deep_learning_Activate_method
常见的激活函数有sigmoid、tanh和relu三种非线性函数,其数学表达式分别为:
- sigmoid: y = 1/(1 + e-x)
- tanh: y = (ex - e-x)/(ex + e-x)
- relu: y = max(0, x)
其代码实现如下:

import numpy as np
import matplotlib.pyplot as plt def sigmoid(x):
return 1 / (1 + np.exp(-x)) def tanh(x):
return (np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x)) def relu(x):
return np.maximum(0, x) x = np.arange(-5, 5, 0.1)
p1 = plt.subplot(311)
y = tanh(x)
p1.plot(x, y)
p1.set_title('tanh')
p1.axhline(ls='--', color='r')
p1.axvline(ls='--', color='r') p2 = plt.subplot(312)
y = sigmoid(x)
p2.plot(x, y)
p2.set_title('sigmoid')
p2.axhline(0.5, ls='--', color='r')
p2.axvline(ls='--', color='r') p3 = plt.subplot(313)
y = relu(x)
p3.plot(x, y)
p3.set_title('relu')
p3.axvline(ls='--', color='r') plt.subplots_adjust(hspace=1)
plt.show()
其图形解释如下:
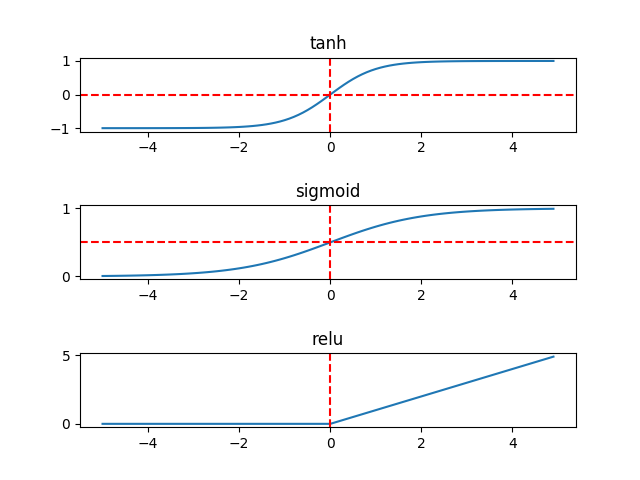
相较而言,在隐藏层,tanh函数要优于sigmoid函数,可以认为是sigmoid的平移版本,优势在于其取值范围介于-1 ~ 1之间,数据的平均值为0,而不像sigmoid为0.5,有类似数据中心化的效果。
但在输出层,sigmoid也许会优于tanh函数,原因在于你希望输出结果的概率落在0 ~ 1 之间,比如二元分类,sigmoid可作为输出层的激活函数。
但实际应用中,特别是深层网络在训练时,tanh和sigmoid会在端值趋于饱和,造成训练速度减慢,故深层网络的激活函数默认大多采用relu函数,浅层网络可以采用sigmoid和tanh函数。
另外有必要了解激活函数的求导公式,在反向传播中才知道是如何进行梯度下降。三个函数的求导结果及推理过程如下:
1. sigmoid求导函数:
其中,sigmoid函数定义为 y = 1/(1 + e-x) = (1 + e-x)-1
与此相关的基础求导公式:(xn)' = n * xn-1 和 (ex)' = ex
应用链式法则,其求导过程为:dy/dx = -1 * (1 + e-x)-2 * e-x * (-1)
= e-x * (1 + e-x)-2
= (1 + e-x - 1) / (1 + e-x)2
= (1 + e-x)-1 - (1 + e-x)-2
= y - y2
= y(1 -y)
2. tanh求导函数:
其中,tanh函数定义为 y = (ex - e-x)/(ex + e-x)
与此相关的基础求导公式:(u/v)' = (u' v - uv') / v2
同样应用链式法则,其求导过程为:dy/dx = ( (ex - e-x)' * (ex + e-x) - (ex - e-x) * (ex + e-x)' ) / (ex + e-x)2
= ( (ex - (-1) * e-x) * (ex + e-x) - (ex - e-x) * (ex + (-1) * e-x) ) / (ex + e-x)2
= ( (ex + e-x)2 - (ex - e-x)2 ) / (ex + e-x)2
= 1 - ( (ex - e-x)/(ex + e-x) )2
= 1 - y2
3. relu求导函数:
其中,relu函数定义为 y = max(0, x)
可以简单推理出 当x <0 时,dy/dx = 0; 当 x >= 0时,dy/dx = 1
转自:https://www.cnblogs.com/hutao722/p/9732223.html
deep_learning_Activate_method的更多相关文章
随机推荐
- SaCa DataQuality概述
1.1 产品特性 UniEAP DataQuality(以下简称DataQuality)是UniEAP最新推出的数据质量管理平台.基于数据监控服务.数据质量校验引擎.数据清洗引擎以及面向服务数据质量架 ...
- epoll 数据库安装以及相关概念
epoll select 只能同时处理1024个客户端, 多线程会遇到资源瓶颈,什么才是解决高并发最有效的方式呢 linux中提供了epoll 这种多路复用的IO模型,注意其他平台没有相应的实现 所以 ...
- 无监督异常检测之卷积AE和卷积VAE
尝试用卷积AE和卷积VAE做无监督检测,思路如下: 1.先用正常样本训练AE或VAE 2.输入测试集给AE或VAE,获得重构的测试集数据. 3.计算重构的数据和原始数据的误差,如果误差大于某一个阈值, ...
- Leetcode之动态规划(DP)专题-746. 使用最小花费爬楼梯(Min Cost Climbing Stairs)
Leetcode之动态规划(DP)专题-746. 使用最小花费爬楼梯(Min Cost Climbing Stairs) 数组的每个索引做为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 cost ...
- 【VS开发】ConvertBSTRToString(filename) 不能将string转换为BSTR
环境:win7,x64,vs2008 sp1 把VC 6.0的工程文件用VS2008打开,编译报错: error C2664:"_com_util::ConvertBSTRToString& ...
- python urllib2 实现大文件下载
使用urllib2下载并分块copy: # from urllib2 import urlopen # Python 2 from urllib.request import urlopen # Py ...
- char、varchar、nchar、nvarchar四种类型
char,nchar是定长,如果没达到指定的长度时将自动以英文空格在其后面填充.优势在于速度较高.varchar,nvarchar属于变长,如果没有达到指定的长度时,不会将自动以英文空格在其后面填充. ...
- Flash中的SLC/MLC/MLC--基础
参考 1.http://www.upantool.com/jiaocheng/qita/2012/slc_mlc_tlc.html 2.http://www.2ic.cn/html/10/t-4324 ...
- vi操作笔记一
vi命令 gg 到首行 shift + 4 跳到该行最后一个字符 shift + 6 跳到该行首个字符 shift + g 到尾行 vi 可视 G 全选 = 程序对齐 gg 到首行 vi 可视 ...
- arm-linux-ar常见用法
1) 创建test.a静态库 arm-linux-gcc -c a.o a.c arm-linux-gcc -c b.o b.c arm-linux-ar -rc test.a ...