Pandas中DataFrame数据合并、连接(concat、merge、join)之concat
一、concat:沿着一条轴,将多个对象堆叠到一起
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True):
objs:需要连接的对象集合,一般是列表或字典;
axis:连接轴向;
join:参数为‘outer’或‘inner’;
join_axes=[]:指定自定义的索引;
keys=[]:创建层次化索引;
ignore_index=True:重建索引
pd.concat()只是单纯的把两个表拼接在一起,参数axis是关键,它用于指定是行还是列,axis默认是0。
当axis=0时,pd.concat([obj1, obj2])的效果与obj1.append(obj2)是相同的;
当axis=1时,pd.concat([obj1, obj2], axis=1)的效果与pd.merge(obj1, obj2, left_index=True, right_index=True, how='outer')是相同的。merge方法的介绍请参看下文。
import pandas as pd
import numpy as np
random = np.random.RandomState(0) #随机数种子,相同种子下每次运行生成的随机数相同
df1=pd.DataFrame(random.randn(3,4),columns=['a','b','c','d'])
df1
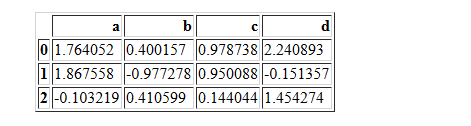
random = np.random.RandomState(0)
df2=pd.DataFrame(random.randn(2,3),columns=['b','d','a'],index=["a1","a2"])
df2

random = np.random.RandomState(1)
df22=pd.DataFrame(random.randn(3,3),columns=['b','d','a'],index=['',"a1","a2"])
df22

当axis=0时
pd.concat([df1,df2],axis=0)
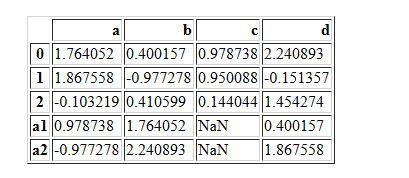
pd.concat([df1,df2],axis=0,join="outer")

df12=df1.append(df2)
df12

pd.concat([df1,df2],axis=0,join="inner")

当axis=1时
pd.concat([df1,df2],axis=1,join='inner')

pd.concat([df1,df1],axis=1,join='inner') #和outer一样
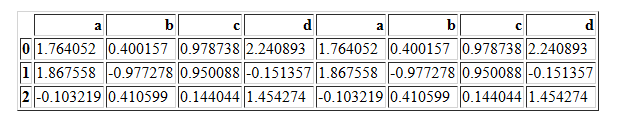
pd.concat([df1,df2],axis=1,join="outer")
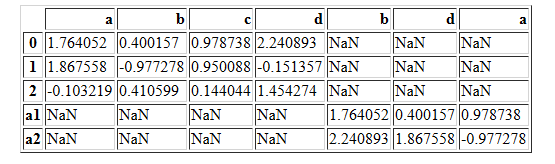
pd.concat([df1,df22],axis=1,join="inner")

pd.concat([df1,df22],axis=1,join="outer")

pd.concat([df1,df1],axis=1,join="outer")

Pandas中DataFrame数据合并、连接(concat、merge、join)之concat的更多相关文章
- Pandas中DataFrame数据合并、连接(concat、merge、join)之merge
二.merge:通过键拼接列 类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来. 该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面 ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之join
pandas.DataFrame.join 自己弄了很久,一看官网.感觉自己宛如智障.不要脸了,直接抄 DataFrame.join(other, on=None, how='left', lsuff ...
- 排序合并连接(sort merge join)的原理
排序合并连接(sort merge join)的原理 排序合并连接(sort merge join)的原理 排序合并连接(sort merge join) 访问次数:两张表都只会访 ...
- Python基础 | pandas中dataframe的整合与形变(merge & reshape)
目录 行的union pd.concat df.append 列的join pd.concat pd.merge df.join 行列转置 pivot stack & unstack melt ...
- Spark与Pandas中DataFrame对比
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Spark与Pandas中DataFrame对比(详细)
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- 将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy
将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy import pandas as pd from sqlalchemy import create_engine ...
- Python3 Pandas的DataFrame数据的增、删、改、查
Python3 Pandas的DataFrame数据的增.删.改.查 一.DataFrame数据准备 增.删.改.查的方法有很多很多种,这里只展示出常用的几种. 参数inplace默认为False,只 ...
- Pandas中DataFrame修改列名
Pandas中DataFrame修改列名:使用 rename df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01- ...
随机推荐
- Linux文件属性改变命令chown-chgrp-chattr-lsattr实践
chown 语法: chattr.lsattr 更改文件属性
- speedtest-cli 命令
speedtest-cli是一个使用python编写的命令行脚本,通过调用speedtest.net测试上下行的接口来完成速度测试,项目地址:https://github.com/sivel/spee ...
- #######【Python】【基础知识】【标准库】目录及学习规划 ######
下述参考Python DOC https://docs.python.org/zh-cn/3/library/index.html 概述 可用性注释 内置函数 内置常量 由 site 模块添加的常量 ...
- Redis(1.9)Redis主从复制
[1]实验环境 CentOS7.5 + Redis4.0.11 架构:原生1主2从,做实验机器有限,从库双实例 主库:192.168.135.170 从库1:192.168.135.171~6379 ...
- 【2018】Python面试题【web框架】
1.谈谈你对http协议的认识. HTTP协议(HyperText Transfer Protocol,超文本传输协议)是用于从WWW服务器传输超文本到本地浏览器的传送协议.它可以使浏览器更加高效,使 ...
- spring-boot 连接数据库(六)
环境 jdk 6 tomcat 6.0.53 sts 4.4.2 maven 3.2.5 mysql 5.7 准备 接下来的数据库操作基于 mysql,所以需要一套可用的 mysql 环境. 引入 j ...
- Vue里标签嵌套限制问题解决------解析DOM模板时注意事项:
受到html本身的一些限制,像<ul>.<ol>.<table>.<select>这样的元素里允许包含的元素有限制,而另一些像<option> ...
- 【一个蒟蒻的挣扎】最小生成树—Kruskal算法
济南集训第五天的东西,这篇可能有点讲不明白提前抱歉(我把笔记忘到别的地方了 最小生成树 概念:一个有 n 个结点的连通图的生成树是原图的极小连通子图,且包含原图中的所有 n 个结点,并且有保持图连通的 ...
- K8s的kubectl常用命令
一. 设置kubectl输入命令自动补全 依次执行一下命令: yum install -y bash-completion source /usr/share/bash-completion/bash ...
- Stardew Valley(星露谷物语)Mod开发之路 写在前面
之前迷上了一款新游戏Stardew Valley,这几天发现游戏为插件开发提供了SMAPI编程接口,玩家可以方便的自定义游戏内容(瞬间感觉因缺思厅,额..),其实这几年的游戏许多都有mod机制,商家机 ...