小白学习Spark系列一:Spark简介
由于最近在工作中刚接触到scala和Spark,并且作为python中毒者,爬行过程很是艰难,所以这一系列分为几个部分记录下学习《Spark快速大数据分析》的知识点以及自己在工程中遇到的小问题,以下阶段也是我循序了解Spark的一个历程。
先抛出几个问题:
- 什么是Spark?
- Spark内部是怎么实现集群调度的?
- 如何调用Spark?
- 如何打包一个Spark独立应用?
一、Spark是什么
Spark是一个用来实现快速而通用的集群计算平台。它一个主要特点是能够在内存中进行计算,并且提供了基于Python、Java、Scala和SQL的API,可以和其他大数据工具配合使用。由于Spark的核心引擎有着速度快和通用的特点,因此它还支持各种不同应用场景专门设计的高级组件,比如SQL和机器学习等。组件其实可以理解为Spark针对常见的任务场景而封装好的模块,这些模块提供了各场景的基本功能。组件之间可以相互调用,各组件如图1-1:
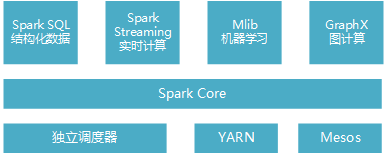
图1-1 Spark软件栈
- Spark Core实现了任务调度、内存管理、错误恢复、与存储系统交互等模块,并且还包含了对弹性分布式数据集(Resilient Distributed Dataset,简称RDD)的API定义。它主要担任了系统管理员的角色。
- Spark SQL 主要用来操作结构化数据的程序包,通过Spark SQL可以使用SQL或者hive版本的HQL来查询数据库。
- Spark Streaming 主要是对实时数据进行流式计算。
- MLib提供了很多机器学习算法。
- GraphX用来操作图,可以并行的进行图计算,支持了图的各种操作。
其中,Spark SQL组件是经常用到的,使用hql语句从hadoop数仓中读取结构化的数据,存为RDD数据集,进行一些操作后分布式存储到hdfs中。
二、Spark核心概念
分布式环境下,Spark集群采用主/从结构。有一个驱动器(Driver)节点负责中央协调,调度各个分布式工作节点,这里的工作节点也叫作执行器(executor)节点。驱动器节点可以和大量的执行器节点通信,这些节点一起被称为一个Spark应用。
Spark应用主要是由一个驱动器节点的程序来发起集群上的各种并行操作,驱动器程序也就是你写的代码,包含了应用的main函数,定义了分布式数据集以及进行相关操作。那这个程序哪里体现出能够操作集群的功能呢?主要通过实例化一个SparkContext 对象来访问Spark,这个对象可以用来连接计算集群。在shell交互式环境下,会自动创建这个对象,叫做sc的变量。否则,需要自己定义。如下代码展示了如何查看交互式shell环境下sc的类型。

下图1-2展示了Spark如何在一个集群上运行。
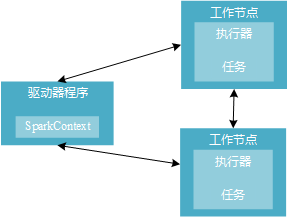
图1-2 Spark分布式组件
驱动器节点的任务:
(1)把用户程序转为任务
隐式地创建一个由操作组成的逻辑上的有向无环图,当驱动程序运行时,会把这个逻辑图转为物理执行计划。
(2)为执行器节点调度任务
执行器进程启动后,会向驱动器进程注册自己。驱动器程序会根据当前执行器节点集合,把所有任务基于数据所在位置分配给合适的执行器进程。当任务执行时,执行器进程把缓存数据存储,驱动器进程会跟踪这些缓存数据的位置,并利用这些信息调度以后的任务。
执行器节点的任务:
(1)负责运行组成Spark应用的任务,并将结果返回给驱动器进程。
(2)通过自身的块管理器为用户程序中要求缓存的RDD提供内存式存储。
三、Spark调用
(1)spark-shell(交互窗口模式: 逐行敲模式)
运行spark-shell需要指向申请资源的standalone spark集群信息,其参数为MASTER,还可以指定executor(执行器)及driver(驱动器)的内存大小。
yarn模式:
1 sudo spark-shell --executor-memory 5g --driver-memory 1g --master yarn
local模式:
sudo spark-shell --executor-memory 5g --driver-memory 1g --master local
输入上面的脚本后回车,就到了spark-shell页面,spark-shell已经默认生成sc对象,可以用如下代码读取数据资源。
val user_rdd1 = sc.textFile(inputpath, ) #inputpath:文件名
注意:local 模式是开发模式,为了验证实现逻辑上有没有问题,在单机上测试运行,主要通过利用多线程模拟分布式运行。在刚接触spark时,使用的就是这个模式,但发现这个模式可以加载本地文件,不能读取hdfs上的文件。可能还需要配置一下,具体怎么做再研究下。(先给自己挖个坑)
(2)spark-shell(脚本运行模式:调用scala文件批量运行--适用大部分线下需求)
上面方法需要在交互窗口中一条一条的输入scala程序;如果想把scala程序保存在test.scala文件中,一次运行该文件中的程序代码,可通过如下方式:
sudo spark-shell --executor-memory 5g --driver-memory 1g --master yarn < test.scala
sudo spark-shell --executor-memory 5g --driver-memory 1g --master local < HelloWorld.scala
(3)spark-submit (程序部署模式:与shell无关模式--适用线上需要执行的例行流程)
Spark提供了一个容易上手的应用程序部署工具bin/spark-submit,可以完成Spark应用程序在local、Standalone、YARN、Mesos上的快捷部署。可以指定集群资源master,executor/ driver的内存资源等。
sudo spark-submit --masterspark://192.168.180.216:7077 --executor-memory 5g --class mypackage.test workcount.jar hdfs://192.168.180.79:9000/user/input.txt
workcount .scala 代码打包 workcount.jar,并将文件需要上传到安装有spark的服务器下; hdfs://192.168.180.79:9000/user/input.txt为输入参数;可参考如下网址进行操作:
https://blog.csdn.net/xiaoran_zhu/article/details/50370775
亲测打包经历见下一篇随笔~~
小白学习Spark系列一:Spark简介的更多相关文章
- Spark系列—01 Spark集群的安装
一.概述 关于Spark是什么.为什么学习Spark等等,在这就不说了,直接看这个:http://spark.apache.org, 我就直接说一下Spark的一些优势: 1.快 与Hadoop的Ma ...
- Spark系列—02 Spark程序牛刀小试
一.执行第一个Spark程序 1.执行程序 我们执行一下Spark自带的一个例子,利用蒙特·卡罗算法求PI: 启动Spark集群后,可以在集群的任何一台机器上执行一下命令: /home/spark/s ...
- [纯小白学习OpenCV系列]官方例程00:世界观与方法论
2015-11-11 ----------------------------------------------------------------------------------- 其实,写博 ...
- [纯小白学习OpenCV系列]官方例程01:Load and Display an Image
Version: OpenCV 2.4.9 IDE : VS2010 OS : Windows --------------------------------------------- ...
- 步步为营 SharePoint 开发学习笔记系列总结
转:http://www.cnblogs.com/springyangwc/archive/2011/08/03/2126763.html 概要 为时20多天的sharepoint开发学习笔记系列终于 ...
- 小白学习Spark系列六:Spark调参优化
前几节介绍了下常用的函数和常踩的坑以及如何打包程序,现在来说下如何调参优化.当我们开发完一个项目,测试完成后,就要提交到服务器上运行,但运行不稳定,老是抛出如下异常,这就很纳闷了呀,明明测试上没问题, ...
- Spark入门实战系列--1.Spark及其生态圈简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .简介 1.1 Spark简介 年6月进入Apache成为孵化项目,8个月后成为Apache ...
- Spark入门实战系列--8.Spark MLlib(上)--机器学习及SparkMLlib简介
[注]该系列文章以及使用到安装包/测试数据 可以在<倾情大奉送--Spark入门实战系列>获取 .机器学习概念 1.1 机器学习的定义 在维基百科上对机器学习提出以下几种定义: l“机器学 ...
- Spark2.0学习(一)--------Spark简介
官网对Spark的介绍 http://spark.apache.org/ Apache Spark™ is a unified analytics engine for large-scale dat ...
随机推荐
- python下的线程 进程,以及如何实现并发服务器
在一个CPU(一核)的电脑上, 程序的运行是并发运行的,调度的算法叫时间片轮转法,也叫轮询法 在多CPU(多核)的电脑上,一个CPU跑一个程序,刚程序运行数量小于核心数时,程序是并行的 并发:看上去一 ...
- ACdream 1735 输油管道
输油管道 Time Limit: 2000/1000MS (Java/Others) Memory Limit: 262144/131072KB (Java/Others) Problem Des ...
- dubbo-dubboAdmin安装(一)
简介 Dubbo是什么? dubbo是阿里开源的分布式服务治理框架,对服务的负载均衡,权重,监控,路由规则,禁用启用的管理,以及服务的自动注册和发现 分布式架构下面临问题 在分布式架构下,我们会将一个 ...
- [bzoj5118]Fib数列2_费马小定理_矩阵乘法
Fib数列2 bzoj-5118 题目大意:求Fib($2^n$). 注释:$1\le n\le 10^{15}$. 想法:开始一看觉得一定是道神题,多好的题面啊?结果...妈的,模数是质数,费马小定 ...
- Column注解的的RetentionPolicy的属性值是RUTIME,这样注解处理器可以通过反射,获取到该注解的属性值,从而去做一些运行时的逻辑处理
1.Column注解的的RetentionPolicy的属性值是RUTIME,这样注解处理器可以通过反射,获取到该注解的属性值,从而去做一些运行时的逻辑处理 2. 自定义注解: 使用@interfac ...
- apple 团队电话
back 苹果电话:400 670 18552 这个是国内能打通的
- C语言学习笔记:15_c语言中的进制操作.c
/* * 15_c语言中的进制操作.c * * Created on: 2015年7月5日 * Author: zhong */ #include <stdio.h> #include & ...
- PHP自己定义函数及数组
个人原创博客:http://www.phpthinking.com/archives/350 一.自己定义函数 自己定义函数就是我们自己定义的函数.在PHP中自己定义函数格式例如以下: 1 funct ...
- JVM —— Java 对象占用空间大小计算
零. 为什么要知道 Java 对象占用空间大小 缓存的实现: 在设计 JVM 内缓存时(不是借助 Memcached. Redis 等), 须要知道缓存的对象是否会超过 JVM 最大堆限制, 假设会超 ...
- ijkplayer视频播放
http://android-doc.com/androiddocs/2017/1018/5416.html https://www.2cto.com/kf/201801/714366.html ...