deep_learning_Activate_method
常见的激活函数有sigmoid、tanh和relu三种非线性函数,其数学表达式分别为:
- sigmoid: y = 1/(1 + e-x)
- tanh: y = (ex - e-x)/(ex + e-x)
- relu: y = max(0, x)
其代码实现如下:

import numpy as np
import matplotlib.pyplot as plt def sigmoid(x):
return 1 / (1 + np.exp(-x)) def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x)) def relu(x):
return np.maximum(0, x) x = np.arange(-5, 5, 0.1)
p1 = plt.subplot(311)
y = tanh(x)
p1.plot(x, y)
p1.set_title('tanh')
p1.axhline(ls='--', color='r')
p1.axvline(ls='--', color='r') p2 = plt.subplot(312)
y = sigmoid(x)
p2.plot(x, y)
p2.set_title('sigmoid')
p2.axhline(0.5, ls='--', color='r')
p2.axvline(ls='--', color='r') p3 = plt.subplot(313)
y = relu(x)
p3.plot(x, y)
p3.set_title('relu')
p3.axvline(ls='--', color='r') plt.subplots_adjust(hspace=1)
plt.show()
其图形解释如下:
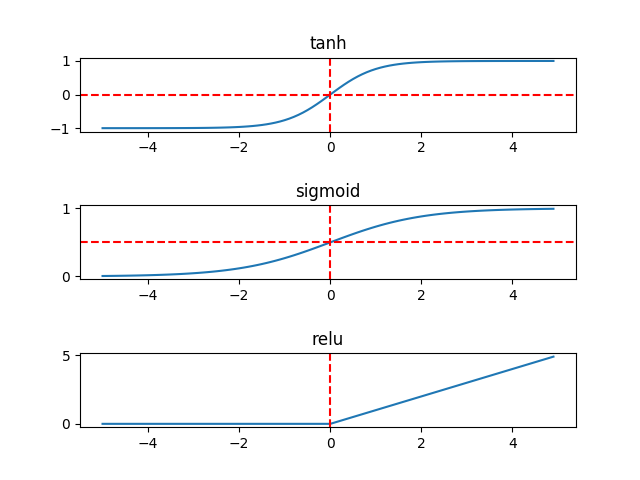
相较而言,在隐藏层,tanh函数要优于sigmoid函数,可以认为是sigmoid的平移版本,优势在于其取值范围介于-1 ~ 1之间,数据的平均值为0,而不像sigmoid为0.5,有类似数据中心化的效果。
但在输出层,sigmoid也许会优于tanh函数,原因在于你希望输出结果的概率落在0 ~ 1 之间,比如二元分类,sigmoid可作为输出层的激活函数。
但实际应用中,特别是深层网络在训练时,tanh和sigmoid会在端值趋于饱和,造成训练速度减慢,故深层网络的激活函数默认大多采用relu函数,浅层网络可以采用sigmoid和tanh函数。
另外有必要了解激活函数的求导公式,在反向传播中才知道是如何进行梯度下降。三个函数的求导结果及推理过程如下:
1. sigmoid求导函数:
其中,sigmoid函数定义为 y = 1/(1 + e-x) = (1 + e-x)-1
与此相关的基础求导公式:(xn)' = n * xn-1 和 (ex)' = ex
应用链式法则,其求导过程为:dy/dx = -1 * (1 + e-x)-2 * e-x * (-1)
= e-x * (1 + e-x)-2
= (1 + e-x - 1) / (1 + e-x)2
= (1 + e-x)-1 - (1 + e-x)-2
= y - y2
= y(1 -y)
2. tanh求导函数:
其中,tanh函数定义为 y = (ex - e-x)/(ex + e-x)
与此相关的基础求导公式:(u/v)' = (u' v - uv') / v2
同样应用链式法则,其求导过程为:dy/dx = ( (ex - e-x)' * (ex + e-x) - (ex - e-x) * (ex + e-x)' ) / (ex + e-x)2
= ( (ex - (-1) * e-x) * (ex + e-x) - (ex - e-x) * (ex + (-1) * e-x) ) / (ex + e-x)2
= ( (ex + e-x)2 - (ex - e-x)2 ) / (ex + e-x)2
= 1 - ( (ex - e-x)/(ex + e-x) )2
= 1 - y2
3. relu求导函数:
其中,relu函数定义为 y = max(0, x)
可以简单推理出 当x <0 时,dy/dx = 0; 当 x >= 0时,dy/dx = 1
转自:https://www.cnblogs.com/hutao722/p/9732223.html
deep_learning_Activate_method的更多相关文章
随机推荐
- [Python]最长公共子序列 VS 最长公共子串[动态规划]
前言 由于原微软开源的基于古老的perl语言的Rouge依赖环境实在难以搭建,遂跟着Rouge论文的描述自行实现. Rouge存在N.L.S.W.SU等几大子评估指标.在复现Rouge-L的函数时,便 ...
- Android 单元测试学习计划
网上查了一下Android单元测试相关的知识点,总结了一个学习步骤: 1. 什么是单元测试2. 单元测试正反面: 2.1. 重要性 2.2. 缺陷 2.3. 策略3. 单元测试的基础知识: 3.1. ...
- Product - 产品经理 - 内容
特别说明 本文是已读书籍的学习笔记和内容摘要,原文内容有少部分改动,并添加一些相关信息,但总体不影响原文表达. - ISBN: 9787568041591 - https://book.douban. ...
- sql内联注入
测试字符串 变 种 预 期 结 果 ' 触发错误.如果成功,数据库将返回一个错误 1' or '1'='1 1') or ('1'='1 永真条件.如果成功,将返回表中所有的行 value' o ...
- 【DSP开发】DSP程序优化
此文是在http://blog.csdn.net/guanchanghui/article/details/1181851基础上,通过自己的学习理解修改而来.暂且算作是自己的原创吧.如有侵权,联系,立 ...
- linux下nginx的学习
安装参考菜鸟教程:https://www.runoob.com/linux/nginx-install-setup.html nginx文档官网: http://nginx.org nginx社区:h ...
- IDEA安装Git
1.下载Git 官方地址为:https://git-scm.com/download/win 2.下载完之后,双击安装 3.选择安装目录 4.选择组件 5.开始菜单目录名设置 6.选择使用命令行环境 ...
- gdb移植(设备端本地版本)
Gdb下载地址:http://ftp.gnu.org/gnu/gdb/ ncurse下载地址:http://ftp.gnu.org/pub/gnu/ncurses/ 目录结构如下: ├── insta ...
- echart4数据管理组件dataset学习
背景 如果后台数据固定,如何动态定制其前端数据展示方式呢?也就是说同一种数据,如何被多个前端Echarts图表复用呢?最近在研究一种数据展示可配置化的功能,然后发现了echart4.0的dataset ...
- k8s-高可用架构设计
docker的私有仓库harbor.容器化kubernetes部分组建.使用阿里云日志服务收集日志. 部署完成后,你将理解系统各组件的交互原理,进而能快速解决实际问题,所以本文档主要适合于那些有一定k ...