Hadoop-No.15之Flume基于事件的数据收集和处理
Flume是一种分布式的可靠开源系统,用于流数据的高效收集,聚集和移动.Flume通常用于移动日志数据.但是也能移动大量事件数据.如社交媒体订阅,消息队列事件或者网络流量数据.
Flume架构
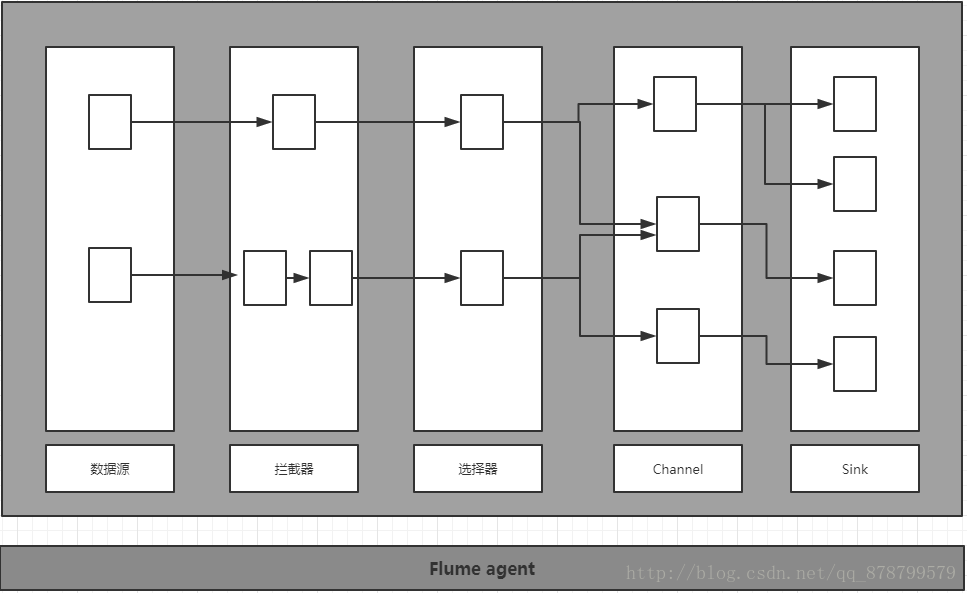
Flume的数据源使用来自外部数据源的时间,然后转发到Channel中.外部数据源可以是任何一个能够产生事件的系统.比如Twitter这样的社交媒体网站,机器日志,或者消息队列.实施Flume数据源的目的是使用来源于特定外部数据源的时间.很多数据源都能关于Flume一起使用.包括AvroSource,SpoolDirectorySource,HTTPSource与JMSSource.
Flume 拦截器能够拦截时间,并且能在传输过程中对事件做出修改 .Flume拦截器还能够转化时间,丰富时间或者实时Java类任何一种基本的操作.拦截器常用于格式化,分区,过滤,分片,验证,或者将源数据用于事件
选择器为事件提供了路径.用户能够使用选择器将时间发送到零至多个路径.正因为如此,如果需要分至多个Channel,或者需要基于事件发送到特定的Channel,那么选择器会非常有用.
Flume Channel存储事件,直到填满一个Sink.最常用的Channel为Memory Channel与File Channel. Memory Channel 将事件存储于内存.在Channel之重提供了最佳性能.但是如果处理或者主机操作失灵,将会丢失时间,导致可靠性降到最低.更为常用的磁盘Channel通过磁盘的持久存储提供更持久的事件存储.选择正确的Channel是一个很重要的构架决策,需要平衡性能与持久性.
Sink将事件从Channel中移除并传输到目的位置.目的位置可能是事件的最终目标系统.或者可以进一步进行Flume处理的位置.常用的Flume Sink是HDFS Sink.顾名思义,他会将事件写入HDFS文件中
Flume agent是这些组件的容器.承载着Flume数据源,Sink,Channel等JVM进程
Flume的特点
可靠性
事件会一直在Channel中存储,直到传输到下一个阶段
可恢复性
事件可以持久化到硬盘,然后在出现错误时回复
声明式
无需编码,配置会指定各组件的组合方式
高度定制化
尽管Flume包含大量的数据源,Sink以及框架外的组成,但它提供高度可插拔的框架,能按照用户的需求定制化的市县.
Hadoop-No.15之Flume基于事件的数据收集和处理的更多相关文章
- 从0到1搭建基于Kafka、Flume和Hive的海量数据分析系统(一)数据收集应用
大数据时代,一大技术特征是对海量数据采集.存储和分析的多组件解决方案.而其中对来自于传感器.APP的SDK和各类互联网应用的原生日志数据的采集存储则是基本中的基本.本系列文章将从0到1,概述一下搭建基 ...
- 如果数据需要被多个应用程序消费的话,推荐使用 Kafka,如果数据只是面向 Hadoop 的,可以使用 Flume
https://www.ibm.com/developerworks/cn/opensource/os-cn-kafka/index.html Kafka 与 Flume 很多功能确实是重复的.以下是 ...
- 基于事件的异步模式(EAP)
什么是EAP异步编程模式 EAP基于事件的异步模式是.net 2.0提出来的,实现了基于事件的异步模式的类将具有一个或者多个以Async为后缀的方法和对应的Completed事件,并且这些类都支持异步 ...
- 在Silverlight中的DispatcherTimer的Tick中使用基于事件的异步请求
需求:在silverlight用户界面上使用计时器定时刷新数据. 在 Silverlight 中的 DispatcherTimer 的 Tick 事件 中使用异步请求数据时,会出现多次请求的问题,以下 ...
- Hadoop应用开发实战(flume应用开发、搜索引擎算法、Pipes、集群、PageRank算法)
Hadoop是2013年最热门的技术之一,通过北风网robby老师<深入浅出Hadoop实战开发>.<Hadoop应用开发实战>两套课程的学习,普通Java开发人员可以在最快的 ...
- Hadoop数据分析平台项目实战(基于CDH版本集群部署与安装)
1.Hadoop的主要应用场景: a.数据分析平台. b.推荐系统. c.业务系统的底层存储系统. d.业务监控系统. 2.开发环境:Linux集群(Centos64位)+Window开发模式(win ...
- Hadoop 系列(八)—— 基于 ZooKeeper 搭建 Hadoop 高可用集群
一.高可用简介 Hadoop 高可用 (High Availability) 分为 HDFS 高可用和 YARN 高可用,两者的实现基本类似,但 HDFS NameNode 对数据存储及其一致性的要求 ...
- Hadoop数据收集与入库系统Flume与Sqoop
Hadoop提供了一个中央化的存储系统,其有利于进行集中式的数据分析与数据共享. Hadoop对存储格式没有要求.可以存储用户访问日志.产品信息以及网页数据等数据. 常见的两种数据来源.一种是分散的数 ...
- .NET - 基于事件的异步模型
注:这是大概四年前写的文章了.而且我离开.net领域也有四年多了.本来不想再发表,但是这实际上是Active Object模式在.net中的一种重要实现方法,因此我把它掏出来发布一下.如果该模型有新的 ...
随机推荐
- Node原生demo
1.=>创建配置模块,作用是先判断是开发环境还是生产环境,并将开发或生产环境的数据库信息和http信息分别筛开,便于选择 2.=>创建数据库模块,作用是连接数据库 3.=>创建路由模 ...
- SGI STL源码stl_bvector.h分析
前言 上篇文章讲了 STL vector 泛化版本的实现,其采用普通指针作为迭代器,可以接受任何类型的元素.但如果用来存储 bool 类型的数据,可以实现功能,但每一个 bool 占一个字节(byte ...
- (5.3.2)数据库迁移——SSIS包批量导出
SSIS连接出错 原因 : ssms 工具 不是 admin 权限 打开的 SSIS包批量导出代码 use msdb go IF OBJECT_ID('msdb.dbo.usp_ExportS ...
- 使用Minikube运行一个本地单节点Kubernetes集群(阿里云)
使用Minikube运行一个本地单节点Kubernetes集群中使用谷歌官方镜像由于某些原因导致镜像拉取失败以及很多人并没有代理无法开展相关实验. 因此本文使用阿里云提供的修改版Minikube创建一 ...
- GukiZ and Binary Operations CodeForces - 551D (组合计数)
大意: 给定$n,k,l,m$, 求有多少个长度为$n$, 元素全部严格小于$2^l$, 且满足 的序列. 刚开始想着暴力枚举当前or和上一个数二进制中$1$的分布, 但这样状态数是$O(64^3)$ ...
- 如何配置数据库镜像<一>
一.简介 “数据库镜像”是Sql Server 2005推出的一个主要用于提高数据库可用率的软件解决方案.镜像是基于每个数据库执行的,仅适用于使用完整恢复模式的数据库.简单恢复模式和大容量日志恢复模式 ...
- centos中mariadb的相关操作
Tip 1 在使用mariadb中启动服务报错 : Failed to start mariadb.service: Unit not found. 解决办法: yum install -y mari ...
- Editplus code
网上一大堆,垃圾也是一大堆,保留一个真正的,提高效率 原文链接:https://blog.csdn.net/anhldd/article/details/85088715 Vovan 3AG46-JJ ...
- Java高并发程序设计学习笔记(三):Java内存模型和线程安全
转自:https://blog.csdn.net/dataiyangu/article/details/86412704 原子性有序性可见性– 编译器优化– 硬件优化(如写吸收,批操作)Java虚拟机 ...
- latex中文环境配置(针对北大模板,开题报告+中期答辩+毕业论文)
最近自己在忙着开题,中文环境真的是emm 以下只针对北大的毕业论文模板,至于其他的中文环境没有尝试 主要是用不同的latex编辑器会报不同的错误,当然我最后还是统一成了pdflatex,经过无数次尝试 ...