配置BeautifulSoup4+lxml+html5lib
序

Windows平台 + Python3.5
安装BeautifulSoup4

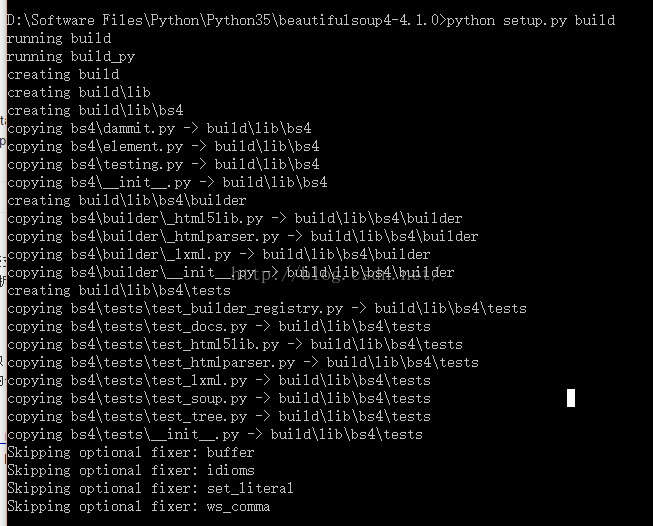
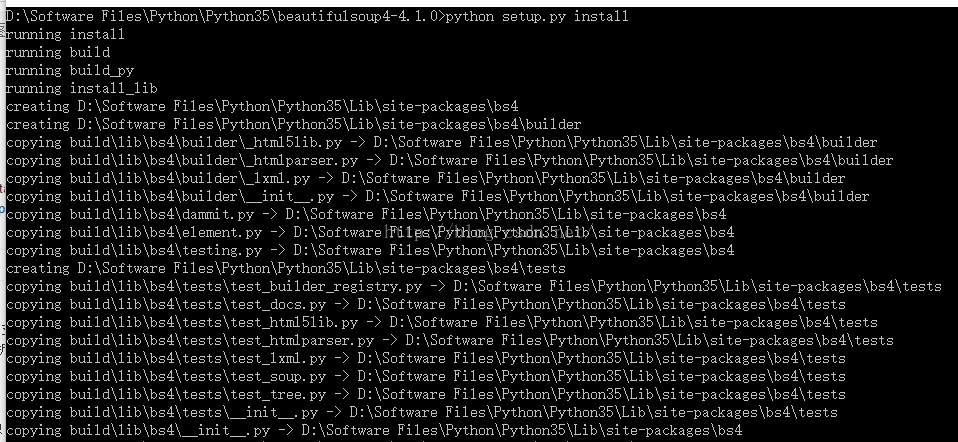
安装html5lib
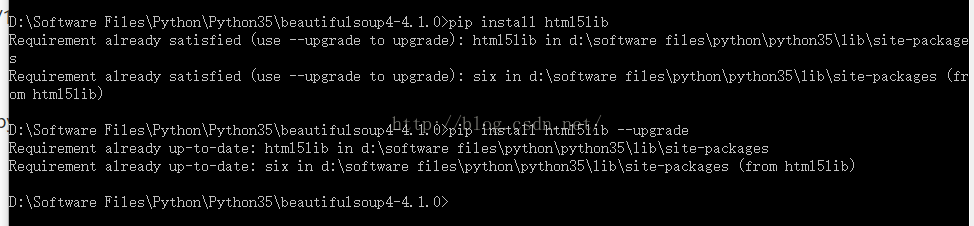
安装lxml
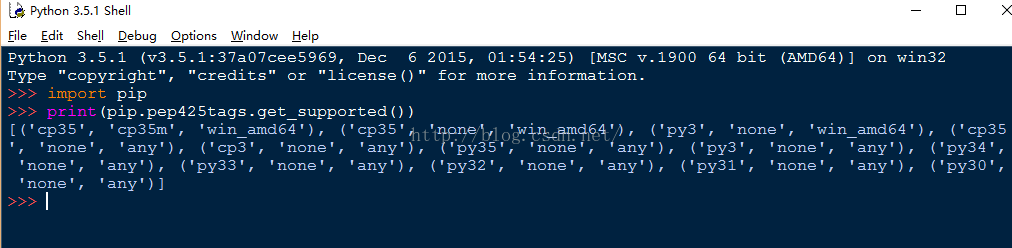
Lxml, a binding for the libxml2 and libxslt libraries.
lxml‑3.4.4‑cp27‑none‑win32.whl
lxml‑3.4.4‑cp27‑none‑win_amd64.whl
lxml‑3.4.4‑cp33‑none‑win32.whl
lxml‑3.4.4‑cp33‑none‑win_amd64.whl
lxml‑3.4.4‑cp34‑none‑win32.whl
lxml‑3.4.4‑cp34‑none‑win_amd64.whl
lxml‑3.4.4‑cp35‑none‑win32.whl
lxml‑3.4.4‑cp35‑none‑win_amd64.whl
cp后面是Python的版本号,27表示2.7,根据你的Python版本选择下载。
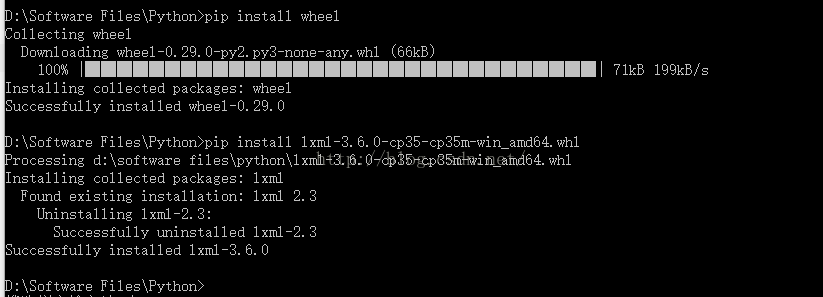
- pip install BeautifulSoup4 或 easy_install BeautifulSoup4
- pip install html5lib
- pip install lxml
使用BeautifulSoup
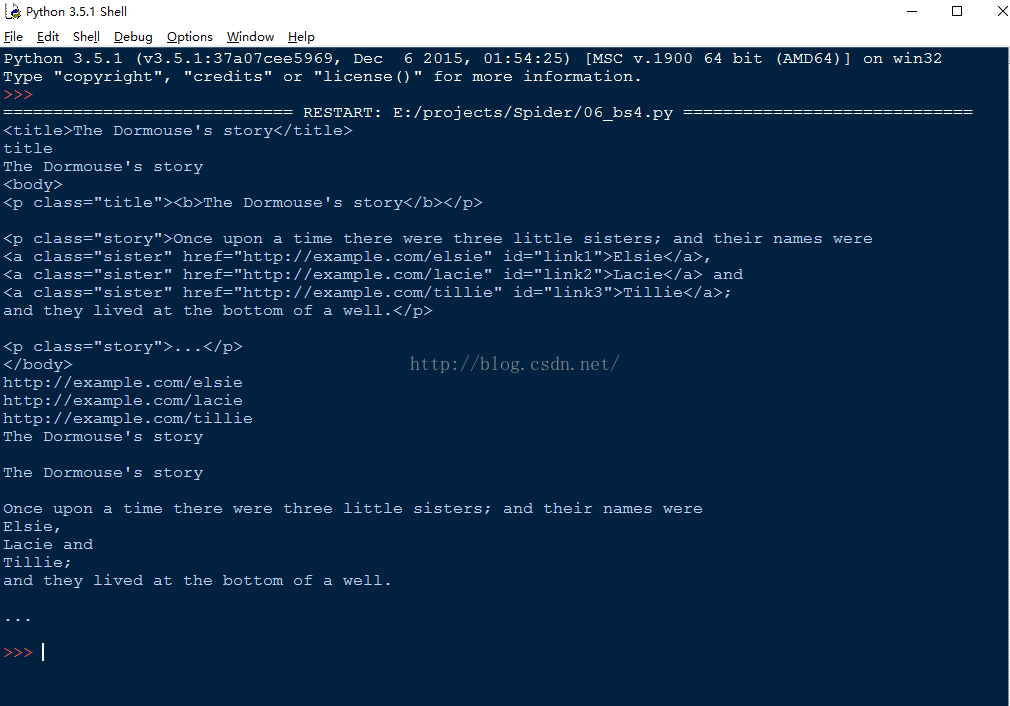
- html = """
- <html><head><title>The Dormouse's story</title></head>
- <body>
- <p class="title"><b>The Dormouse's story</b></p>
- <p class="story">Once upon a time there were three little sisters; and their names were
- <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
- <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
- <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
- and they lived at the bottom of a well.</p>
- <p class="story">...</p>
- """
- from bs4 import BeautifulSoup
- #添加一个解析器
- soup = BeautifulSoup(html,'html5lib')
- print(soup.title)
- print(soup.title.name)
- print(soup.title.text)
- print(soup.body)
- #从文档中找到所有<a>标签的内容
- for link in soup.find_all('a'):
- print(link.get('href'))
- #从文档中找到所有文字内容
- print(soup.get_text())
注意:
配置BeautifulSoup4+lxml+html5lib的更多相关文章
- Python爬虫beautifulsoup4常用的解析方法总结
摘要 如何用beautifulsoup4解析各种情况的网页 beautifulsoup4的使用 关于beautifulsoup4,官网已经讲的很详细了,我这里就把一些常用的解析方法做个总结,方便查阅. ...
- Python爬虫beautifulsoup4常用的解析方法总结(新手必看)
今天小编就为大家分享一篇关于Python爬虫beautifulsoup4常用的解析方法总结,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧摘要 如何用beau ...
- 爬虫基础以及 re,BeatifulSoup,requests模块使用
爬虫基础以及BeatifulSoup模块使用 爬虫的定义:向网站发起请求,获取资源后分析并提取有用数据的程序 爬虫的流程 发送请求 ---> request 获取响应内容 ---> res ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- 转:Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
- 【bs4】安装beautifulsoup
Debian/Ubuntu,install $ apt-get install python-bs4 easy_install/pip $ easy_install beautifulsoup4 $ ...
- requests和BeautifulSoup
一:Requests库 Requests is an elegant and simple HTTP library for Python, built for human beings. 1.安装 ...
随机推荐
- java的输入流中的两个坑
1.输入流的所有实例中的read()方法皆是阻塞的. 输入流只会在发生错误或者异常关闭的时候回返回-1,如果流中没有数据,不会返回-1而是一直阻塞. 2.BufferedReader的readLine ...
- Json:Restful
JArray & JObject JArray与JObject在json的应用:无需定义相应的类对象,直接解析 JArray jarr = JArray.Parse(jsonStr); //数 ...
- 运输层8——TCP运输连接管理
目录 1. TCP的连接建立 2. TCP的连接释放 写在前面:本文章是针对<计算机网络第七版>的学习笔记 运输层1--运输层协议概述 运输层2--用户数据报协议UDP 运输层3--传输控 ...
- Redis未授权访问漏洞复现及修复方案
首先,第一个复现Redis未授权访问这个漏洞是有原因的,在 2019-07-24 的某一天,我同学的服务器突然特别卡,卡到连不上的那种,通过 top,free,netstat 等命令查看后发现,CPU ...
- Mybatis-Plus 插件学习
官方指南 1.逻辑删除 在相应字段上添加注解 @TableLogic private Integer deleted; 说明: 使用mp自带方法删除和查找都会附带逻辑删除功能 (自己写的xml不会) ...
- Git报错:Your branch is up to date with 'origin/master'.
Git在提交的时候报错 Your branch is up to date with 'origin/master'. 报错 Your branch is up to date with 'origi ...
- bzoj3097 hash killer 1——构造题
题意 在 $u64$ 自然溢出下,请输出一串字符串和 $L$,使得对任意 $Base$ 都能找到两个长度为 $L$ 的字串的 $Hash$ 值相同. 分析 $u64$ 自然溢出等价于两个哈希值模 $2 ...
- sql server replace 的使用方法
Sql Server REPLACE函数的使用 REPLACE用第三个表达式替换第一个字符串表达式中出现的所有第二个给定字符串表达式. 语法REPLACE ( ''string_replace1' ...
- Shared Nothing、Shared Everthting、Shared Disk
数据库构架设计中主要有Shared Everthting.Shared Nothing.和Shared Disk:1.Shared Everything:一般是针对单个主机,完全透明共享CPU/MEM ...
- 使用webuploader实现大文件断点续传
IE的自带下载功能中没有断点续传功能,要实现断点续传功能,需要用到HTTP协议中鲜为人知的几个响应头和请求头. 一. 两个必要响应头Accept-Ranges.ETag 客户端每次提交下载请求时,服务 ...