配置BeautifulSoup4+lxml+html5lib
序

Windows平台 + Python3.5
安装BeautifulSoup4

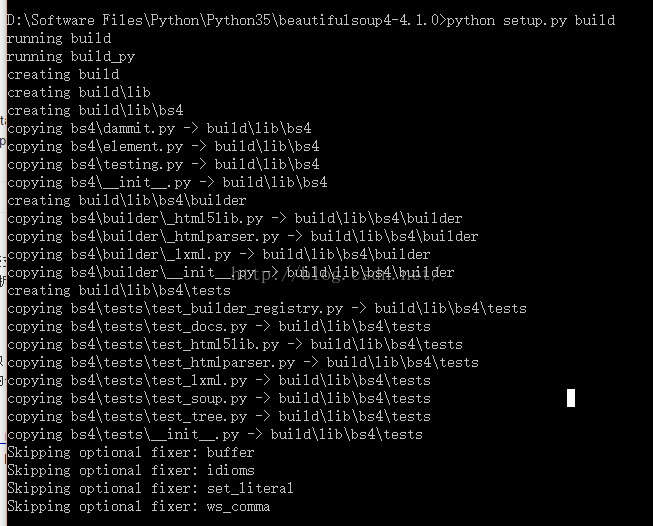
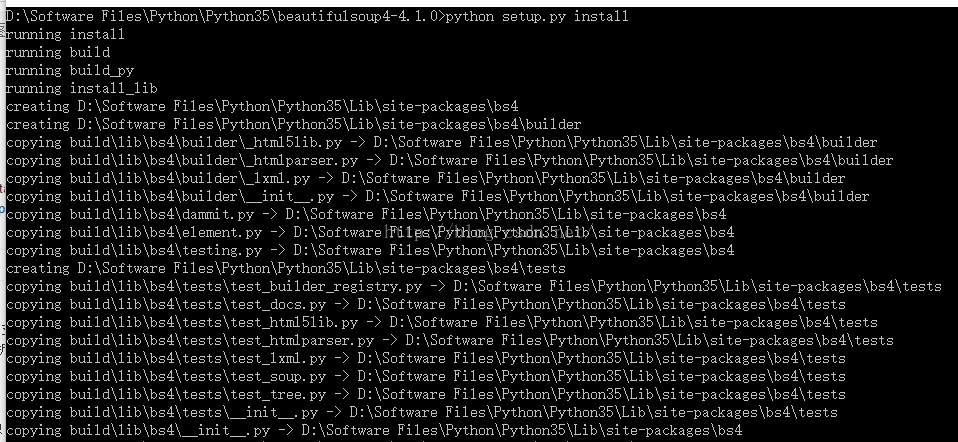
安装html5lib
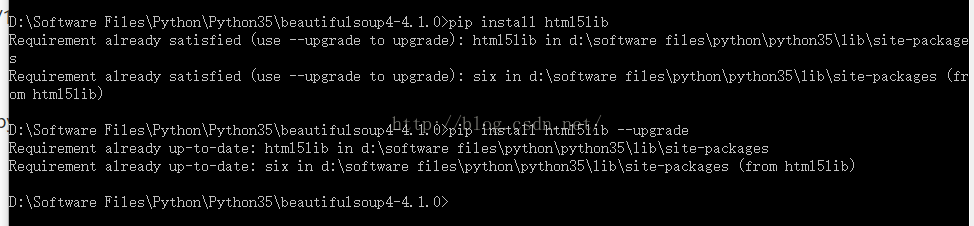
安装lxml
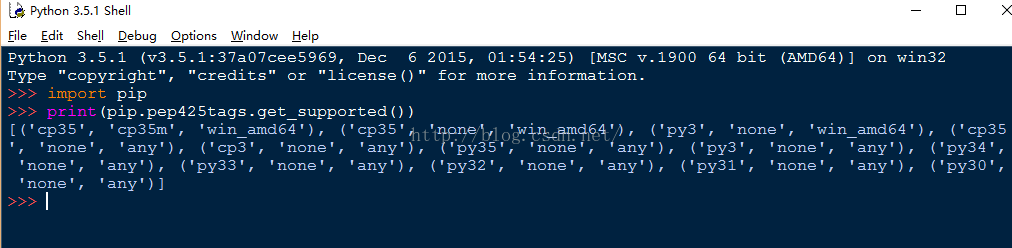
Lxml, a binding for the libxml2 and libxslt libraries.
lxml‑3.4.4‑cp27‑none‑win32.whl
lxml‑3.4.4‑cp27‑none‑win_amd64.whl
lxml‑3.4.4‑cp33‑none‑win32.whl
lxml‑3.4.4‑cp33‑none‑win_amd64.whl
lxml‑3.4.4‑cp34‑none‑win32.whl
lxml‑3.4.4‑cp34‑none‑win_amd64.whl
lxml‑3.4.4‑cp35‑none‑win32.whl
lxml‑3.4.4‑cp35‑none‑win_amd64.whl
cp后面是Python的版本号,27表示2.7,根据你的Python版本选择下载。
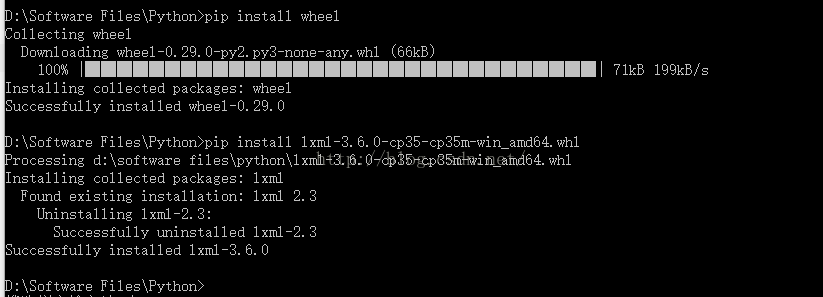
- pip install BeautifulSoup4 或 easy_install BeautifulSoup4
- pip install html5lib
- pip install lxml
使用BeautifulSoup
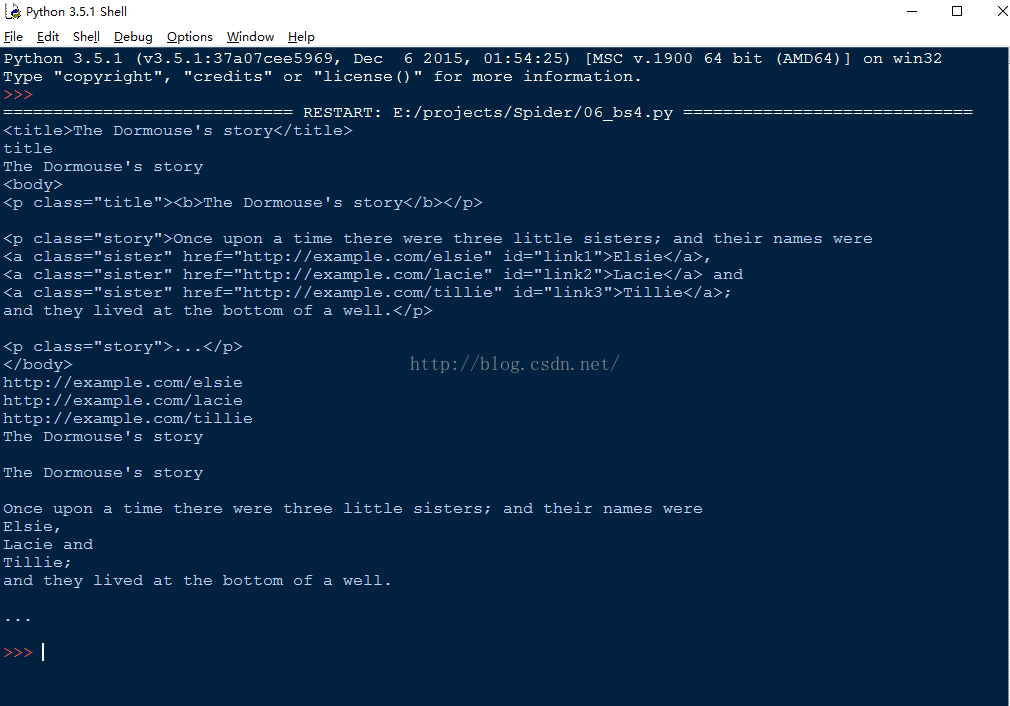
- html = """
- <html><head><title>The Dormouse's story</title></head>
- <body>
- <p class="title"><b>The Dormouse's story</b></p>
- <p class="story">Once upon a time there were three little sisters; and their names were
- <a href="http://example.com/elsie" class="sister" id="link1">Elsie</a>,
- <a href="http://example.com/lacie" class="sister" id="link2">Lacie</a> and
- <a href="http://example.com/tillie" class="sister" id="link3">Tillie</a>;
- and they lived at the bottom of a well.</p>
- <p class="story">...</p>
- """
- from bs4 import BeautifulSoup
- #添加一个解析器
- soup = BeautifulSoup(html,'html5lib')
- print(soup.title)
- print(soup.title.name)
- print(soup.title.text)
- print(soup.body)
- #从文档中找到所有<a>标签的内容
- for link in soup.find_all('a'):
- print(link.get('href'))
- #从文档中找到所有文字内容
- print(soup.get_text())
注意:
配置BeautifulSoup4+lxml+html5lib的更多相关文章
- Python爬虫beautifulsoup4常用的解析方法总结
摘要 如何用beautifulsoup4解析各种情况的网页 beautifulsoup4的使用 关于beautifulsoup4,官网已经讲的很详细了,我这里就把一些常用的解析方法做个总结,方便查阅. ...
- Python爬虫beautifulsoup4常用的解析方法总结(新手必看)
今天小编就为大家分享一篇关于Python爬虫beautifulsoup4常用的解析方法总结,小编觉得内容挺不错的,现在分享给大家,具有很好的参考价值,需要的朋友一起跟随小编来看看吧摘要 如何用beau ...
- 爬虫基础以及 re,BeatifulSoup,requests模块使用
爬虫基础以及BeatifulSoup模块使用 爬虫的定义:向网站发起请求,获取资源后分析并提取有用数据的程序 爬虫的流程 发送请求 ---> request 获取响应内容 ---> res ...
- 【学习笔记】PYTHON网络爬虫与信息提取(北理工 嵩天)
学习目的:掌握定向网络数据爬取和网页解析的基本能力the Website is the API- 1 python ide 文本ide:IDLE,Sublime Text集成ide:Pychar ...
- Python网络爬虫与信息提取笔记
直接复制粘贴笔记发现有问题 文档下载地址//download.csdn.net/download/hide_on_rush/12266493 掌握定向网络数据爬取和网页解析的基本能力常用的 Pytho ...
- 1 python大数据挖掘系列之基础知识入门
preface Python在大数据行业非常火爆近两年,as a pythonic,所以也得涉足下大数据分析,下面就聊聊它们. Python数据分析与挖掘技术概述 所谓数据分析,即对已知的数据进行分析 ...
- 转:Beautiful Soup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
- 【bs4】安装beautifulsoup
Debian/Ubuntu,install $ apt-get install python-bs4 easy_install/pip $ easy_install beautifulsoup4 $ ...
- requests和BeautifulSoup
一:Requests库 Requests is an elegant and simple HTTP library for Python, built for human beings. 1.安装 ...
随机推荐
- django_rest framework 接口开发(一)
1 restful 规范(建议) 基于FbV def order(request): if request.method=="GET": return HttpResponse(' ...
- Android笔记(九) Android中的布局——框架布局
框架布局没有任何定位方式,所有的控件都会摆放在布局的左上角. 代码示例: framelayout.xml <?xml version="1.0" encoding=" ...
- 使用jquery和使用框架的区别
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- python 多分类任务中按照类别分层采样
在机器学习多分类任务中有时候需要针对类别进行分层采样,比如说类别不均衡的数据,这时候随机采样会造成训练集.验证集.测试集中不同类别的数据比例不一样,这是会在一定程度上影响分类器的性能的,这时候就需要进 ...
- Javascript基础(1)
1 Javascript介绍 1.1 js是一款运行在客户端的网页编程语言 1.2 组成部分 (1)ECMAScript:ECMAScript不是一门语言,而是一个标准.符合这个标准的比较常见的有:J ...
- Struts2中There is no Action mapped for namespace错误解决方法
1.我的原有配置 jsp表单提交路径 <form class="layui-form" id="form" action="${ctx }/me ...
- Jmeter+Selenium结合使用(完整篇)
selenium登录后的cookie交接给接口结合使用 一.下载webdriver插件(包含谷歌和火狐驱动),安装好之后需重启jmeter 二.在配置元件中添加jp@gc - Chrome Drive ...
- 关于LinkedList for OpenJDK
概述 LinkedList采用底层采用双向链表结构,与ArrayList的数组结构不一样.LinkedList因数据结构不一样,不需要申请连续内存,可以利用碎片内存.元素保存数据内容外还需要 ...
- DOM设置css样式
<!DOCTYPE html> <html> <head lang="en"> <meta charset="UTF-8&quo ...
- JAVA的循环结构进阶
1.什么是二重循环: 一个循环体内又包含另一个完整的循环结构 语法: ...