06_Hive分桶机制及其作用
1.Clustered By
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分。
Hive也是针对某一列进行桶的组织。Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在
哪个桶当中。
把表(或者分区)组织成桶(Bucket)有两个理由:
(1)获得更高的查询处理效率。桶为表加上了额外的结构,Hive 在处理有些查询时能利用这个结构。具体
而言,连接两个在(包含连接列的)相同列上划分了桶的表,可以使用 Map 端连接 (Map-side join)高效的
实现。比如JOIN操作。对于JOIN操作两个表有一个相同的列,如果对这两个表都进行了桶操作。那么将保存相同
列值的桶进行JOIN操作就可以,可以大大较少JOIN的数据量。
(2)使取样(sampling)更高效。在处理大规模数据集时,在开发和修改查询的阶段,如果能在数据集的一
小部分数据上试运行查询,会带来很多方便。
2.分桶
分桶是相对分区进行更细粒度的划分,它是相当于MapReduce中的分区,分桶将整个数据按照某列属性值的hash
值进行区分,例如如果根据id属性分为3个桶,就是对id属性值的hash值对3取摸,按照取模结果对数据分桶。如取
模结果为0的数据记录存放到一个文件,取模为1的数据存放到一个文件,取模为2的数据存放到一个文件
1.创建带桶的表:导入的数据已经是被分好桶和排好序的

在分桶之前要执行命令:set hive.enforce.bucketing = true; set mapreduce.job.reduces=4;从而设置分桶
为true,并且reduce数量是分桶的数量个数;
关键字clustered by 指定分区依据的列名;
与分区不同的是,分区依据的不是真实数据表文件中的列,而是我们指定的伪列,但是分桶是依据数据表中真实
的列而不是伪列。所以在指定分区依据的列的时候要指定列的类型,因为在数据表文件中不存在这个列,相当于新建
一个列。而分桶依据的是表中已经存在的列,这个列的数据类型显然是已知的,所以不需要指定列的类型
如上只是说明了表会分桶,具体的分区需要在插入数据时产生。最好的插入数据方式是insert into table;
2.带桶的表中插入select数据(Cluster by(id)):表示根据id分桶并排序
cluster by和sort by不能放在一起查询

按照上面的分桶结果会在表目录下产生多个文件:/user/hive/warehouse/test_db/t_buk/
查看文件信息:
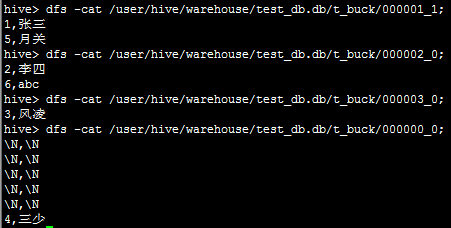
3.带桶的表中插入select数据(distribute by (id) sort by (id)):

按照上面的分桶结果会在表目录下产生多个文件:/user/hive/warehouse/test_db/t_buk/
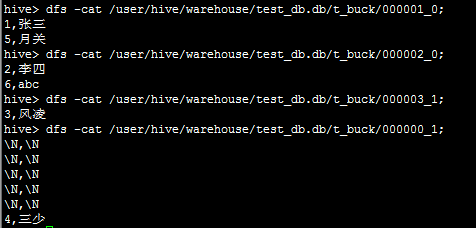
如上的的sql查询语句实际上是根据id作为key进行key.hashcode%4产生四个区,即就是用distribute by (id)
来指定分区字段,使用sort by (id)指定排序字段
总结:
因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by
如果将reduce数量设置为4,使用select * from t_test order by name;就会强制将reduce设置为1,会得到全局结果;
SELECT语法操作:
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
]
[LIMIT number] 注:1、order by 会对输入做全局排序,因此只有一个reducer,会导致当输入规模较大时,需要较长的计算时间。
2、sort by不是全局排序,其在数据进入reducer前完成排序。因此,如果用sort by进行排序,并且设置mapred.reduce.tasks>1,
则sort by只保证每个reducer的输出有序,不保证全局有序。
3、distribute by(字段)根据指定的字段将数据分到不同的reducer,且分发算法是hash散列。
4、Cluster by(字段) 除了具有Distribute by的功能外,还会对该字段进行排序。 因此,如果分桶和sort字段是同一个时,此时,cluster by = distribute by + sort by 分桶表的作用:最大的作用是用来提高join操作的效率;
(思考这个问题:select a.id,a.name,b.addr from a join b on a.id = b.id;
如果a表和b表已经是分桶表,而且分桶的字段是id字段,那么做这个操作的时候就不需要再进行全表笛卡尔积了。但是如果标注了分桶但是实际上数据并没有分桶,那么结果就会出问题。
06_Hive分桶机制及其作用的更多相关文章
- Hive为什么要分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- Hive学习笔记——Hive中的分桶
对于每一个表(table)或者分区, Hive可以进一步组织成桶,也就是说桶是更为细粒度的数据范围划分.Hive也是针对某一列进行桶的组织.Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记 ...
- HIVE—索引、分区和分桶的区别
一.索引 简介 Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键. Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少MapRed ...
- Hive里的分区、分桶、视图和索引再谈
福利 => 每天都推送 欢迎大家,关注微信扫码并加入我的4个微信公众号: 大数据躺过的坑 Java从入门到架构师 人工智能躺过的坑 Java全栈大联盟 ...
- Hive(六)【分区表、分桶表】
目录 一.分区表 1.本质 2.创建分区表 3.加载数据到分区表 4.查看分区 5.增加分区 6.删除分区 7.二级分区 8.分区表和元数据对应得三种方式 9.动态分区 二.分桶表 1.创建分桶表 2 ...
- hive从入门到放弃(四)——分区与分桶
今天讲讲分区表和分桶表,前面的文章还没看的可以点击链接: hive从入门到放弃(一)--初识hive hive从入门到放弃(二)--DDL数据定义 hive从入门到放弃(三)--DML数据操作 分区 ...
- Hive 的分桶 & Parquet 概念
分区 & 分桶 都是把数据划分成块.分区是粗粒度的划分,桶是细粒度的划分,这样做为了可以让查询发生在小范围的数据上以提高效率. 分区之后,分区列都成了文件目录,从而查询时定位到文件目录,子数据 ...
- linux_shell_根据网站来源分桶
应用场景: 3kw行url+\t+html记录 [网站混合] 需要:按照网站来源分桶输出 执行shell cat */*pack.html|awk -F '\t' '{ split($1,arr,&q ...
- Hive分桶
1.简介 分桶表是对列值取哈希值的方式将不同数据放到不同文件中进行存储.对于hive中每一个表,分区都可以进一步进行分桶.由列的哈希值除以桶的个数来决定数据划分到哪个桶里. 2.适用场景 1.数据抽样 ...
随机推荐
- Install Virtualbox on CentOS7---(後話,最終還是沒有用virtualbox做VM server ,感覺只適用于桌面)
參考: https://wiki.centos.org/zh-tw/HowTos/Virtualization/VirtualBox cd /etc/yum.repos.d wget http://d ...
- 【算法导论】--分治策略Strassen算法(运用下标运算)【c++】
由于偷懒不想用泛型,所以直接用了整型来写了一份 ①首先你得有一个矩阵的class Matrix ②Matrix为了方便用下标进行运算, Matrix的结构如图:(我知道我的字丑...) Matrix. ...
- (3)Linux命令分类汇总(7~12)
Linux命令分类汇总(7~12) (七)用户管理命令(12个) 1 useradd cdgs 添加用户. 2 usermod 修改系统已经存在的用户属性. 3 userdel ...
- HTML的列表表格表单知识点
无序列表格式 ...
- Hadoop 之 HDFS API操作
1. 文件上传 @Slf4j public class HDFSClient { @Test public void testCopyFromLocalFile() throws Exception{ ...
- 《MIT 6.828 Lab 1 Exercise 2》实验报告
本实验链接:mit 6.828 lab1 Exercise2. 题目 Exercise 2. Use GDB's si (Step Instruction) command to trace into ...
- [转帖]Linux systemd 常用命令
Linux systemd 常用命令 https://www.cnblogs.com/tsdxdx/p/7288490.html systemctl hostnamectl timedatectl l ...
- nginx+uwsgi02---django部署(不推荐)
1.文件结构 myweb/ ├── manage.py ├── myweb/ │ ├── __init__.py │ ├── settings.py │ ├── urls.py │ └── wsgi. ...
- python 基础例子 双色球 查询天气 查询电话
# 随机生成双色球import random# 随机数 1-16之间# r = random.randint(1,16)# print(r)phone_numbers_str = "匪警[1 ...
- shell习题第14题:
[题目要求] 需求,根据web服务器的访问日志,把一些请求高的ip给拒绝掉,并且每隔半小时把不再发起请求或者请求量很小的ip给解封 假设: 1. 一分钟内请求量高于100次的ip视为不正常的请求 2. ...