[MyBatis]五分钟向MySql数据库插入一千万条数据 批量插入 用时5分左右
本例代码下载:https://files.cnblogs.com/files/xiandedanteng/InsertMillionComparison20191012.rar
我的数据库环境是mysql Ver 14.14 Distrib 5.6.45, for Linux (x86_64) using EditLine wrapper
这个数据库是安装在T440p的虚拟机上的,操作系统为CentOs6.5.
插入一千万条数据,一次执行时间是4m57s,一次是5m。
数据表的定义是这样的:
CREATE TABLE `emp` ( `Id` ) NOT NULL AUTO_INCREMENT, `name` ) DEFAULT NULL, `age` ) DEFAULT NULL, `cdate` timestamp NULL DEFAULT NULL COMMENT 'createtime', PRIMARY KEY (`Id`) ) ENGINE DEFAULT CHARSET=utf8;
这是一个以id为自增主键,包含了三种不同类型字段的简单表。
我使用MyBatis的Batch Insert功能给数据表插入数据,其SQL在Mapper中定义成这样:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd" >
<mapper namespace="com.hy.mapper.EmpMapper">
<select id="selectById" resultType="com.hy.entity.Employee">
select id,name,age,cdate as ctime from emp where id=#{id}
</select>
<insert id="batchInsert">
insert into emp(name,age,cdate)
values
<foreach collection="list" item="emp" separator=",">
(#{emp.name},#{emp.age},#{emp.ctime,jdbcType=TIMESTAMP})
</foreach>
</insert>
</mapper>
与之对应的接口类是这样的:
package com.hy.mapper;
import java.util.List;
import com.hy.entity.Employee;
public interface EmpMapper {
Employee selectById(long id);
int batchInsert(List<Employee> emps);
}
实体类Employee如下:
package com.hy.entity;
import java.text.MessageFormat;
public class Employee {
private long id;
private String name;
private int age;
private String ctime;
public Employee() {
}
public Employee(String name,int age,String ctime) {
this.name=name;
this.age=age;
this.ctime=ctime;
}
public String toString() {
Object[] arr={id,name,age,ctime};
String retval=MessageFormat.format("Employee id={0},name={1},age={2},created_datetime={3}", arr);
return retval;
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public String getCtime() {
return ctime;
}
public void setCtime(String ctime) {
this.ctime = ctime;
}
}
如果插入数据不多可以这样书写:
package com.hy.action;
import java.io.Reader;
import java.util.ArrayList;
import java.util.List;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.apache.log4j.Logger;
import com.hy.entity.Employee;
import com.hy.mapper.EmpMapper;
public class BatchInsert01 {
private static Logger logger = Logger.getLogger(SelectById.class);
public static void main(String[] args) throws Exception{
Reader reader=Resources.getResourceAsReader("mybatis-config.xml");
SqlSessionFactory ssf=new SqlSessionFactoryBuilder().build(reader);
reader.close();
SqlSession session=ssf.openSession();
try {
EmpMapper mapper=session.getMapper(EmpMapper.class);
List<Employee> emps=new ArrayList<Employee>();
emps.add(new Employee("Bill",22,"2018-12-25"));
emps.add(new Employee("Cindy",22,"2018-12-25"));
emps.add(new Employee("Douglas",22,"2018-12-25"));
int changed=mapper.batchInsert(emps);
System.out.println("changed="+changed);
session.commit();
}catch(Exception ex) {
logger.error(ex);
session.rollback();
}finally {
session.close();
}
}
}
如果插入数据多,就必须采用分批提交的方式,我采用的是插入一千个数据后提交一次,然后重复一万次的方式:
package com.hy.action;
import java.io.Reader;
import java.util.ArrayList;
import java.util.List;
import org.apache.ibatis.io.Resources;
import org.apache.ibatis.session.SqlSession;
import org.apache.ibatis.session.SqlSessionFactory;
import org.apache.ibatis.session.SqlSessionFactoryBuilder;
import org.apache.log4j.Logger;
import com.hy.entity.Employee;
import com.hy.mapper.EmpMapper;
public class BatchInsert1000 {
private static Logger logger = Logger.getLogger(SelectById.class);
public static void main(String[] args) throws Exception{
long startTime = System.currentTimeMillis();
Reader reader=Resources.getResourceAsReader("mybatis-config.xml");
SqlSessionFactory ssf=new SqlSessionFactoryBuilder().build(reader);
reader.close();
SqlSession session=ssf.openSession();
try {
EmpMapper mapper=session.getMapper(EmpMapper.class);
String ctime="2017-11-01 00:00:01";
for(int i=0;i<10000;i++) {
List<Employee> emps=new ArrayList<Employee>();
for(int j=0;j<1000;j++) {
Employee emp=new Employee("E"+i,20,ctime);
emps.add(emp);
}
int changed=mapper.batchInsert(emps);
session.commit();
System.out.println("#"+i+" changed="+changed);
}
}catch(Exception ex) {
session.rollback();
logger.error(ex);
}finally {
session.close();
long endTime = System.currentTimeMillis();
logger.info("Time elapsed:" + toDhmsStyle((endTime - startTime)/1000) + ".");
}
}
// format seconds to day hour minute seconds style
// Example 5000s will be formatted to 1h23m20s
public static String toDhmsStyle(long allSeconds) {
String DateTimes = null;
long days = allSeconds / (60 * 60 * 24);
long hours = (allSeconds % (60 * 60 * 24)) / (60 * 60);
long minutes = (allSeconds % (60 * 60)) / 60;
long seconds = allSeconds % 60;
if (days > 0) {
DateTimes = days + "d" + hours + "h" + minutes + "m" + seconds + "s";
} else if (hours > 0) {
DateTimes = hours + "h" + minutes + "m" + seconds + "s";
} else if (minutes > 0) {
DateTimes = minutes + "m" + seconds + "s";
} else {
DateTimes = seconds + "s";
}
return DateTimes;
}
}
最后查询数据库,结果如下:
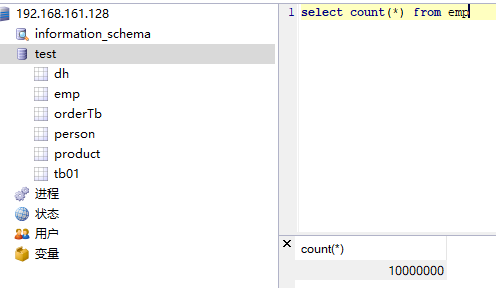
当然插入过程中还有一些插曲,在后继篇章中我会说明。
--END-- 2019年10月12日16:52:14
[MyBatis]五分钟向MySql数据库插入一千万条数据 批量插入 用时5分左右的更多相关文章
- [MyBatis]向MySql数据库插入一千万条数据 批量插入用时6分 之前时隐时现的异常不见了
本例代码下载:https://files.cnblogs.com/files/xiandedanteng/InsertMillionComparison20191012.rar 这次实验的环境仍然和上 ...
- [MyBatis]再次向MySql一张表插入一千万条数据 批量插入 用时5m24s
本例代码下载:https://files.cnblogs.com/files/xiandedanteng/InsertMillionComparison20191012.rar 环境依然和原来一样. ...
- orcle 如何快速插入百万千万条数据
有时候做实验测试数据用到大量数据时可以用以下方法插入: 方法一:使用xmltable create table bqh8 as select rownum as id from xmltable('1 ...
- MySQL数据库实验:任务二 表数据的插入、修改及删除
目录 任务二 表数据的插入.修改及删除 一.利用界面工具插入数据 二.数据更新 (一)利用MySQL命令行窗口更新数据 (二)利用Navicat for MySQL客户端工具更新数据 三.数据库的备份 ...
- mysql 数据库查询最后两条数据
版权声明:本文为博主原创文章,未经博主同意不得转载. https://blog.csdn.net/u011925175/article/details/24186917 有一个mysql数据库的 ...
- WebGIS项目中利用mysql控制点库进行千万条数据坐标转换时的分表分区优化方案
文章版权由作者李晓晖和博客园共有,若转载请于明显处标明出处:http://www.cnblogs.com/naaoveGIS/ 1. 背景 项目中有1000万条历史案卷,为某地方坐标系数据,我们的真实 ...
- java之5分钟插入千万条数据
虽说不一定5分钟就插入完毕,因为取决去所插入的字段,如果字段过多会稍微慢点,但不至于太慢.10分钟内基本能看到结果. 之前我尝试用多线程来实现数据插入(百万条数据),半个多小时才二十多万条数据. 线程 ...
- 使用事务操作SQLite数据批量插入,提高数据批量写入速度,源码讲解
SQLite数据库作为一般单机版软件的数据库,是非常优秀的,我目前单机版的软件产品线基本上全部替换Access作为优选的数据库了,在开发过程中,有时候需要批量写入数据的情况,发现传统的插入数据模式非常 ...
- mysql自定义函数并在存储过程中调用,生成一千万条数据
mysql 自定义函数,生成 n 个字符长度的随机字符串 -- sql function delimiter $$ create function rand_str(n int) returns VA ...
随机推荐
- 使用 visual studio 2019 社区版打开touchgfx工程注意项
@2019-09-23 [环境] touchgfx designer 4.10.0 visual studio 2019 社区版 [问题] #error 1 使用 visual studio 2019 ...
- 八:MVC初始化数据库
生成数据库策略: CreateDatabaseIfNotExists:方法会在没有数据库时创建一个,这是默认行为. DropCreateDatabaseIfModelChanges:如果我们在在模型改 ...
- Java中的集合(上):概述、Collection集合、List集合及其子类
一.集合的体系结构 二.Collection集合 1.基本使用 如下代码 import java.util.ArrayList; import java.util.Collection; public ...
- java——springmvc——注册中央调度器
在WEB-INF下的web.xml中配置 <?xml version="1.0" encoding="UTF-8"?> <web-app xm ...
- git -C <other-git-repo-path> [git-command] 指定其它路径的仓库 执行命令
git -C <other-git-repo-path> [git-command] 指定其它路径的仓库 执行命令 注意,-C 要在命令之前 例如: git -C d:/testRepo ...
- 服务器上的UID按钮
定位用的,比如你机柜上有很多台机器,你在前面按下UID灯,机器后面也有一个UID灯会亮起来,这样当你到后面去的时候你就知道刚才在前面看的是哪一台,另外,有人通过ILO远程端口连接到你的服务器的时候,U ...
- summernote 富文本编辑器限制输入字符长度
项目中需要一个比较简单的富文本编辑器,于是选中了summernote .虽然比较轻量,但是在开发中也遇到了几个问题,在此记录一下. 1:样式和bootstrap冲突,初始化之后显示为: .note-e ...
- Java8-Stream-No.01
import java.util.ArrayList; import java.util.List; import java.util.Optional; public class Streams1 ...
- C# 操作服务命令
安装服务 @echo.服务启动...... @echo off @sc create 服务名称 binPath= " exe地址" @net start 服务名称 @sc conf ...
- keras计算指定层的输出
import keras model = keras.models.Sequential([ keras.layers.Dense(4, activation='relu', input_dim=1, ...