.net 大数据量,查找Where优化(List的Contains与Dictionary的ContainsKey的比较)
最近优化一个where查询条件,查询时间很慢,改为用Dictionary就很快了。
一、样例
假设:listPicsTemp 有100w条数据,pictures有1000w条数据。
使用第1段代码执行超过2分钟。
var listPicsTemp = new List<string>(); pictures = pictures.AsParallel().Where(d => listPicsTemp.Contains(d.Pic)).ToList();
使用第2段代码执行十几毫秒。
var listPicsTemp = new List<string>(); var dicPicsTemp = listPicsTemp.Where(d => d != null).Distinct().ToDictionary(d => d);//使用Dictionary类型,速度快很多 pictures = pictures.AsParallel().Where(d => dicPicsTemp.ContainsKey(d.Pic)).ToList();
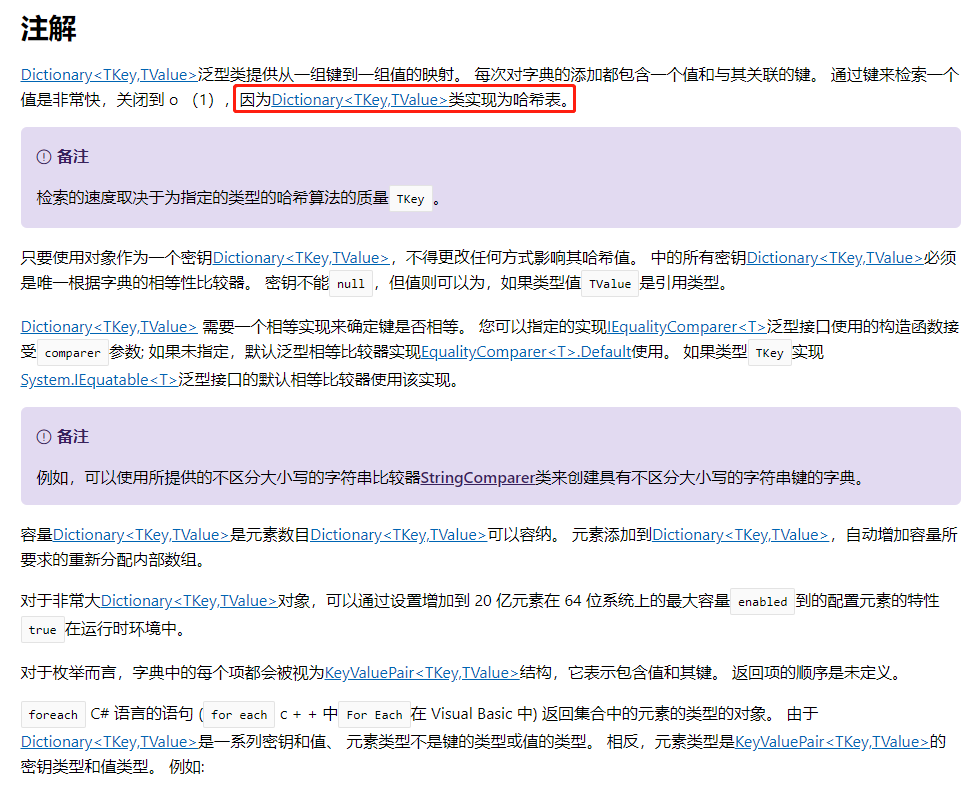
二、为什么Dictionary这么快呢?查看了一下微软官方文档。

三、查看源码
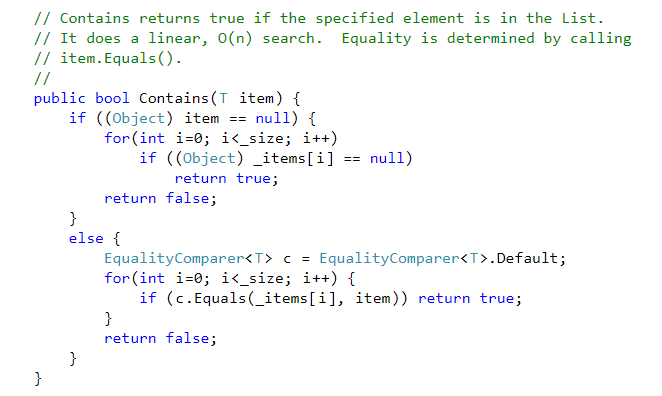
List的源码:https://referencesource.microsoft.com/#mscorlib/system/collections/generic/list.cs,cf7f4095e4de7646
List的Contains,是循环for查找的。
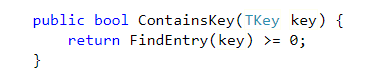
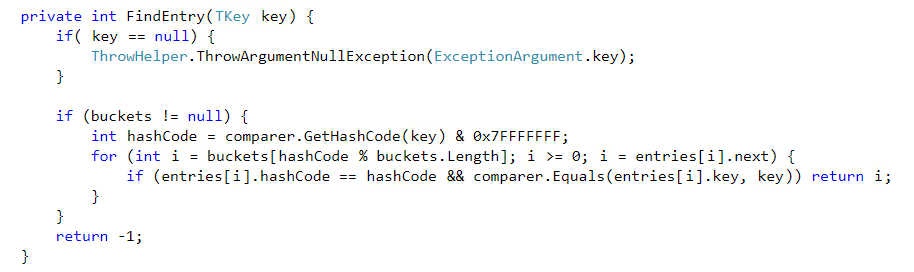
Dictionary的源码: https://referencesource.microsoft.com/#mscorlib/system/collections/generic/dictionary.cs,bcd13bb775d408f1
Dictionary的ContainsKey,是通过hash查找的。
四、小结:
1、Dictionary<TKey,TValue>类实现为哈希表。ContainsKey() 内部是通过Hash查找实现的,查询的时间复杂度是O(1)。所以,查询很快。(List的Contains是通过for查找的)
2、Dictionary不是线程安全的。(查看微软官方文档,确实能学到很多知识盲区。)
.net 大数据量,查找Where优化(List的Contains与Dictionary的ContainsKey的比较)的更多相关文章
- sql大数据量查询的优化技巧
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引. 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索 ...
- MySQL大数据量分页性能优化
mysql大数据量使用limit分页,随着页码的增大,查询效率越低下. 测试实验 1. 直接用limit start, count分页语句, 也是我程序中用的方法: select * from p ...
- 任何抛开业务谈大数据量的sql优化都是瞎扯
周三去某在线旅游公司面试.被问到了一个关于数据量大的优化问题.问题是:一个主外键关联表,主表有一百万数据,外键关联表有一千万的数据,要求做一个连接. 本人接触过单表数据量最大的就是将近两亿行历史数据( ...
- Android, BaseAdapter 处理大数据量时的优化
Android优化 最常见的就是ListView, Gallery, GridView, ViewPager 的大数据优化 图片优化 访问网络的优化优化的原则: 数据延迟加载 分批加载 本地缓 ...
- mysql大数据量之limit优化
背景:当数据库里面的数据达到几百万条上千万条的时候,如果要分页的时候(不过一般分页不会有这么多),如果业务要求这么做那我们需要如何解决呢?我用的本地一个自己生产的一张表有五百多万的表,来进行测试,表名 ...
- 【MYSQL】mysql大数据量分页性能优化
转载地址: http://www.cnblogs.com/lpfuture/p/5772055.html https://www.cnblogs.com/shiwenhu/p/5757250.html ...
- 0113针对大数据量SUM的优化-思路
转自博客:http://bbs.csdn.net/topics/390426801?page=1 优化思路:无论如何你的结果都是要扫描全有表记录,而在456010记录中,的UserName的分布导致这 ...
- DB开发之大数据量高并发的数据库优化
一.数据库结构的设计 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能.所以,在一个系统开始实施之前,完备的数据库模型的设计是必须的. ...
- 大数据量高并发的数据库优化详解(MSSQL)
转载自:http://www.jb51.net/article/71041.htm 如果不能设计一个合理的数据库模型,不仅会增加客户端和服务器段程序的编程和维护的难度,而且将会影响系统实际运行的性能. ...
- 大数据量高并发访问SQL优化方法
保证在实现功能的基础上,尽量减少对数据库的访问次数:通过搜索参数,尽量减少对表的访问行数,最小化结果集,从而减轻网络负担:能够分开的操作尽量分开处理,提高每次的响应速度:在数据窗口使用SQL时,尽量把 ...
随机推荐
- MyBatis3-代码生成工具的使用
以下内容引用自http://www.yihaomen.com/article/java/331.htm: MyBatis应用程序,需要大量的配置文件,对于一个成百上千的数据库表来说,完全手工配置,这是 ...
- js禁止滚动条滚动,并且滚动条不消失,页面大小不变
//禁止滚动条滚动 function unScroll() { var top = $(document).scrollTop(); $(document).on('scroll.unable',fu ...
- V Server Ubuntu
Ubuntu下代理伺服器通常使用squid 安裝 sudo apt-get install squid 修改squid.conf配置 sudo vim /etc/squid/squid.conf 公司 ...
- javascript中数组的定义及使用
js <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.o ...
- Solidworks如果有两个相似的图纸如何快速复制第二份图纸
如下图所示,我有两个零件,只有四个孔从螺纹孔改成了通孔(孔的尺寸改大了一点) 我已经画好了带螺纹的图纸 直接另存为,但是不要勾选另存为副本,改一下另存为的名字即可 然后打开这个另存为的工程图, ...
- 最老程序猿创业开发实训1---Android应用架构之MVC
我们都知道Android中基本组件是Activity,每一个界面都是一个Activity,自从2.3版本号開始.又添加了Fragment组件,提供了适应于各种屏幕方法.可是因为Android系统仅仅是 ...
- jquery 数组添加不重复数据
var columnCommentsArray = new Array(); $("input[name='columnComments']").each( function(){ ...
- AngularJS2.0 quick start——其和typescript结合需要额外依赖
AngularJS2 发布于2016年9月份,它是基于ES6来开发的. 运行条件! 由于目前各种环境(浏览器或 Node)暂不支持ES6的代码,所以需要一些shim和polyfill(IE需要)让ES ...
- Codeforces--622A--Infinite Sequence(数学)
Infinite Sequence Crawling in process... Crawling failed Time Limit:1000MS Memory Limit:26214 ...
- HDU4336:Card Collector
题意 有n张卡片,每一次 有pi的概率买到第i张卡.求买到所有卡的期望购买次数. n<=20 解析 Solution 1:大力状压(就是步数除以方案数) #include<iostream ...