elasticsearch index之Translog
跟大多数分布式系统一样,es也通过临时写入写操作来保证数据安全。因为lucene索引过程中,数据会首先据缓存在内存中直到达到一个量(文档数或是占用空间大小)才会写入到磁盘。这就会带来一个风险,如果在写入磁盘前系统崩溃,那么这些缓存数据就会丢失。es通过translog解决了这个问题,每次写操作都会写入一个临时文件translog中,这样如果系统需要恢复数据可以从translog中读取。本篇就主要分析translog的结构及写入方式。
这一部分主要包括两部分translog和tanslogFile,前者对外提供了对translogFile操作的相关接口,后者则是具体的translogFile,它是具体的文件。首先看一下translogFile的继承关系,如下图所示:
实现了两种translogFile,它们的最大区别如名字所示就是写入时是否缓存。FsTranslogFile的接口如下所示:
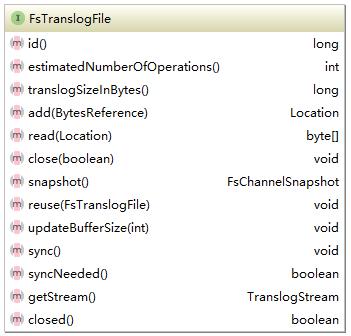
每一个translogFile都会有一个唯一Id,两个非常重要的方法add和write。add是添加对应的操作,这些操作都是在translog中定义,这里写入的只是byte类型的文件,不关注是何种操作。所有的操作都是顺序写入,因此读取的时候需要一个位置信息。add方法代码如下所示:
public Translog.Location add(BytesReference data) throws IOException {
rwl.writeLock().lock();//获取读写锁,每个文件的写入都是顺序的。
try {
operationCounter++;
long position = lastPosition;
if (data.length() >= buffer.length) {
flushBuffer();
// we use the channel to write, since on windows, writing to the RAF might not be reflected
// when reading through the channel
data.writeTo(raf.channel());//写入数据
lastWrittenPosition += data.length();
lastPosition += data.length();//记录位置
return new Translog.Location(id, position, data.length());//返回由id,位置及长度确定的操作位置信息。
}
if (data.length() > buffer.length - bufferCount) {
flushBuffer();
}
data.writeTo(bufferOs);
lastPosition += data.length();
return new Translog.Location(id, position, data.length());
} finally {
rwl.writeLock().unlock();
}
}
这是SimpleTranslogFile写入操作,BufferedTransLogFile写入逻辑基本相同,只是它不会立刻写入到硬盘,先进行缓存。另外TranslogFile还提供了一个快照的方法,该方法返回一个FileChannelSnapshot,可以通过它next方法将translogFile中所有的操作都读出来,写入到一个shapshot文件中。代码如下:
public FsChannelSnapshot snapshot() throws TranslogException {
if (raf.increaseRefCount()) {
boolean success = false;
try {
rwl.writeLock().lock();
try {
FsChannelSnapshot snapshot = new FsChannelSnapshot(this.id, raf, lastWrittenPosition, operationCounter);
snapshot.seekTo(this.headsuccess = true;
returnerSize);
snapshot;
} finally {
rwl.writeLock().unlock();
}
} catch (FileNotFoundException e) {
throw new TranslogException(shardId, "failed to create snapshot", e);
} finally {
if (!success) {
raf.decreaseRefCount(false);
}
}
}
return null;
}
TransLogFile是具体文件的抽象,它只是负责写入和读取,并不关心读取和写入的操作类型。各种操作的定义及对TransLogFile的定义到在Translog中。它的接口如下所示:

这里的写入(add)就是一个具体的操作,这是一个外部调用接口,索引、删除等修改索引的操作都会构造一个对应的Operation在对索引进行相关操作的同时调用该方法。这里还要着重说明一下makeTransientCurrent方法。操作的写入时刻进行,但是根据配置TransLogFile超过限度时需要删除重新开始一个新的文件。因此在transLog中存在两个TransLogFile,current和transient。当需要更换时需要通过读写锁确保单线程操作,将current切换到transient上来,然后删除之前的current。代码如下所示:
public void revertTransient() {
FsTranslogFile tmpTransient;
rwl.writeLock().lock();
try {
tmpTransient = trans;//交换
this.trans = null;
} finally {
rwl.writeLock().unlock();
}
logger.trace("revert transient {}", tmpTransient);
// previous transient might be null because it was failed on its creation
// for example
if (tmpTransient != null) {
tmpTransient.close(true);
}
}
translog中定义了index,create,delete及deletebyquery四种操作它们都继承自Operation。这四种操作也是四种能够改变索引数据的操作。operation代码如下所示:
static interface Operation extends Streamable {
static enum Type {
CREATE((byte) 1),
SAVE((byte) 2),
DELETE((byte) 3),
DELETE_BY_QUERY((byte) 4);
private final byte id;
private Type(byte id) {
this.id = id;
}
public byte id() {
return this.id;
}
public static Type fromId(byte id) {
switch (id) {
case 1:
return CREATE;
case 2:
return SAVE;
case 3:
return DELETE;
case 4:
return DELETE_BY_QUERY;
default:
throw new ElasticsearchIllegalArgumentException("No type mapped for [" + id + "]");
}
}
}
Type opType();
long estimateSize();
Source getSource();
}
tanslog部分就是实时记录所有的修改索引操作确保数据不丢失,因此它的实现上不上非常复杂。
总结:TransLog主要作用是实时记录对于索引的修改操作,确保在索引写入磁盘前出现系统故障不丢失数据。tanslog的主要作用就是索引恢复,正常情况下需要恢复索引的时候非常少,它以stream的形式顺序写入,不会消耗太多资源,不会成为性能瓶颈。它的实现上,translog提供了对外的接口,translogFile是具体的文件抽象,提供了对于文件的具体操作。
elasticsearch index之Translog的更多相关文章
- elasticsearch index 之 engine
elasticsearch对于索引中的数据操作如读写get等接口都封装在engine中,同时engine还封装了索引的读写控制,如流量.错误处理等.engine是离lucene最近的一部分. engi ...
- ElasticSearch Index操作源码分析
ElasticSearch Index操作源码分析 本文记录ElasticSearch创建索引执行源码流程.从执行流程角度看一下创建索引会涉及到哪些服务(比如AllocationService.Mas ...
- elasticsearch index 之 put mapping
elasticsearch index 之 put mapping mapping机制使得elasticsearch索引数据变的更加灵活,近乎于no schema.mapping可以在建立索引时设 ...
- Elasticsearch Index模块
1. Index Setting(索引设置) 每个索引都可以设置索引级别.可选值有: static :只能在索引创建的时候,或者在一个关闭的索引上设置 dynamic:可以动态设置 1.1. S ...
- elasticsearch index tuning
一.扩容 tag_server当前使用ElasticSearch版本为5.6,此版本单个index的分片是固定的,一旦创建后不能更改. 1.扩容方法1,不适 ES6.1支持split index功能, ...
- Add mappings to an Elasticsearch index in realtime
Changing mapping on existing index is not an easy task. You may find the reason and possible solutio ...
- ElasticSearch Index API && Mapping
ElasticSearch NEST Client 操作Index var indexName="twitter"; var deleteIndexResponse = clie ...
- Elasticsearch index fields 重命名
reindex数据复制,重索引 POST _reindex { "source": { "index": "twitter" }, &quo ...
- elasticsearch index 之 create index(-)
从本篇开始,就进入了Index的核心代码部分.这里首先分析一下索引的创建过程.elasticsearch中的索引是多个分片的集合,它只是逻辑上的索引,并不具备实际的索引功能,所有对数据的操作最终还是由 ...
随机推荐
- 运维派 企业面试题2 创建10个 "十个随机字母_test.html" 文件
Linux运维必会的实战编程笔试题(19题) 企业面试题2: 使用for循环在/tmp/www目录下通过随机小写10个字母加固定字符串test批量创建10个html文件,名称例如为: --[root@ ...
- NOIP 2017 逛公园 记忆化搜索 最短路 好题
题目描述: 策策同学特别喜欢逛公园.公园可以看成一张N个点MM条边构成的有向图,且没有 自环和重边.其中1号点是公园的入口,N号点是公园的出口,每条边有一个非负权值, 代表策策经过这条边所要花的时间. ...
- [POI2005]DWU-Double-row(图论?)
题意 2n 个数站成两排(每个数在 2n个数中最多出现两遍),一次操作可以交换任意一列中两个数,求使每行数不重复的最少操作数. (n<=50000) 题解 说实话,我真没想到图论.(我太菜了) ...
- mysql更改密码与远程管理
set password = ': #在当前用户下更改密码 grant all privileges on *.* to root@"%" identified by " ...
- Spring MVC学习总结(6)——一些Spring MVC的使用技巧
APP服务端的Token验证 通过拦截器对使用了 @Authorization 注解的方法进行请求拦截,从http header中取出token信息,验证其是否合法.非法直接返回401错误,合法将to ...
- [React] Implement a React Context Provider
If you have state that needs to exist throughout your application, then you may find yourself passin ...
- Deferred Rendering(三)反锯齿和半透明问题
Deferred 框架下的AA 前面说过Deferred 框架下无法使用硬件AA.这句话不严谨: Deferred Shading在G-Buffer之后,物体几何信息全被抛弃了,导致兴许每一个像素都独 ...
- 有关c语言指针的总结
#include<stdio.h> void main() { int a[3]={1,3,5};//一维数组 int *num[3]={&a[0],&a[1],& ...
- h5 图片回显
<form method="post" id="imgForm" action ="/hi/holdHead" enctype=&qu ...
- VGA接口时序约束
SF-VGA模块板载VGA显示器DA转换驱动芯片AVD7123,FPGA通过OUPLLN连接器驱动ADV7123芯片产生供给VGA显示器的色彩以及同步信号.SF-CY3核心模块与SF-VGA子模块连接 ...