tensorflow分布式运行
1、知识点
"""
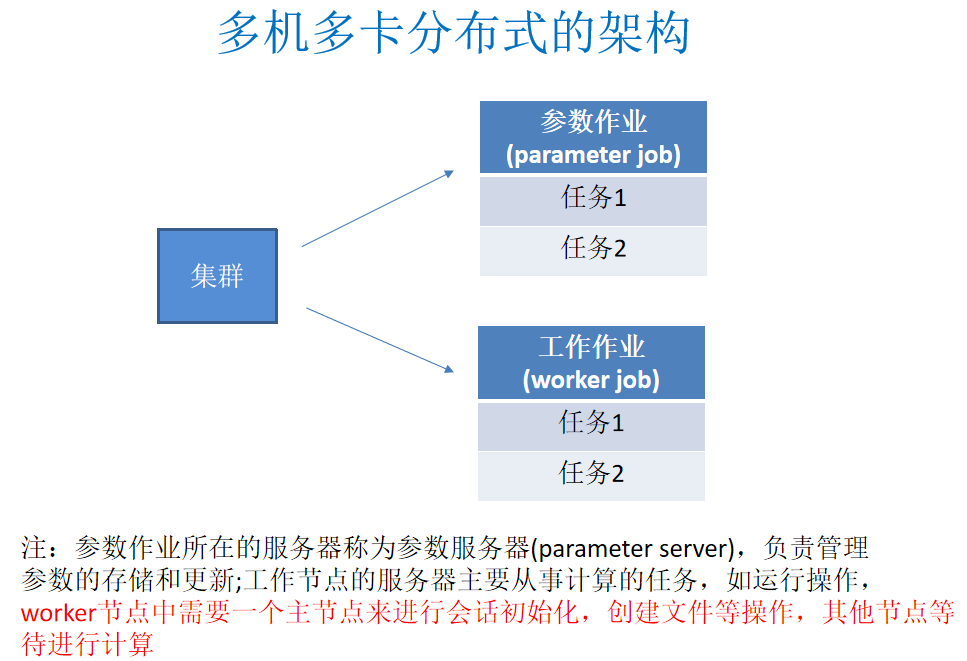
单机多卡:一台服务器上多台设备(GPU)
参数服务器:更新参数,保存参数
工作服务器:主要功能是去计算 更新参数的模式:
1、同步模型更新
2、异步模型更新
工作服务器会默认一个机器作为老大,创建会话 tensorflow设备命名规则:
/job:ps/task:0 job:ps,服务器类型 task:0,服务器第几台 /job:worker/task:0/cpu:0
/job:worker/task:0/gpu:0
/job:worker/task:0/gpu:1 设备使用:
1、对集群当中的一些ps,worker进行指定
2、创建对应的服务, ps:创建ps服务 join()
worker创建worker服务,运行模型,程序,初始化会话等等
指定一个默认的worker去做
3、worker使用设备:
with tf.device("/job:worker/task:0/gup:0"):
计算操作
4、分布式使用设备:
tf.train.replica_device_setter(worker_device=worker_device,cluster=cluster)
作用:通过此函数协调不同设备上的初始化操作
worker_device:为指定设备, “/job:worker/task:0/cpu:0” or "/job:worker/task:0/gpu:0"
cluster:集群描述对象
API:
1、分布式会话函数:MonitoredTrainingSession(master="",is_chief=True,checkpoint_dir=None,
hooks=None,save_checkpoint_secs=600,save_summaries_steps=USE_DEFAULT,save_summaries_secs=USE_DEFAULT,config=None)
参数:
master:指定运行会话协议IP和端口(用于分布式) "grpc://192.168.0.1:2000"
is_chief:是否为主worker(用于分布式)如果True,它将负责初始化和恢复基础的TensorFlow会话。
如果False,它将等待一位负责人初始化或恢复TensorFlow会话。
checkpoint_dir:检查点文件目录,同时也是events目录
config:会话运行的配置项, tf.ConfigProto(log_device_placement=True)
hooks:可选SessionRunHook对象列表
should_stop():是否异常停止
run():跟session一样可以运行op
2、tf.train.SessionRunHook
Hook to extend calls to MonitoredSession.run()
1、begin():在会话之前,做初始化工作
2、before_run(run_context)在每次调用run()之前调用,以添加run()中的参数。
ARGS:
run_context:一个SessionRunContext对象,包含会话运行信息
return:一个SessionRunArgs对象,例如:tf.train.SessionRunArgs(loss)
3、after_run(run_context,run_values)在每次调用run()后调用,一般用于运行之后的结果处理
该run_values参数包含所请求的操作/张量的结果 before_run()。
该run_context参数是相同的一个发送到before_run呼叫。
ARGS:
run_context:一个SessionRunContext对象
run_values一个SessionRunValues对象, run_values.results
注:再添加钩子类的时候,继承SessionRunHook
3、tf.train.StopAtStepHook(last_step=5000)指定执行的训练轮数也就是max_step,超过了就会抛出异常
tf.train.NanTensorHook(loss)判断指定Tensor是否为NaN,为NaN则结束
注:在使用钩子的时候需要定义一个全局步数:global_step = tf.contrib.framework.get_or_create_global_step()
"""
2、代码
import tensorflow as tf
FLAGS = tf.app.flags.FLAGS
tf.app.flags.DEFINE_string("job_name", " ", "启动服务的类型ps or worker")
tf.app.flags.DEFINE_integer("task_index", 0, "指定ps或者worker当中的那一台服务器以task:0 ,task:1")
def main(argv):
# 定义全集计数的op ,给钩子列表当中的训练步数使用
global_step = tf.contrib.framework.get_or_create_global_step()
# 1、指定集群描述对象, ps , worker
cluster = tf.train.ClusterSpec({"ps": ["10.211.55.3:2223"], "worker": ["192.168.65.44:2222"]})
# 2、创建不同的服务, ps, worker
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
# 根据不同服务做不同的事情 ps:去更新保存参数 worker:指定设备去运行模型计算
if FLAGS.job_name == "ps":
# 参数服务器什么都不用干,是需要等待worker传递参数
server.join()
else:
worker_device = "/job:worker/task:0/cpu:0/"
# 3、可以指定设备取运行
with tf.device(tf.train.replica_device_setter(
worker_device=worker_device,
cluster=cluster
)):
# 简单做一个矩阵乘法运算
x = tf.Variable([[1, 2, 3, 4]])
w = tf.Variable([[2], [2], [2], [2]])
mat = tf.matmul(x, w)
# 4、创建分布式会话
with tf.train.MonitoredTrainingSession(
master= "grpc://192.168.65.44:2222", # 指定主worker
is_chief= (FLAGS.task_index == 0),# 判断是否是主worker
config=tf.ConfigProto(log_device_placement=True),# 打印设备信息
hooks=[tf.train.StopAtStepHook(last_step=200)]
) as mon_sess:
while not mon_sess.should_stop():
print(mon_sess.run(mat))
if __name__ == "__main__":
tf.app.run()
3、分布式架构图
tensorflow分布式运行的更多相关文章
- [源码解析] TensorFlow 分布式环境(1) --- 总体架构
[源码解析] TensorFlow 分布式环境(1) --- 总体架构 目录 [源码解析] TensorFlow 分布式环境(1) --- 总体架构 1. 总体架构 1.1 集群角度 1.1.1 概念 ...
- [源码解析] TensorFlow 分布式环境(5) --- Session
[源码解析] TensorFlow 分布式环境(5) --- Session 目录 [源码解析] TensorFlow 分布式环境(5) --- Session 1. 概述 1.1 Session 分 ...
- TensorFlow分布式在Amazon AWS上运行
TensorFlow分布式在Amazon AWS上运行 Amazon AWS 提供采用 NVIDIA K8 GPU 的 P2.x 机器.为了能够使用,第一步还需要创建一个 Amazon AWS 账户, ...
- TensorFlow分布式(多GPU和多服务器)详解
本文介绍有关 TensorFlow 分布式的两个实际用例,分别是数据并行(将数据分布到多个 GPU 上)和多服务器分配. 玩转分布式TensorFlow:多个GPU和一个CPU展示一个数据并行的例子, ...
- [翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed Systems"
[翻译] TensorFlow 分布式之论文篇 "TensorFlow : Large-Scale Machine Learning on Heterogeneous Distributed ...
- [翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow"
[翻译] TensorFlow 分布式之论文篇 "Implementation of Control Flow in TensorFlow" 目录 [翻译] TensorFlow ...
- [源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑
[源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑 目录 [源码解析] TensorFlow 分布式环境(2)---Master 静态逻辑 1. 总述 2. 接口 2.1 ...
- [源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑
[源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑 目录 [源码解析] TensorFlow 分布式环境(3)--- Worker 静态逻辑 1. 继承关系 1.1 角 ...
- [源码解析] TensorFlow 分布式环境(4) --- WorkerCache
[源码解析] TensorFlow 分布式环境(4) --- WorkerCache 目录 [源码解析] TensorFlow 分布式环境(4) --- WorkerCache 1. WorkerCa ...
随机推荐
- 4、nfs(存储服务器)
1.NFS基本概述 NFS是Network File System的缩写及网络文件系统.NFS的主要功能是通过局域网络让不同的主机系统之间可以共享文件或目录. 通常中小企业首选NFS作为集群架构的存储 ...
- centos7初始化bashshell脚本
centos7初始化bashshell脚本 #!/bin/bash if [[ "$(whoami)" != "root" ]]; then echo &quo ...
- C++第五次作业--运算符重载和函数重载
C++ 运算符重载和函数重载 C++ 允许在同一作用域中的某个函数和运算符指定多个定义,分别称为函数重载和运算符重载. 重载声明是指一个与之前已经在该作用域内声明过的函数或方法具有相同名称的声明,但是 ...
- java-消息队列相关-activeMQ
,1,如何防止activeMQ崩溃导致消息丢失呢? 第一点,首先消息需要使用持久化消息,服务挂掉,重启服务后消息依然可以消费,不会丢失: 第二点,ActiveMQ采用主从模式搭建集群,比如搭建3台主从 ...
- 制作自定义系统iso镜像
一.制作自己的ISO启动盘篇 在需要安装特定系统的时候,我们使用原版的linux系统盘镜像来安装,需要手动操作N多步,在机器非常多的环境下,这种方式显然不理想,这是我我们就需要制作我们特定的系统盘来简 ...
- Practical, Dynamic Visibility for Games(可实现动态显示技术)
Practical, Dynamic Visibility for Games(可实现动态显示技术) 原文地址 1引言 游戏场景越来越复杂,包含的内容越来越多,动态显示技术很需要. 本文介绍2种互补的 ...
- WPF程序发布有关事项
- 【Python之路】特别篇--Python切片
字符串切片操作 切片操作符是序列名后跟一个方括号,方括号中有一对可选的数字,并用冒号分割. 注意: 数是可选的,而冒号是必须的. consequence[start:end:step] 切片操作符中的 ...
- pdf缩略图上传控件
一. 功能性需求与非功能性需求 要求操作便利,一次选择多个文件和文件夹进行上传:支持PC端全平台操作系统,Windows,Linux,Mac 支持文件和文件夹的批量下载,断点续传.刷新页面后继续传输. ...
- hihocoder 1457 后缀自动机四·重复旋律7 ( 多串连接处理技巧 )
题目链接 分析 : 这道题对于单个串的用 SAM 然后想想怎么维护就行了 但是多个串下.可以先将所有的串用一个不在字符集( 这道题的字符集是 '0' ~ '9' ) 链接起来.建立后缀自动机之后 在统 ...