python+caffe训练自己的图片数据流程
1. 准备自己的图片数据
选用部分的Caltech数据库作为训练和测试样本。Caltech是加州理工学院的图像数据库,包含Caltech101和Caltech256两个数据集。该数据集是由Fei-FeiLi, Marco Andreetto, Marc 'Aurelio Ranzato在2003年9月收集而成的。Caltech101包含101种类别的物体,每种类别大约40到800个图像,大部分的类别有大约50个图像。Caltech256包含256种类别的物体,大约30607张图像。图像如下图所示,下载链接为:http://www.vision.caltech.edu/Image_Datasets/Caltech101/
Caltech其中的airplanes、Faces、Motorbikes、watch 4个类别分别包含800、435、798、239张图片,选用这4种图片训练和测试数据。
airplanes:

Faces:

Motorbikes:
watch:

2. 图片重命名
为了清楚的分类,收集的图片按照各自的分类重命名一下(该过程也可以省略),airplanes、Faces、Motorbikes和watch类别中的图片分别以0、1、2、和3作为名称的第一个字母(如上图所示,已经做好了重命名),代表自己的分类。python实现的文件批量重命名:
import os
def renameImage(pathFile,label):
startNum=0
for files in os.listdir(pathFile):
oldDir=os.path.join(pathFile,files)
if os.path.isdir(oldDir):
continue
filename=os.path.splitext(files)[0]
filetype=os.path.splitext(files)[1]
newDir=os.path.join(pathFile,str(label)+'_'+str(startNum)+filetype)
os.rename(oldDir,newDir)
startNum+=1
print(oldDir+' 重命名为: '+newDir)
renameImage('D:\\0704\\Motorbikes',2)renameImage函数第一个参数是需要重命名的文件所在文件夹路径,第二个参数是图片分类。
3. 灰度图转换&&图片大小统一
Caltech中的图片是三通道彩色图片,大小不统一,需要修改成单通道灰度图片,统一修改成64*64大小:
import cv2
import os
import numpy
def Resize(pathFile,reSizeFile):
for files in os.listdir(pathFile):
imagePathFile=os.path.join(pathFile,files)
img=cv2.imread(imagePathFile,0)
imgResize=cv2.resize(img,(64,64),interpolation=cv2.INTER_CUBIC)
reSizeDir=os.path.join(reSizeFile,files)
cv2.imwrite(reSizeDir,imgResize)
print(imagePathFile+' 调整大小成功,存放路径在: '+reSizeFile)
Resize('D:\\0704\\Motorbikes','D:\\0704\\RMotorbikes')第一个参数是的图片文件所在路径,第二个参数是保存路径。
4. 生成Label文件
图片准备好之后开始制作label标签文件,格式是 “xx.jpg 0”,python实现:
import os
def maketxtList(imageFile,pathFile,label):
fobj=open(pathFile,'a')
for files in os.listdir(imageFile):
fobj.write('\n'+files+' '+str(label))
print(files+' '+str(label)+' 写入成功!')
fobj.close()
maketxtList('D:\\0704\\Testwatch','D:\\0704\\testLabel.txt',3)第一个参数是在第3步处理好的图片路径,第二个参数是生成的标签文件,第三个参数是标签,生成的标签如下:
测试数据集分别取airplanes、Faces、Motorbikes、watch各200、200、200、100张图片共700张,按同样的方法生成测试标签。
5. 转化成lmdb数据库文件
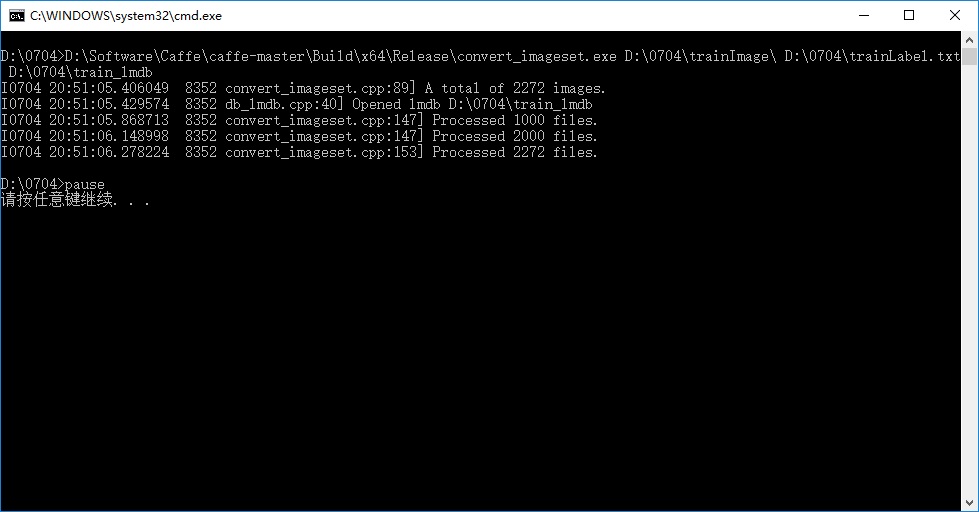
新建一个MakeLmdb.bat的脚本文件,使用caffe中的convert_imageset.exe工具转化图片数据为lmdb数据文件:
D:\Software\Caffe\caffe-master\Build\x64\Release\convert_imageset.exe
D:\0704\testImage\ D:\0704\testLabel.txt D:\0704\test_lmdb
pause执行结果:
分别生成train_lmdb和 test_lmdb文件:
6. 计算均值文件mean.binaryproto
计算均值文件备用:
D:\Software\Caffe\caffe-master\Build\x64\Release\compute_image_mean.exe
D:\0704\test_lmdb D:\0704\mean_test.binaryproto
pause7. 建立CNN网络和训练参数
CNN网络和训练参数文件使用caffe中mnist例子中的 “lenet_train_test.prototxt” 和 “lenet_solver.prototxt”两个文件,做一些参数修改:
lenet_solve.prototxt文件参数修改:
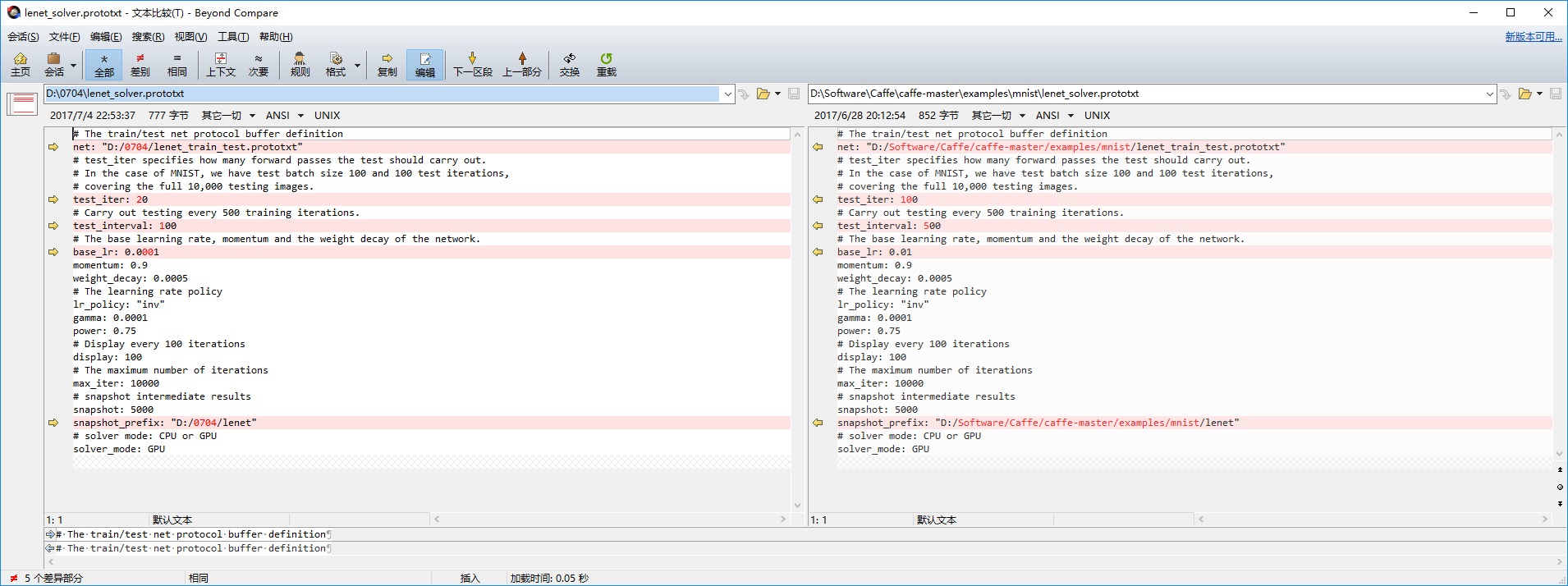
测试数据量比较少,这里的test_iter参数修改为20,另一个就是基础学习率设置为0.0001,这个参数比较重要,需要根据实际情况调整,如果按照之前学习率设置为0.01的话,会出现训练过程中loss一直保持87.3365(其实已经溢出了)这个值不变的情况。
lenet_train_test.prototxt文件参数修改:
1. 修改训练和测试lmdb数据路径和训练数据每组包含数据(batch_size),这里的batch_size不宜设置过小,建议最少为20:
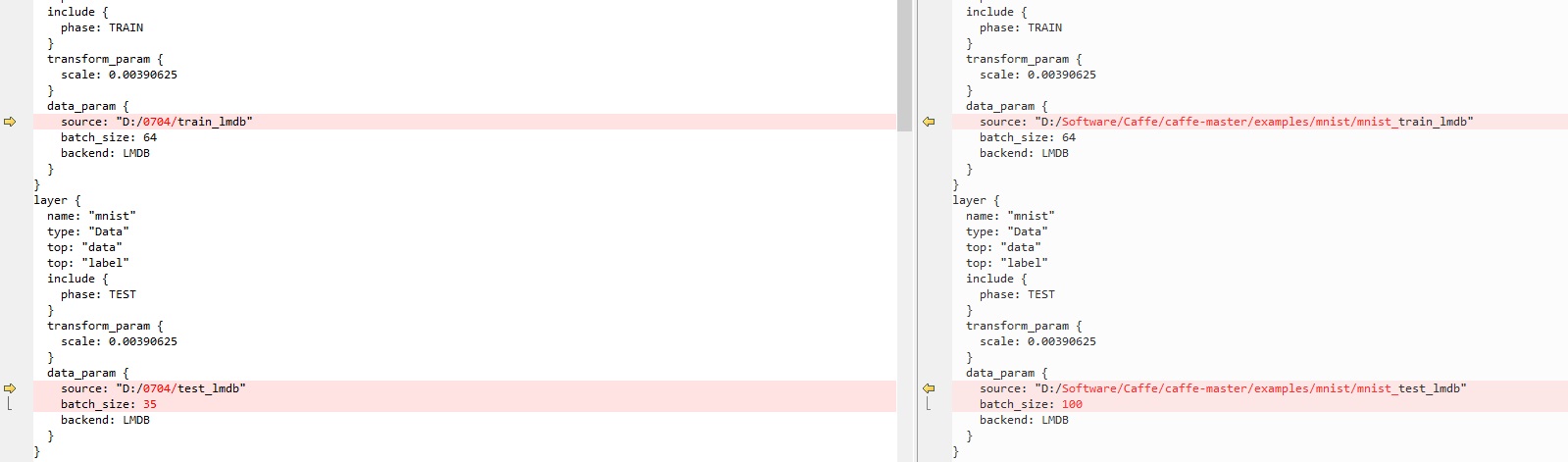
2. 修改输出层 ip2中的输出由10改为4,这里的4代表训练分为4种分类:

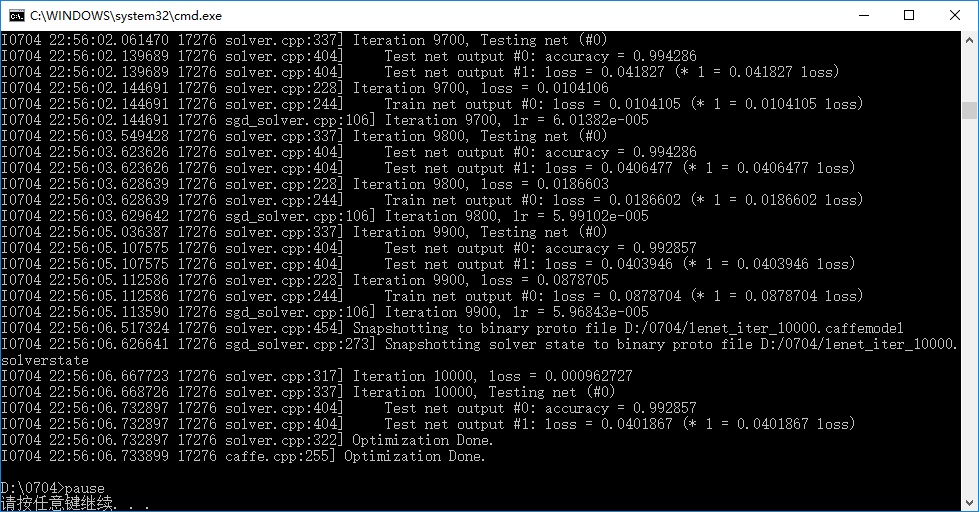
8. 执行训练
D:\Software\Caffe\caffe-master\Build\x64\Release\caffe.exe
train --solver=D:\0704\lenet_solver.prototxt
pause 训练结果,accuracy为0.9928:
python+caffe训练自己的图片数据流程的更多相关文章
- caffe训练自己的图片进行分类预测--windows平台
caffe训练自己的图片进行分类预测 标签: caffe预测 2017-03-08 21:17 273人阅读 评论(0) 收藏 举报 分类: caffe之旅(4) 版权声明:本文为博主原创文章,未 ...
- Caffe初试(三)使用caffe的cifar10网络模型训练自己的图片数据
由于我涉及一个车牌识别系统的项目,计划使用深度学习库caffe对车牌字符进行识别.刚开始接触caffe,打算先将示例中的每个网络模型都拿出来用用,当然这样暴力的使用是不会有好结果的- -||| ,所以 ...
- 实践详细篇-Windows下使用Caffe训练自己的Caffemodel数据集并进行图像分类
三:使用Caffe训练Caffemodel并进行图像分类 上一篇记录的是如何使用别人训练好的MNIST数据做训练测试.上手操作一边后大致了解了配置文件属性.这一篇记录如何使用自己准备的图片素材做图像分 ...
- 使用caffe训练自己的图像数据(未完)
参考博客:blog.csdn.net/drrlalala/article/details/47274549 1,首先在网上下载图片,猫和狗.直接保存下载该网页,会生成一个有图片的文件夹.caffe-m ...
- 使用LeNet训练自己的手写图片数据
一.前言 本文主要尝试将自己的数据集制作成lmdb格式,送进lenet作训练和测试,参考了http://blog.csdn.net/liuweizj12/article/details/5214974 ...
- Python库 - Albumentations 图片数据增强库
Python图像处理库 - Albumentations,可用于深度学习中网络训练时的图片数据增强. Albumentations 图像数据增强库特点: 基于高度优化的 OpenCV 库实现图像快速数 ...
- 使用caffe训练mnist数据集 - caffe教程实战(一)
个人认为学习一个陌生的框架,最好从例子开始,所以我们也从一个例子开始. 学习本教程之前,你需要首先对卷积神经网络算法原理有些了解,而且安装好了caffe 卷积神经网络原理参考:http://cs231 ...
- caffe训练数据流程
cifar10训练实例 1. 下载数据 # sudo sh data/cifar10/get_cifar10.sh 2. 转换数据格式为lmdb # sudo sh examples/cifar10/ ...
- caffe简易上手指南(二)—— 训练我们自己的数据
训练我们自己的数据 本篇继续之前的教程,下面我们尝试使用别人定义好的网络,来训练我们自己的网络. 1.准备数据 首先很重要的一点,我们需要准备若干种不同类型的图片进行分类.这里我选择从ImageNet ...
随机推荐
- QFileSystemModel只显示名称,不显示size,type,modified
Qt 提供的 QFileSystemModel可以提供文件目录树预览功能,但是预览的都自带了Name,size,type, modified等信息.我现在只想显示name这一列,不想显示size,ty ...
- 【NOI 2015】 程序自动分析
[题目链接] https://www.lydsy.com/JudgeOnline/problem.php?id=4195 [算法] 并查集 [代码] #include<bits/stdc++.h ...
- 【转】iOS多语言本地化(国际化)设置
原文网址:http://www.jianshu.com/p/2b7743ae9c90 讨论的iOS应用中的多语言设置,Ok 一般是两种情况: 1.根据当前设备语言自动切换显示 2.在应用中可进行语言设 ...
- 关于PHP函数
从这里我开始聊一些php相关的东西了,因为视频教程里并没有讲到过多的JS,JQ,XML和AJAX,这些在后续自学之后再写一些: 有关php的基本语法数据类型什么的就不做介绍了,在PHP手册或各大学习网 ...
- css+html应用实例1:滑动门技术的简单实现
关于滑动门,现在的页面中好多地方都会用到滑动门,一般用作于导航背景,它的官方解释如下: 滑动门:根据文本自适应大小,根据背景的层叠性制作,并允许他们在彼此之上进行滑动,以创造出一些特殊的效果. 为什么 ...
- visio中如何取消跨线和去掉页边距
比较来说,写论文visio和inkscape都不可缺少. 比如visio跨线的问题,已经遇到过两次忘记了.这次截个图作为记录.其实就是在“设计”一栏里,把连接线里面的跨线显示的对勾去掉即可. *** ...
- 常用几个空格的 Unicode 码
const SPACE_UNICODE = { 'ensp': '\u2002', 'emsp': '\u2003', 'nbsp': '\u00a0' }
- Linux网络配置、文件及命令
Linux的网络配置是曾一直是我学习Linux的埋骨之地,投入了大量的精力和心神但是自己的虚拟机就是联不了网.原来一个大意,我一躺就是一年半.在这里简单的谈谈我对网络的微微认识. VMware的联网模 ...
- Unity5.X 开发资源介绍
Asset 资源 Category 类别 Publisher 开发商 Rating 评级 Version 版本号 Windows → Asset Store 资源商店 [Ctrl + 9] U ...
- IOS - No provisioning profiles with a valid signing identity 一种解决方法
1.删除原有“钥匙串访问”中疑是过期的的证书: 2.在Member Center中Certificate中删除疑是有问题的Certificate,重新添加新的Certificate: 3.在“钥匙串访 ...