tensorflow分布式运行
1、知识点
"""
单机多卡:一台服务器上多台设备(GPU)
参数服务器:更新参数,保存参数
工作服务器:主要功能是去计算 更新参数的模式:
1、同步模型更新
2、异步模型更新
工作服务器会默认一个机器作为老大,创建会话 tensorflow设备命名规则:
/job:ps/task:0 job:ps,服务器类型 task:0,服务器第几台 /job:worker/task:0/cpu:0
/job:worker/task:0/gpu:0
/job:worker/task:0/gpu:1 设备使用:
1、对集群当中的一些ps,worker进行指定
2、创建对应的服务, ps:创建ps服务 join()
worker创建worker服务,运行模型,程序,初始化会话等等
指定一个默认的worker去做
3、worker使用设备:
with tf.device("/job:worker/task:0/gup:0"):
计算操作
4、分布式使用设备:
tf.train.replica_device_setter(worker_device=worker_device,cluster=cluster)
作用:通过此函数协调不同设备上的初始化操作
worker_device:为指定设备, “/job:worker/task:0/cpu:0” or "/job:worker/task:0/gpu:0"
cluster:集群描述对象
API:
1、分布式会话函数:MonitoredTrainingSession(master="",is_chief=True,checkpoint_dir=None,
hooks=None,save_checkpoint_secs=600,save_summaries_steps=USE_DEFAULT,save_summaries_secs=USE_DEFAULT,config=None)
参数:
master:指定运行会话协议IP和端口(用于分布式) "grpc://192.168.0.1:2000"
is_chief:是否为主worker(用于分布式)如果True,它将负责初始化和恢复基础的TensorFlow会话。
如果False,它将等待一位负责人初始化或恢复TensorFlow会话。
checkpoint_dir:检查点文件目录,同时也是events目录
config:会话运行的配置项, tf.ConfigProto(log_device_placement=True)
hooks:可选SessionRunHook对象列表
should_stop():是否异常停止
run():跟session一样可以运行op
2、tf.train.SessionRunHook
Hook to extend calls to MonitoredSession.run()
1、begin():在会话之前,做初始化工作
2、before_run(run_context)在每次调用run()之前调用,以添加run()中的参数。
ARGS:
run_context:一个SessionRunContext对象,包含会话运行信息
return:一个SessionRunArgs对象,例如:tf.train.SessionRunArgs(loss)
3、after_run(run_context,run_values)在每次调用run()后调用,一般用于运行之后的结果处理
该run_values参数包含所请求的操作/张量的结果 before_run()。
该run_context参数是相同的一个发送到before_run呼叫。
ARGS:
run_context:一个SessionRunContext对象
run_values一个SessionRunValues对象, run_values.results
注:再添加钩子类的时候,继承SessionRunHook
3、tf.train.StopAtStepHook(last_step=5000)指定执行的训练轮数也就是max_step,超过了就会抛出异常
tf.train.NanTensorHook(loss)判断指定Tensor是否为NaN,为NaN则结束
注:在使用钩子的时候需要定义一个全局步数:global_step = tf.contrib.framework.get_or_create_global_step()
"""
2、代码
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("job_name", " ", "启动服务的类型ps or worker")
tf.app.flags.DEFINE_integer("task_index", 0, "指定ps或者worker当中的那一台服务器以task:0 ,task:1")
def main(argv):
# 定义全集计数的op ,给钩子列表当中的训练步数使用
global_step = tf.contrib.framework.get_or_create_global_step()
# 1、指定集群描述对象, ps , worker
cluster = tf.train.ClusterSpec({"ps": ["10.211.55.3:2223"], "worker": ["192.168.65.44:2222"]})
# 2、创建不同的服务, ps, worker
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
# 根据不同服务做不同的事情 ps:去更新保存参数 worker:指定设备去运行模型计算
if FLAGS.job_name == "ps":
# 参数服务器什么都不用干,是需要等待worker传递参数
server.join()
else:
worker_device = "/job:worker/task:0/cpu:0/"
# 3、可以指定设备取运行
with tf.device(tf.train.replica_device_setter(
worker_device=worker_device,
cluster=cluster
)):
# 简单做一个矩阵乘法运算
x = tf.Variable([[1, 2, 3, 4]])
w = tf.Variable([[2], [2], [2], [2]])
mat = tf.matmul(x, w)
# 4、创建分布式会话
with tf.train.MonitoredTrainingSession(
master= "grpc://192.168.65.44:2222", # 指定主worker
is_chief= (FLAGS.task_index == 0),# 判断是否是主worker
config=tf.ConfigProto(log_device_placement=True),# 打印设备信息
hooks=[tf.train.StopAtStepHook(last_step=200)]
) as mon_sess:
while not mon_sess.should_stop():
print(mon_sess.run(mat))
if __name__ == "__main__":
tf.app.run()
3、分布式架构图
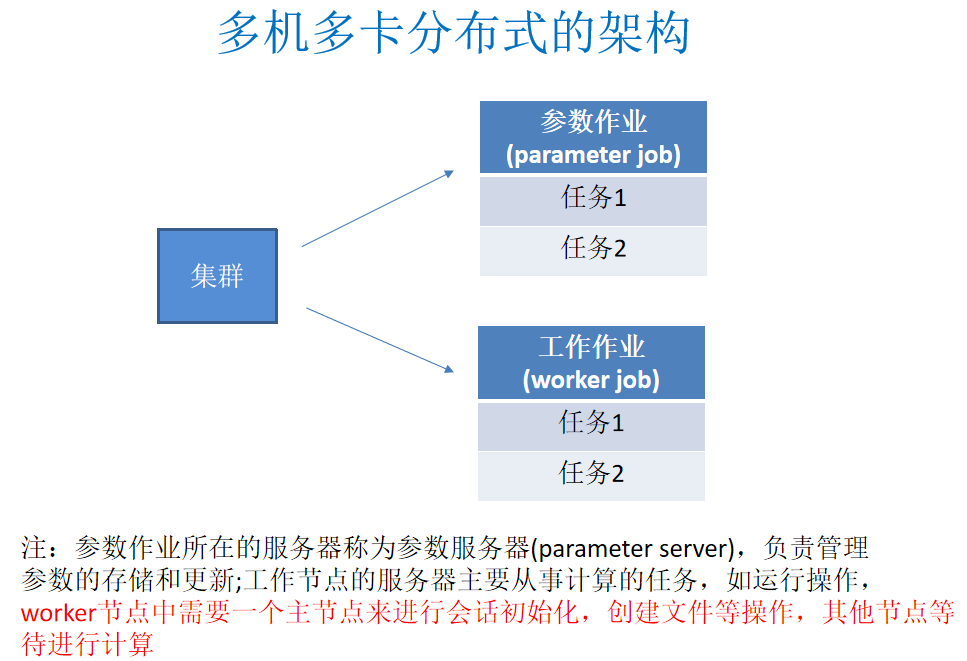
tensorflow分布式运行的更多相关文章
- [源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(1) --- 总体架构 目录 [源码解析] TensorFlow 分布式环境(1) --- 总体架构 1. 总体架构 1.1 集群角度 1.1.1 概念 ...
- [源码解析] TensorFlow 分布式环境(5) --- Session
[源码解析] TensorFlow 分布式环境(5) --- Session 目录 [源码解析] TensorFlow 分布式环境(5) --- Session 1. 概述 1.1 Session 分 ...
- TensorFlow分布式在Amazon AWS上运行
TensorFlow分布式在Amazon AWS上运行 Amazon AWS 提供采用 NVIDIA K8 GPU 的 P2.x 机器.为了能够使用,第一步还需要创建一个 Amazon AWS 账户, ...
- TensorFlow分布式(多GPU和多服务器)详解
本文介绍有关 TensorFlow 分布式的两个实际用例,分别是数据并行(将数据分布到多个 GPU 上)和多服务器分配. 玩转分布式TensorFlow:多个GPU和一个CPU展示一个数据并行的例子, ...
- [翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed ...
- [翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow" 目录 [翻译] TensorFlow ...
- [源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑 目录 [源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑 1. 总述 2. 接口 2.1 ...
- [源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑 目录 [源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑 1. 继承关系 1.1 角 ...
- [源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache 目录 [源码解析] TensorFlow 分布式环境(4) --- WorkerCache 1. WorkerCa ...
随机推荐
- 关于STM32运行时程序卡在B.处的解决方法
文章转载自:https://blog.csdn.net/u014470361/article/details/78780444 背景: 程序运行时,发现程序卡死在B.处. 解决方法: 程序卡死在B.处 ...
- Android 计算器制作 2.注册View 构建函数
鄙人新手 整了 快两天 终于搞定了.. 1.首先是MainActivity 中 在Oncreate函数中 注册 2.按+ 或者 - 号 来分成两大字符串 s1 和 s2 再将s2 分为更小的s1 和 ...
- Visual Studio 2019社区版:错误 MSB6006 “CL.exe”已退出,代码为 2
系统:win10 环境:Visual Studio 2019社区版 问题:错误 MSB6006 “CL.exe”已退出,代码为 2 解决方法: 1 一个类内部的定义返回类型为double的方法种没有写 ...
- Linux日常之命令awk
参考:http://www.zsythink.net/archives/tag/awk/ 一. 命令awk简介 1. awk是一种编程语言,用于对文本和数据进行处理的 2. 具有强大的文本格式化能力 ...
- phpstorm激活码
激活码1 812LFWMRSH-eyJsaWNlbnNlSWQiOiI4MTJMRldNUlNIIiwibGljZW5zZWVOYW1lIjoi5q2j54mIIOaOiOadgyIsImFzc2ln ...
- 单调队列优化&&P1886 滑动窗口题解
单调队列: 顾名思义,就是队列中元素是单调的(单增或者单减). 在某些问题中能够优化复杂度. 在dp问题中,有一个专题动态规划的单调队列优化,以后会更新(现在还是太菜了不会). 在你看到类似于滑动定长 ...
- Js基础知识(四) - js运行原理与机制
js运行机制 本章了解一下js的运行原理,了解了js的运行原理才能写出更优美的代码,提高运行效率,还能解决开发中遇到的不理解的问题. 进程与线程 进程是cpu资源分配的最小单位,进程可以包含多个线程. ...
- BZOJ 2152 / Luogu P2634 [国家集训队]聪聪可可 (点分治/树形DP)
题意 一棵树,给定边权,求满足两点之间的路径上权值和为3的倍数的点对数量. 分析 点分治板题,对每个重心求子树下面的到根的距离模3分别为0,1,2的点的个数就行了. O(3nlogn)O(3nlogn ...
- MongoDB——morphia
禁止保存className:@Entity(noClassnameStored = true) https://stackoverflow.com/questions/17719018/a-field ...
- EOS dice移到1.8版本的修改汇总
EOS dice移到1.8版本的修改汇总 1. CORE_SYMBOL 被去掉了,需要自己在文件中声明eg: uint64_t string_to_symbol_c(uint8_t precision ...