CHD-5.3.6集群上sqoop安装
Sqoop(发音:skup)是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。
对于某些Nosql数据库它也提供了连接器。Sqoop,类似于其他ETL工具,使用元数据模型来判断数据类型并在数据从数据源转移到Hadoop时确保类型安全的数据处理。Sqoop专为大数据批量传输设计,能够分割数据集并创建Hadoop任务来处理每个区块。
1.解压:
tar -xvf sqoop-1.4.-cdh5.3.6.tar.gz -C /home/hadoop/CDH5.3.6
2.进去conf目录
/home/hadoop/CDH5.3.6/sqoop-1.4.-cdh5.3.6/conf
3.重命名文件
[hadoop@master conf]$ cp sqoop-env-template.sh sqoop-env.sh
4.修改配置文件sqoop-env.sh
export HADOOP_COMMON_HOME=/home/hadoop/CDH5.3.6/hadoop-2.5.-cdh5.3.6 export HADOOP_MAPRED_HOME=/home/hadoop/CDH5.3.6/hadoop-2.5.-cdh5.3.6 export HIVE_HOME=/home/hadoop/CDH5.3.6/hive-0.13.-cdh5.3.6
5.验证:
查看版本:

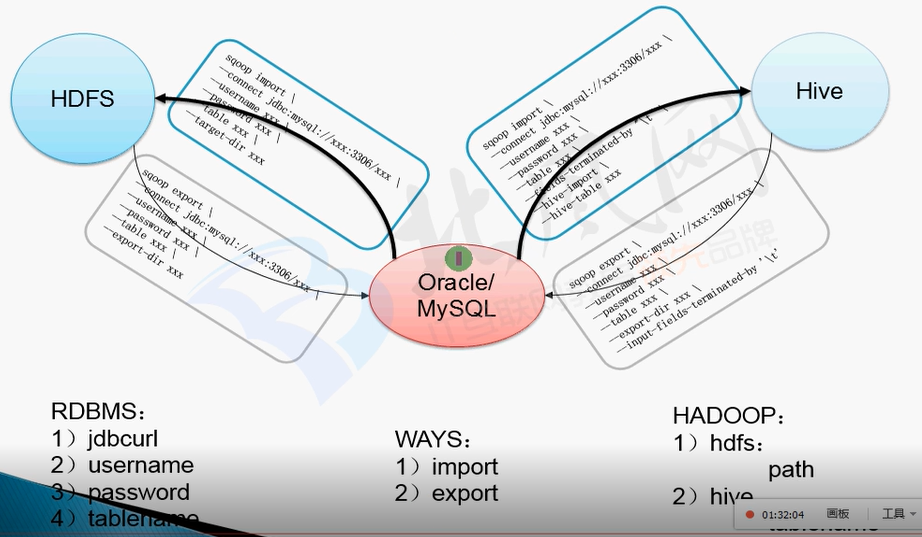
查看命令怎么用:
bin/sqoop help list-databases
链接的是MySQL数据库,需要拷贝一个jdbc驱动包
cp /home/hadoop/CDH5.3.6/hive-0.13.-cdh5.3.6/lib/mysql-connector-java-5.1..jar ./lib/
[hadoop@master lib]$ mysql -u root -p
Enter password:
mysql> update user set host = '%' where user = 'root';
Query OK, row affected (0.00 sec)
Rows matched: Changed: Warnings: mysql> FLUSH PRIVILEGES;
Query OK, rows affected (0.00 sec)
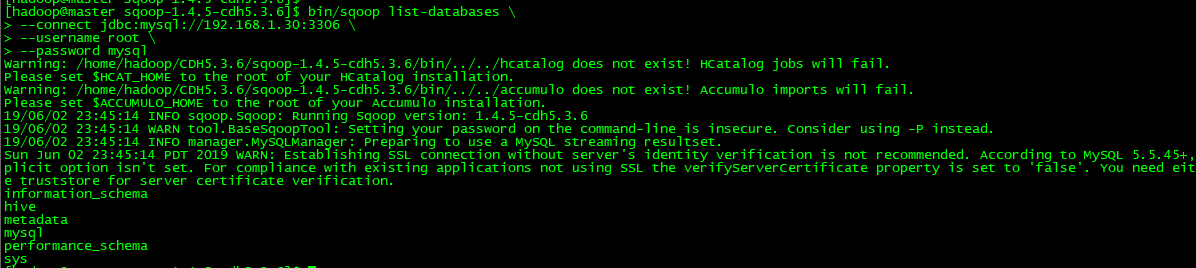
展现数据库有哪些database:
bin/sqoop list-databases \
--connect jdbc:mysql://192.168.1.30:3306 \
--username root \
--password mysql
安装完成,sqoop主要作用于export 、import 导入导出,见下次随笔
CHD-5.3.6集群上sqoop安装的更多相关文章
- CHD-5.3.6集群上Flume安装
Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and ...
- CHD-5.3.6集群上oozie安装
参考文档:http://archive.cloudera.com/cdh5/cdh/5/oozie-4.0.0-cdh5.3.6/DG_QuickStart.html tar -zxvf oozie ...
- CHD-5.3.6集群上hive安装
解压过后: [hadoop@master CDH5.3.6]$ ls -rlttotal 8drwxr-xr-x. 17 hadoop hadoop 4096 Jun 2 16:07 hadoop- ...
- hive1.2.1安装步骤(在hadoop2.6.4集群上)
hive1.2.1在hadoop2.6.4集群上的安装 hive只需在一个节点上安装即可,这里再hadoop1上安装 1.上传hive安装包到/usr/local/目录下 2.解压 tar -zxvf ...
- 在Ubuntu16.04集群上手工部署Kubernetes
目前Kubernetes为Ubuntu提供的kube-up脚本,不支持15.10以及16.04这两个使用systemd作为init系统的版本. 这里详细介绍一下如何以非Docker方式在Ubuntu1 ...
- 在集群上运行caffe程序时如何避免Out of Memory
不少同学抱怨,在集群的GPU节点上运行caffe程序时,经常出现"Out of Memory"的情况.实际上,如果我们在提交caffe程序到某个GPU节点的同时,指定该节点某个比较 ...
- 分布式Hbase-0.98.4在Hadoop-2.2.0集群上的部署
fesh个人实践,欢迎经验交流!本文Blog地址:http://www.cnblogs.com/fesh/p/3898991.html Hbase 是Apache Hadoop的数据库,能够对大数据提 ...
- Hadoop集群上使用JNI,调用资源文件
hadoop是基于java的数据计算平台,引入第三方库,例如C语言实现的开发包将会大大增强数据分析的效率和能力. 通常在是用一些工具的时候都要用到一些配置文件.资源文件等.接下来,借一个例子来说明ha ...
- spark在集群上运行
1.spark在集群上运行应用的详细过程 (1)用户通过spark-submit脚本提交应用 (2)spark-submit脚本启动驱动器程序,调用用户定义的main()方法 (3)驱动器程序与集群管 ...
随机推荐
- JS中的prototype、__proto__与constructor(图解)
作为一名前端工程师,必须搞懂JS中的prototype.__proto__与constructor属性,相信很多初学者对这些属性存在许多困惑,容易把它们混淆,本文旨在帮助大家理清它们之间的关系并彻底搞 ...
- 记录下关于RabbitMQ常用知识点(持续更新)
1.端口及说明: 4369 -- erlang发现口 5672 --client端通信口 15672 -- 管理界面ui端口 25672 -- server间内部通信口 举例说明 我们访问Rabbit ...
- 什么是UEFI
UEFI是什么?也许我们大多数用户对这个概念很模糊.uefi可以做什么,有什么具体的应用?虽然不知道具体是做什么的,但是我们经常会在BIOS设置中发现UEFI的踪迹.因为现在越来越多的电脑已经使用了U ...
- 重置mysql数据库root密码
一. 在已知MYSQL数据库的ROOT用户密码的情况下,修改密码的方法:1,shell环境下:]#mysqladmin –u root –p password “新密码” 回车后要求输入旧密码2,my ...
- Rocketmq-简单部署
一.准备环境 1.系统:Centos7.3(无硬性要求) 2. jdk:1.8 3.maven:3.5(无硬性要求) 4.git 5.rocketmq 4.2 二.环境部署 1.jdk1.8以及mav ...
- [Cometoj#3 C]子序列子序列子序列..._动态规划_数论
子序列子序列子序列... 题目链接:https://cometoj.com/contest/38/problem/C?problem_id=1542 数据范围:略. 题解: 神仙题,感觉这个题比$D$ ...
- TIME_WAIT和CLOSE_WAIT的区别
系统上线之后,通过如下语句查看服务器时,发现有不少TIME_WAIT和CLOSE_WAIT. netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) ...
- Redis 学习笔记(篇八):事件
Redis 服务器是一个事件驱动程序,服务器需要处理以下两类事件: 文件事件: Redis 服务器通过套接字与客户端(或者其他 Redis 服务器)进行连接,而文件事件就是服务器对套接字操作的抽象.服 ...
- 2.1spring cloud 环境配置
前提:SpringBoot可以离开SpringCloud独立使用开发项目,但是SpringCloud离不开SpringBoot,属于依赖的关系. 所以基本是搭建SpringBoot + 组件 = Sp ...
- (十五)mybatis 逆向工程
目录 为什么需要逆向工程 使用方法 如何读懂生成的代码 总结 为什么需要逆向工程 对于数据库中的那么多的表 ,基本的 CRUD 操作 ,以及 mybatis 需要使用的 接口.mapper ,这些工作 ...