Mybatis简介、环境搭建和详解
简介:
1、Mybatis 开源免费框架,原名叫iBatis,2010在google code,2013年迁移到github
2、作用: 数据访问层框架
2.1 底层是对JDBC的封装
3、mybatis优点之一:
3.1 使用mybatis时,不需要编写实现类,只需要写需要执行的sql命令。
环境搭建:
1、导入jar (之前把mysql的驱动包放入tomcat中了,所有在这里没有导入mysql驱动包)

2、在src下新建全局配置文件(编写JDBC四个变量)
2.1 在src目录下新建xml文件 (src/mybatis.xml)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE configuration 2-4是引入远程的DTD文件,进行代码的提示
PUBLIC "-//mybatis.org//DTD Config 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-config.dtd">
<configuration>
<!-- default引用environment的id,当前所使用的环境 -->
<environments default="default">
<!-- 声明可以使用的环境 -->
<environment id="default">
<!-- 使用原生JDBC事务 -->
<transactionManager type="JDBC"></transactionManager>
<!-- 数据库的连接池 --> 配置JDBC四个变量
<dataSource type="POOLED">
<property name="driver" value="com.mysql.jdbc.Driver"/>
<property name="url" value="jdbc:mysql://localhost:3306/ssm"/>
<property name="username" value="root"/>
<property name="password" value="362222"/>
</dataSource>
</environment>
</environments>
21 <mappers>
22 <mapper resource="com/bjsxt/mapper/FlowerMapper.xml"/>
23 </mappers>
</configuration>
3、新建以mapper结尾的包,在包下新建:实体类名+Mapper.xml 的文件
3.1 文件的作用: 编写需要执行的SQL语句
3.2 把xml理解成实现类
实现过程是:mybatis底层将xml文件解析反射成实现类进行数据操作
3.3 配置过程 (com/bjsxt/mapper/FlowerMapper.xml)
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<!-- namesapce:理解成实现类的全路径(包名+类名) -->
<mapper namespace="a.b">
<!-- id:方法名
parameterType:定义参数类型
resultType:返回值类型 如果方法返回值是list,在resultType中写List的泛型,因为mybatis对
jdbc封装,一行一行读取数据
--> 通过反射找到自定义的类 (查询的是List集合,为什么类型是自定义的类??因为底层是对JDBC封装的(ResultSet一次只能读取一行数据),一行数据是一个实体类)
<select id="sellAll" resultType="com.bjsxt.pojo.Flower">
select * from flower
</select>
</mapper>
4、测试结果(只有在单独使用mybatis时使用,最后ssm整合时下面代码不需要编写)
4.1 新建一个包一个类进行测试
package com.bjsxt.test; import java.io.IOException;
import java.io.InputStream;
import java.util.List; import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder; import com.bjsxt.pojo.Flower; public class Test {
public static void main(String[] args) {
InputStream is = null;
try {
is = Resources.getResourceAsStream("mybatis.xml"); } catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
//使用工厂设计模式
SqlSessionFactory factory=new SqlSessionFactoryBuilder().build(is);
//生产SqlSession SqlSession 封装了mybatis中所有的sql命令
SqlSession session=factory.openSession(); List<Flower> list = session.selectList("a.b.sellAll");
for(Flower flower:list){
System.out.println(flower.toString());
}
session.close();
}
}
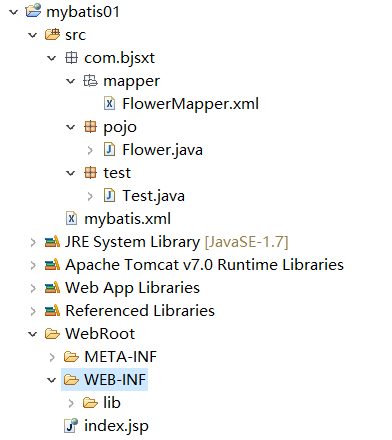
文件目录
环境搭建详解:
1、全局配置文件中内容
1.1 <transactionManager/> type 属性可取值
1.1.1 JDBC事务管理使用JDBC原生事务管理方式
1.1.2 MANAGED 把事务管理转交给其他容器 (spring使用)
原生JDBC事务 setAutoMapping(false);
1.2 <dataSouce/> type属性
1.2.1 POOLED 使用数据库连接池
1.2.2 UNPOOLED 不使用数据库连接池,和直接使用JDBC一样
1.2.3 JNDI : java命名目录接口技术,(使用java通过接口调用别的语言程序)
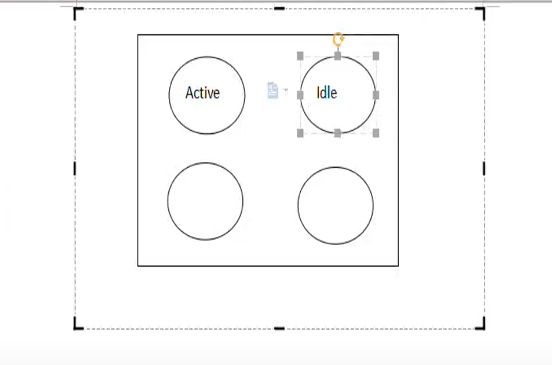
数据库连接池
1、在内存中开辟一块空间,存放多个数据库连接对象。
2、JDBC Tomcat Pool 直接由tomcat产生数据库连接池
3、图示
3.1 active 状态:当前连接对象被应用程序使用中
3.2 ldle 空闲状态:等待应用程序使用
4、使用数据库连接池的目的
4.1 在高频率访问数据库时,使用数据库连接池可以降低服务器系统压力,提升程序运行效率。
4.1.1 小型项目不适用数据库连接池
5、实现JDBC tomcat Pool的步骤
三种查询方式
1、select() 返回值为List<resultType 属性控制>
1.1 适用于查询结果都需要遍历的需求
下面这是Test测试
1 List<Flower> list = session.selectList("a.b.sellAll");
for(Flower flower:list){
System.out.println(flower.toString());
} 下面只是FlowerMapper.xml文件
<select id="sellAll" resultType="com.bjsxt.pojo.Flower">
select * from flower
</select>
2、selectOne() 返回值Object
2.1 适用于返回结果只是变量或一行数据时
下面这是Test测试
1 int i=session.selectOne("a.b.selById");
System.out.println(i); 下面这是FlowerMapper.xml文件中
<select id="selById" resultType="int">
select count(*) from flower
</select>
3、selectMap() 返回值 Map
3.1 适用于需求需要在查询结果中通过某列的值取到这行数据的需求
3.2 Map<Key,resultType控制>
下面这是Test测试
//把数据库中哪个列的值当做map的key
Map<Object, Object> map = session.selectMap("a.b.c","name");
System.out.println(map);
下面这是FlowerMapper.xml文件中
<select id="c" resultType="com.bjsxt.pojo.Flower">
select * from flower
</select>
Mybatis简介、环境搭建和详解的更多相关文章
- 大数据学习系列之四 ----- Hadoop+Hive环境搭建图文详解(单机)
引言 在大数据学习系列之一 ----- Hadoop环境搭建(单机) 成功的搭建了Hadoop的环境,在大数据学习系列之二 ----- HBase环境搭建(单机)成功搭建了HBase的环境以及相关使用 ...
- SpringMVC环境搭建和详解
1.Spring容器和SpringMVC容器是父子容器 1.1 SpringMVC容器可以调用Spring容器中的所有内容 1.2 图示 2.SpringMVC环境搭建 1.导入jar包 2.在web ...
- visual studio 2015下使用gcc调试linux c++开发环境搭建完整详解
一直以来,相信绝大部分的开发都是windows/mac下做开发,尤其是非嵌入式和qt系的,而开源服务器程序绝大部分都是跑在Linux下,几乎就没有跑在windows下的.一直以来开发人员都是在wind ...
- Jmeter(一) - 从入门到精通 - 环境搭建(详解教程)
1.JMeter 介绍 Apache JMeter是100%纯JAVA桌面应用程序,被设计为用于测试客户端/服务端结构的软件(例如web应用程序).它可以用来测试静态和动态资源的性能,例如:静态文件, ...
- windows环境搭建jira 详解
一.事前准备 1:JDK下载并安装:http://www.oracle.com/technetwork/java/javase/downloads/index.html2:MySQL JDBC连接驱动 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- idea spring+springmvc+mybatis环境配置整合详解
idea spring+springmvc+mybatis环境配置整合详解 1.配置整合前所需准备的环境: 1.1:jdk1.8 1.2:idea2017.1.5 1.3:Maven 3.5.2 2. ...
- Quartz学习——SSMM(Spring+SpringMVC+Mybatis+Mysql)和Quartz集成详解(转)
通过前面的学习,你可能大致了解了Quartz,本篇博文为你打开学习SSMM+Quartz的旅程!欢迎上车,开始美好的旅程! 本篇是在SSM框架基础上进行的. 参考文章: 1.Quartz学习——Qua ...
- Scala IDEA for Eclipse里用maven来创建scala和java项目代码环境(图文详解)
这篇博客 是在Scala IDEA for Eclipse里手动创建scala代码编写环境. Scala IDE for Eclipse的下载.安装和WordCount的初步使用(本地模式和集群模式) ...
随机推荐
- 录音器 AudioRecorder
实现录音器有两种方式可以选择: 1.AudioRecord(基于字节流录音) 优点:可以实现语音的实时处理,进行边录边播,对音频的实时处理. 缺点:输出的是PCM的语音数据,如果保存成音频文件是不能被 ...
- TZOJ 3209 后序遍历(已知中序前序求后序)
描述 在数据结构中,遍历是二叉树最重要的操作之一.所谓遍历(Traversal)是指沿着某条搜索路线,依次对树中每个结点均做一次且仅做一次访问. 这里给出三种遍历算法. 1.中序遍历的递归算法定义: ...
- FortiGate常用命令
1.命令结构 config Configure object. 对策略,对象等进行配置 get Get dynamic and system information. 查看相关关对 ...
- day 30 HTML
HTML: 超文本标记语言(Hyper Text Markup Language) Html基本结构 <!DOCTYPE html> <html> <!-- 定义HTML ...
- 31-java中知识总结:list, set, map, stack, queue
import java.util.ArrayList; import java.util.HashMap; import java.util.HashSet; import java.util.Lin ...
- 【WH】MVC数据分页扩展类
public static class QueryableExtensions { #region 内存分页 /// <summary> /// 返回对象分页列表 /// </sum ...
- Beyound Compare中比较java字节码class文件
背景 项目维护的时候版本混乱或者外出在现场项目排错的时候难免要比对两个jar/class/war文件的源代码. 通常情况下这个时候我们用jd-gui直接把文件拖进去比对,这种情况只适合单一文件的比对. ...
- 时间处理:计算下一天日期,如输入"2004/12/31"(注释2014年12月31日),则输出"2005/1/1".
/* ============================================================================ Name : Exercise.c Au ...
- Liunx 硬盘分区
1)什么要进行硬盘分区:a) 更容易管理和控制系统,因为相关的文件和目录都放在一个分区中.b) 系统效率更高.c) 可以限制用户使用硬盘的份额(磁盘空间的大小).d) 更容易备份和恢复. 2)硬盘的逻 ...
- PAT 1018 锤子剪刀布(20)
1018 锤子剪刀布 (20)(20 分) 大家应该都会玩"锤子剪刀布"的游戏:两人同时给出手势,胜负规则如图所示: 现给出两人的交锋记录,请统计双方的胜.平.负次数,并且给出双方 ...