使用深度学习检测DGA(域名生成算法)——LSTM的输入数据本质上还是词袋模型
from:http://www.freebuf.com/articles/network/139697.html
DGA(域名生成算法)是一种利用随机字符来生成C&C域名,从而逃避域名黑名单检测的技术手段。例如,一个由Cryptolocker创建的DGA生成域xeogrhxquuubt.com,如果我们的进程尝试其它建立连接,那么我们的机器就可能感染Cryptolocker勒索病毒。域名黑名单通常用于检测和阻断这些域的连接,但对于不断更新的DGA算法并不奏效。我们的团队也一直在对DGA进行广泛的研究,并在arxiv发表了一篇关于使用深度学习预测域生成算法的文章。
本文我将为大家介绍一种,简单而有效的DGA生成域的检测技术。我们将利用神经网络(或称之为深度学习)更具体的来讲就是长短期记忆网络(LSTM),来帮助我们检测DGA生成域。首先我们会探讨深度学习的优势,然后我将进一步的通过实例来验证我的论述。
如果你之前对机器学习并不了解,那么我建议你先翻看我之前发布的三篇关于机器学习的文章再来阅读本文,这样会更有助于你的理解。
长短期记忆网络(LSTM)的好处
深度学习近年来在机器学习社区中可以说是占尽风头。深度学习是机器学习中一种基于对数据进行表征学习的方法。其好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。随着数十年的不断发展,深度学习在过去四五年间一直很受欢迎。再加上硬件的不断升级优化(如GPU的并行处理改进),也使得培训复杂网络成为了可能。LSTM是一种RNN的特殊类型,可以学习长期依赖信息,如文本和语言等。LSTM是实现循环神经网络的一个这样的技巧,意味着包含循环的神经网络。LSTM在长时间的学习模式方面非常擅长如文本和言语。在本文的例子中,我将使用它们来学习字符序列(域名)的模式,从而帮助我们识别哪些是DGA生成域哪些不是。
使用深度学习的一大好处就是我们可以省去特征工程这一繁杂的过程。而如果我们使用常规方法来生成一长串特征列表(例如长度,元音,辅音以及n-gram模型),并使用这些特征来识别DGA生成域和非DGA生成域。那么就需要安全人员实时的更新和创建新的特征库,这将是一个异常艰巨和痛苦的过程。其次,一旦攻击者掌握了其中的过滤规则,那么攻击者就可以轻松地通过更新其DGA来逃避我们的检测。而深度学习的自动表征学习能力,也让我们能够更快的适应不断变化的对手。同时,也大大减少了我们人力物力的巨大投入。我们技术的另一个优点是仅对域名进行识别而不使用任何上下文功能,如NXDomains
我们技术的另一个优点是,我们仅对域名进行分类而不使用任何上下文功能如NXDomain。上下文功能的生成往往需要额外昂贵的基础设施(如网络传感器和第三方信誉系统)。令人惊讶的是对于没有上下文信息的LSTM,执行却明显优于它们。如果你想了解更多关于LSTM的相关内容,我推荐大家可以关注:colah的博客和blogdeeplearning.net。
什么是DGA?
首先我们要搞清楚什么是DGA?以及DGA检测的重要性。攻击者常常会使用域名将恶意程序连接至C&C服务器,从而达到操控受害者机器的目的。这些域名通常会被编码在恶意程序中,这也使得攻击者具有了很大的灵活性,他们可以轻松地更改这些域名以及IP。而对于另外一种硬编码的域名,则往往不被攻击者所采用,因为其极易遭到黑名单的检测。
而有了DGA域名生成算法,攻击者就可以利用它来生成用作域名的伪随机字符串,这样就可以有效的避开黑名单列表的检测。伪随机意味着字符串序列似乎是随机的,但由于其结构可以预先确定,因此可以重复产生和复制。该算法常被运用于恶意软件以及远程控制软件上。
我们来简单了解下攻击者和受害者端都做了哪些操作。首先攻击者运行算法并随机选择少量的域(可能只有一个),然后攻击者将该域注册并指向其C2服务器。在受害者端恶意软件运行DGA并检查输出的域是否存在,如果检测为该域已注册,那么恶意软件将选择使用该域作为其命令和控制(C2)服务器。如果当前域检测为未注册,那么程序将继续检查其它域。
安全人员可以通过收集样本以及对DGA进行逆向,来预测哪些域将来会被生成和预注册并将它们列入黑名单中。但DGA可以在一天内生成成千上万的域,因此我们不可能每天都重复收集和更新我们的列表。
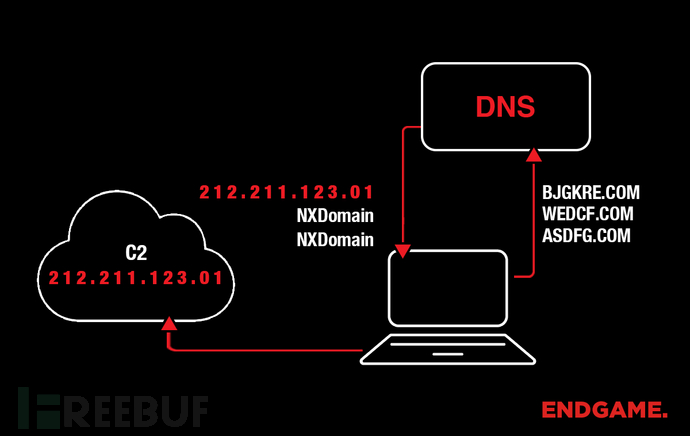
图1展示了许多类型的恶意软件的工作流程。如图所示恶意软件会尝试连接三个域:asdfg.com,wedcf.com和bjgkre.com。前两个域未被注册,并从DNS服务器接收到NXDomain响应。第三个域已被注册,因此恶意软件会使用该域名来建立连接。
见原文。。。
我们提出了使用神经网络来检测DGA的简单技术。该技术不需要使用任何上下文信息(如NXDomains和第三方信誉系统),并且检测效果也远远优于现有的一些技术。本文只是我们关于DGA研究的部分摘要,你可以点击阅读我们在arxiv的完整文章。同时,你也可以对我们发布在github上的代码做进一步的研究学习。
核心代码如下:
"""Train and test LSTM classifier"""
import dga_classifier.data as data
import numpy as np
from keras.preprocessing import sequence
from keras.models import Sequential
from keras.layers.core import Dense, Dropout, Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
import sklearn
from sklearn.cross_validation import train_test_split def build_model(max_features, maxlen):
"""Build LSTM model"""
model = Sequential()
model.add(Embedding(max_features, 128, input_length=maxlen))
model.add(LSTM(128))
model.add(Dropout(0.5))
model.add(Dense(1))
model.add(Activation('sigmoid')) model.compile(loss='binary_crossentropy',
optimizer='rmsprop') return model def run(max_epoch=25, nfolds=10, batch_size=128):
"""Run train/test on logistic regression model"""
indata = data.get_data() # Extract data and labels
X = [x[1] for x in indata]
labels = [x[0] for x in indata] # Generate a dictionary of valid characters
valid_chars = {x:idx+1 for idx, x in enumerate(set(''.join(X)))} max_features = len(valid_chars) + 1
maxlen = np.max([len(x) for x in X]) # Convert characters to int and pad
X = [[valid_chars[y] for y in x] for x in X]
X = sequence.pad_sequences(X, maxlen=maxlen) # Convert labels to 0-1
y = [0 if x == 'benign' else 1 for x in labels] final_data = [] for fold in range(nfolds):
print "fold %u/%u" % (fold+1, nfolds)
X_train, X_test, y_train, y_test, _, label_test = train_test_split(X, y, labels,
test_size=0.2) print 'Build model...'
model = build_model(max_features, maxlen) print "Train..."
X_train, X_holdout, y_train, y_holdout = train_test_split(X_train, y_train, test_size=0.05)
best_iter = -1
best_auc = 0.0
out_data = {} for ep in range(max_epoch):
model.fit(X_train, y_train, batch_size=batch_size, nb_epoch=1) t_probs = model.predict_proba(X_holdout)
t_auc = sklearn.metrics.roc_auc_score(y_holdout, t_probs) print 'Epoch %d: auc = %f (best=%f)' % (ep, t_auc, best_auc) if t_auc > best_auc:
best_auc = t_auc
best_iter = ep probs = model.predict_proba(X_test) out_data = {'y':y_test, 'labels': label_test, 'probs':probs, 'epochs': ep,
'confusion_matrix': sklearn.metrics.confusion_matrix(y_test, probs > .5)} print sklearn.metrics.confusion_matrix(y_test, probs > .5)
else:
# No longer improving...break and calc statistics
if (ep-best_iter) > 2:
break final_data.append(out_data) return final_data
使用深度学习检测DGA(域名生成算法)——LSTM的输入数据本质上还是词袋模型的更多相关文章
- AI安全初探——利用深度学习检测DNS隐蔽通道
AI安全初探——利用深度学习检测DNS隐蔽通道 目录 AI安全初探——利用深度学习检测DNS隐蔽通道 1.DNS 隐蔽通道简介 2. 算法前的准备工作——数据采集 3. 利用深度学习进行DNS隐蔽通道 ...
- 解析基于keras深度学习框架下yolov3的算法
一.前言 由于前一段时间以及实现了基于keras深度学习框架下yolov3的算法,本来想趁着余热将自己的心得体会进行总结,但由于前几天有点事就没有完成计划,现在趁午休时间整理一下. 二.Keras框架 ...
- 深度学习之 rnn 台词生成
深度学习之 rnn 台词生成 写一个台词生成的程序,用 pytorch 写的. import os def load_data(path): with open(path, 'r', encoding ...
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD, R-FCN系列深度学习检测方法梳理
1. R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation 技术路线:selec ...
- R-CNN,SPP-NET, Fast-R-CNN,Faster-R-CNN, YOLO, SSD系列深度学习检测方法梳理
1. R-CNN:Rich feature hierarchies for accurate object detection and semantic segmentation 技术路线:selec ...
- 深度学习(一)——CNN算法流程
深度学习(一)——CNN(卷积神经网络)算法流程 参考:http://dataunion.org/11692.html 0 引言 20世纪60年代,Hubel和Wiesel在研究猫脑皮层中用于局部敏感 ...
- 使用深度学习检测TOR流量——本质上是在利用报文的时序信息、传输速率建模
from:https://www.jiqizhixin.com/articles/2018-08-11-11 可以通过分析流量包来检测TOR流量.这项分析可以在TOR 节点上进行,也可以在客户端和入口 ...
- 惊不惊喜, 用深度学习 把设计图 自动生成HTML代码 !
如何用前端页面原型生成对应的代码一直是我们关注的问题,本文作者根据 pix2code 等论文构建了一个强大的前端代码生成模型,并详细解释了如何利用 LSTM 与 CNN 将设计原型编写为 HTML 和 ...
- 【深度学习】BP反向传播算法Python简单实现
转载:火烫火烫的 个人觉得BP反向传播是深度学习的一个基础,所以很有必要把反向传播算法好好学一下 得益于一步一步弄懂反向传播的例子这篇文章,给出一个例子来说明反向传播 不过是英文的,如果你感觉不好阅读 ...
随机推荐
- java开发必背API
1.java.io.file类,File用于管理文件或目录: 所属套件:java.io File file = new File(fileStringPath); 1)file.mk(),真的会创建一 ...
- HDU5411CRB and Puzzle(矩阵高速幂)
题目链接:传送门 题意: 一个图有n个顶点.已知邻接矩阵.问点能够反复用长度小于m的路径有多少. 分析: 首先我们知道了邻接矩阵A.那么A^k代表的就是长度为k的路径有多少个. 那么结果就是A^0+A ...
- 一些.NET 项目中经常使用的类库
Web自己主动化測试 Watin Selenium Selenium git .net 集合类扩展实现C5 Subscriber/Publisher 模式 Rx Nats 防御式编程 断言库 流 ...
- iOS学习必须了解的七大手势
文章只要你有一点点基础应该就可以看的懂,文章只为学习交流 #import "ViewController.h" @interface ViewController () @prop ...
- 图论之tarjan缩点
缩点,就是把一张有向有环图中的环缩成一个个点,形成一个有向无环图. 首先我介绍一下为什么这题要缩点(有人肯定觉得这是放屁,这不就是缩点的模板题吗?但我们不能这么想,考试的时候不会有人告诉你打什么板上去 ...
- CCS+C6678LE开发记录12:UIA组件的安装
在安装了CCS 6.0版本的IDE和最新版的MCSDK后似乎一切都很完美,但事实并非如此. 当我试图编译SDK附带的image_processing (IPC based) demo时出现如下错误: ...
- Oracle数据库to_date函数注意事项
使用PL/SQL连接到Oracle数据库服务器,执行一条update语句: update pjnl set transtime = to_date('2015-05-14 12:13:20','yyy ...
- proxy in java
[Static] IFeature.java ImpicateF.java Runport.java StaticProxy.java IFeature.java package UProxy.sta ...
- MySQL用户添加和分配权限
mysql数据库insertdelete服务器file mysql> grant 权限1,权限2,…权限n on 数据库名称.表名称 to 用户名@用户地址 identified by ‘连接口 ...
- Linux 安装软件的几种方式
目录 几种安装方式 源代码编译安装 借助软件包管理器安装 二进制格式安装 总结 参考 几种安装方式 源代码编译安装 源代码包的安装一般为下载软件源代码,然后编译安装.常见的 C 程序软件的安装步骤是 ...