Pandas中DataFrame数据合并、连接(concat、merge、join)之concat
一、concat:沿着一条轴,将多个对象堆叠到一起
concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False,
keys=None, levels=None, names=None, verify_integrity=False, copy=True):
objs:需要连接的对象集合,一般是列表或字典;
axis:连接轴向;
join:参数为‘outer’或‘inner’;
join_axes=[]:指定自定义的索引;
keys=[]:创建层次化索引;
ignore_index=True:重建索引
pd.concat()只是单纯的把两个表拼接在一起,参数axis是关键,它用于指定是行还是列,axis默认是0。
当axis=0时,pd.concat([obj1, obj2])的效果与obj1.append(obj2)是相同的;
当axis=1时,pd.concat([obj1, obj2], axis=1)的效果与pd.merge(obj1, obj2, left_index=True, right_index=True, how='outer')是相同的。merge方法的介绍请参看下文。
import pandas as pd
import numpy as np
random = np.random.RandomState(0) #随机数种子,相同种子下每次运行生成的随机数相同
df1=pd.DataFrame(random.randn(3,4),columns=['a','b','c','d'])
df1
random = np.random.RandomState(0)
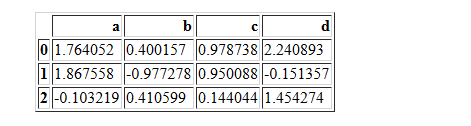
df2=pd.DataFrame(random.randn(2,3),columns=['b','d','a'],index=["a1","a2"])
df2

random = np.random.RandomState(1)
df22=pd.DataFrame(random.randn(3,3),columns=['b','d','a'],index=['',"a1","a2"])
df22

当axis=0时
pd.concat([df1,df2],axis=0)
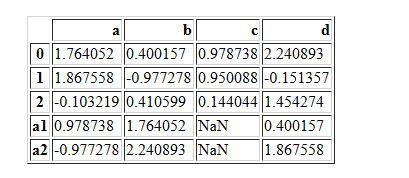
pd.concat([df1,df2],axis=0,join="outer")

df12=df1.append(df2)
df12

pd.concat([df1,df2],axis=0,join="inner")

当axis=1时
pd.concat([df1,df2],axis=1,join='inner')

pd.concat([df1,df1],axis=1,join='inner') #和outer一样
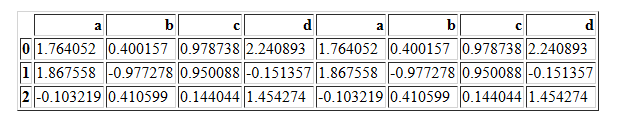
pd.concat([df1,df2],axis=1,join="outer")
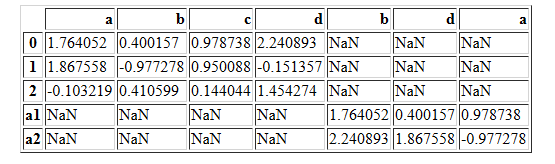
pd.concat([df1,df22],axis=1,join="inner")

pd.concat([df1,df22],axis=1,join="outer")

pd.concat([df1,df1],axis=1,join="outer")

Pandas中DataFrame数据合并、连接(concat、merge、join)之concat的更多相关文章
- Pandas中DataFrame数据合并、连接(concat、merge、join)之merge
二.merge:通过键拼接列 类似于关系型数据库的连接方式,可以根据一个或多个键将不同的DatFrame连接起来. 该函数的典型应用场景是,针对同一个主键存在两张不同字段的表,根据主键整合到一张表里面 ...
- Pandas中DataFrame数据合并、连接(concat、merge、join)之join
pandas.DataFrame.join 自己弄了很久,一看官网.感觉自己宛如智障.不要脸了,直接抄 DataFrame.join(other, on=None, how='left', lsuff ...
- 排序合并连接(sort merge join)的原理
排序合并连接(sort merge join)的原理 排序合并连接(sort merge join)的原理 排序合并连接(sort merge join) 访问次数:两张表都只会访 ...
- Python基础 | pandas中dataframe的整合与形变(merge & reshape)
目录 行的union pd.concat df.append 列的join pd.concat pd.merge df.join 行列转置 pivot stack & unstack melt ...
- Spark与Pandas中DataFrame对比
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- Spark与Pandas中DataFrame对比(详细)
Pandas Spark 工作方式 单机single machine tool,没有并行机制parallelism不支持Hadoop,处理大量数据有瓶颈 分布式并行计算框架,内建并行机制paral ...
- 将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy
将pandas的DataFrame数据写入MySQL数据库 + sqlalchemy import pandas as pd from sqlalchemy import create_engine ...
- Python3 Pandas的DataFrame数据的增、删、改、查
Python3 Pandas的DataFrame数据的增.删.改.查 一.DataFrame数据准备 增.删.改.查的方法有很多很多种,这里只展示出常用的几种. 参数inplace默认为False,只 ...
- Pandas中DataFrame修改列名
Pandas中DataFrame修改列名:使用 rename df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01- ...
随机推荐
- hdoj4812 D Tree(点分治)
题目链接:https://vjudge.net/problem/HDU-4812 题意:给定一颗带点权的树,求是否存在一条路经的上点的权值积取模后等于k,如果存在多组点对,输出字典序最小的. 思路: ...
- C# Excel 中设置文字对齐方式、方向和换行
在Excel表格中输入文字时,我们常常需要调整文字对齐方式或者对文字进行换行.本文将介绍如何通过编程的方式设置文字对齐方式,改变文字方向以及对文字进行换行. //创建Workbook对象 Workbo ...
- 小记--------sqoop的简单从mysql导入到hbase操作
sqoop import -D sqoop.hbase.add.row.key=true //是否将rowkey相关字段列入列族中,默认为false :该 ...
- mybatis-plus配置多数据源invalid bound statement (not found)
mybatis-plus配置多数据源invalid bound statement (not found) 错误原因 引入mybatis-plus应该使用的依赖如下,而不是mybatis <de ...
- 状压DP--Rotate Columns (hard version)-- Codeforces Round #584 - Dasha Code Championship - Elimination Round (rated, open for everyone, Div. 1 + Div. 2)
题意:https://codeforc.es/problemset/problem/1209/E2 给你一个n(1-12)行m(1-2000)列的矩阵,每一列都可以上下循环移动(类似密码锁). 问你移 ...
- Http 协议学习
借助[小坦克:HTTP 协议教程] 1.HTTP协议是什么 协议是计算机在通信过程中必须共同遵守的规则,我的理解是类似所有汽车在行驶过程中必须共同遵守的交通规则一样. http协议叫超文本协议,是一种 ...
- 【多重背包】Transport Ship
[来源] 2018年焦作网络赛 [参考博客] https://blog.csdn.net/baymax520/article/details/82719454 [题意] 有N种船只,每种船只的载货量为 ...
- 【sublime Text】sublime Text3安装可以使xml格式化的插件
应该有机会 ,会碰到需要格式化xml文件的情况. 例如,修改word转化的xml文件之后再将修改之后的xml文件转化为word文件. 但是,word另存的xml文件是没有格式的一片: 那怎么格式化 这 ...
- 在Windows平台上运行Tomcat
从之前的学习中知道,可以调用Bootstrap类将Toomcat作为一个独立的应用程序来运行,在Windows平台上,可以调用startup.bat批处理文件来启动Tomcat,或运行shutdown ...
- Winform 5种皮肤小结(内含丰富的下载实例)
软件界面就是指软件中面向操作者而专门设计的用于操作使用及反馈信息的指令部分. 优秀的软件界面有简便易用,突出重点,容错高等特点. 1.东日IrisSkin 使用IrisSkin只能是对单一的控件重绘 ...