...