Hadoop-No.15之Flume基于事件的数据收集和处理
Flume是一种分布式的可靠开源系统,用于流数据的高效收集,聚集和移动.Flume通常用于移动日志数据.但是也能移动大量事件数据.如社交媒体订阅,消息队列事件或者网络流量数据.
Flume架构
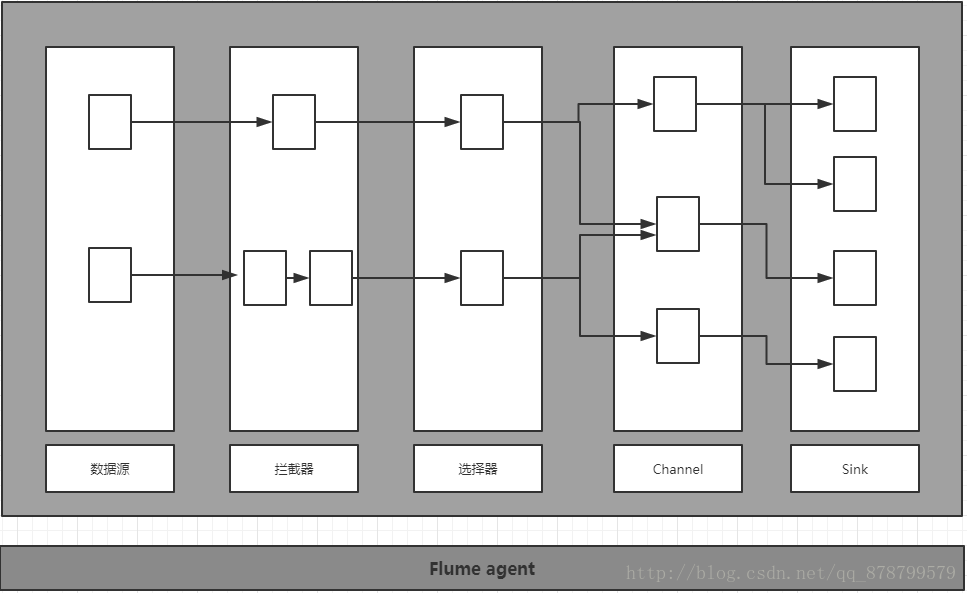
Flume的数据源使用来自外部数据源的时间,然后转发到Channel中.外部数据源可以是任何一个能够产生事件的系统.比如Twitter这样的社交媒体网站,机器日志,或者消息队列.实施Flume数据源的目的是使用来源于特定外部数据源的时间.很多数据源都能关于Flume一起使用.包括AvroSource,SpoolDirectorySource,HTTPSource与JMSSource.
Flume 拦截器能够拦截时间,并且能在传输过程中对事件做出修改 .Flume拦截器还能够转化时间,丰富时间或者实时Java类任何一种基本的操作.拦截器常用于格式化,分区,过滤,分片,验证,或者将源数据用于事件
选择器为事件提供了路径.用户能够使用选择器将时间发送到零至多个路径.正因为如此,如果需要分至多个Channel,或者需要基于事件发送到特定的Channel,那么选择器会非常有用.
Flume Channel存储事件,直到填满一个Sink.最常用的Channel为Memory Channel与File Channel. Memory Channel 将事件存储于内存.在Channel之重提供了最佳性能.但是如果处理或者主机操作失灵,将会丢失时间,导致可靠性降到最低.更为常用的磁盘Channel通过磁盘的持久存储提供更持久的事件存储.选择正确的Channel是一个很重要的构架决策,需要平衡性能与持久性.
Sink将事件从Channel中移除并传输到目的位置.目的位置可能是事件的最终目标系统.或者可以进一步进行Flume处理的位置.常用的Flume Sink是HDFS Sink.顾名思义,他会将事件写入HDFS文件中
Flume agent是这些组件的容器.承载着Flume数据源,Sink,Channel等JVM进程
Flume的特点
可靠性
事件会一直在Channel中存储,直到传输到下一个阶段
可恢复性
事件可以持久化到硬盘,然后在出现错误时回复
声明式
无需编码,配置会指定各组件的组合方式
高度定制化
尽管Flume包含大量的数据源,Sink以及框架外的组成,但它提供高度可插拔的框架,能按照用户的需求定制化的市县.
Hadoop-No.15之Flume基于事件的数据收集和处理的更多相关文章
- 从0到1搭建基于Kafka、Flume和Hive的海量数据分析系统(一)数据收集应用
大数据时代,一大技术特征是对海量数据采集.存储和分析的多组件解决方案.而其中对来自于传感器.APP的SDK和各类互联网应用的原生日志数据的采集存储则是基本中的基本.本系列文章将从0到1,概述一下搭建基 ...
- 如果数据需要被多个应用程序消费的话,推荐使用 Kafka,如果数据只是面向 Hadoop 的,可以使用 Flume
https://www.ibm.com/developerworks/cn/opensource/os-cn-kafka/index.html Kafka 与 Flume 很多功能确实是重复的.以下是 ...
- 基于事件的异步模式(EAP)
什么是EAP异步编程模式 EAP基于事件的异步模式是.net 2.0提出来的,实现了基于事件的异步模式的类将具有一个或者多个以Async为后缀的方法和对应的Completed事件,并且这些类都支持异步 ...
- 在Silverlight中的DispatcherTimer的Tick中使用基于事件的异步请求
需求:在silverlight用户界面上使用计时器定时刷新数据. 在 Silverlight 中的 DispatcherTimer 的 Tick 事件 中使用异步请求数据时,会出现多次请求的问题,以下 ...
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
Hadoop是2013年最热门的技术之一,通过北风网robby老师<深入浅出Hadoop实战开发>.<Hadoop应用开发实战>两套课程的学习,普通Java开发人员可以在最快的 ...
- Hadoop数据分析平台项目实战(基于CDH版本集群部署与安装)
1.Hadoop的主要应用场景: a.数据分析平台. b.推荐系统. c.业务系统的底层存储系统. d.业务监控系统. 2.开发环境:Linux集群(Centos64位)+Window开发模式(win ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop数据收集与入库系统Flume与Sqoop
Hadoop提供了一个中央化的存储系统,其有利于进行集中式的数据分析与数据共享. Hadoop对存储格式没有要求.可以存储用户访问日志.产品信息以及网页数据等数据. 常见的两种数据来源.一种是分散的数 ...
- .NET - 基于事件的异步模型
注:这是大概四年前写的文章了.而且我离开.net领域也有四年多了.本来不想再发表,但是这实际上是Active Object模式在.net中的一种重要实现方法,因此我把它掏出来发布一下.如果该模型有新的 ...
随机推荐
- 快速排序的Python代码实现
选择一个数,和它后面的数比较,把比它小的放在它的左边,大的在右边(位置可能会因为左边元素的添加而右移) def quick_sort(arr): if arr==[]: return[] else: ...
- [HAOI2010]软件安装 题解
题面 这道题比较显然地,是一道树形背包: 但是会有环,怎么办呢? 缩点!tarjan缩点! 然后在新图上跑树形背包就可以AC了 #include <bits/stdc++.h> #defi ...
- 输出单项链表中倒数第k个结点——牛客刷题
题目描述: 输入一个单向链表,输出该链表中倒数第k个结点 输入.输出描述: 输入说明:1.链表结点个数 2.链表结点的值3.输入k的值 输出说明:第k个结点指针 题目分析: 假设链表长度为n,倒数第k ...
- Codeforces 1237B. Balanced Tunnel
传送门 这一题有点意思 首先预处理出 $pos[x]$ 表示编号 $x$ 的车是第几个出隧道的 然后按进入隧道的顺序枚举每辆车 $x$ 考虑有哪些车比 $x$ 晚进入隧道却比 $x$ 早出隧道 显然是 ...
- ajax-springMVC提交表单的方式
1.request参数提交(Form提交),适用于GET/POST request参数传递都会转换成 id=123&fileName=test.name&type=culture_ar ...
- WebClient小结
webclient功能有限,特别是不能使用身份验证证书,这样,上传数据时候问题出现,现在许多站点都不会接受没有身份验证的上传文件.尽管可以给请求添加标题信息并检查相应中的标题信息,但这仅限于一般意义的 ...
- RAII惯用法:C++资源管理的利器(转)
RAII惯用法:C++资源管理的利器 RAII是指C++语言中的一个惯用法(idiom),它是“Resource Acquisition Is Initialization”的首字母缩写.中文可将其翻 ...
- [git] Updates were rejected because the tip of your current branch is behind its remote counterpart.
场景 $ git push To https://github.com/XXX/XXX ! [rejected] dev -> dev (non-fast-forward) error: fai ...
- Java并发编程——线程的基本概念和创建
一.线程的基本概念: 1.什么是进程.什么是是线程.多线程? 进程:一个正在运行的程序(程序进入内存运行就变成了一个进程).比如QQ程序就是一个进程. 线程:线程是进程中的一个执行单元,负责当前进程中 ...
- javascript是否像php一样有isset和empty?
javascript是否像php一样有isset和empty? is set()在php中用于检测是否设置了变量木浴桶,函数返回布尔值true/false.在javascript中,您可以用替换它!( ...