树和二叉树的存储结构的实现(C/C++实现)
存档:
#include <iostream.h>
#include <stdio.h>
#include <stdlib.h>
#define max 20
typedef char elemtype;
#include "tree.h"
void main()
{
btree t,p;
char x;
int i=,num=;
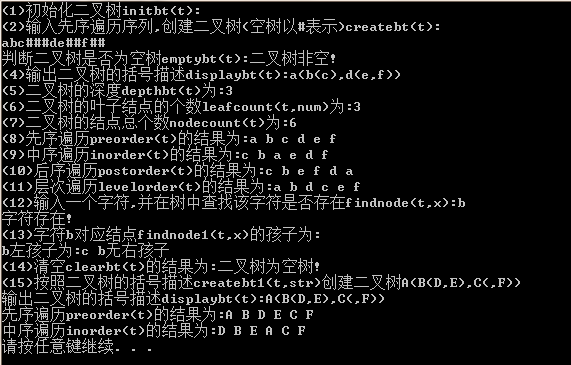
cout<<"(1)初始化二叉树initbt(t):"<<endl;
initbt(t);
cout<<"(2)输入先序遍历序列,创建二叉树(空树以#表示)createbt(t):"<<endl;
createbt(t);
cout<<"判断二叉树是否为空树emptybt(t):";
i=emptybt(t);
if(i==)
cout<<"二叉树为空树!"<<endl;
else
cout<<"二叉树非空!"<<endl;
cout<<"(4)输出二叉树的括号描述displaybt(t):";
displaybt(t);
cout<<endl;
cout<<"(5)二叉树的深度depthbt(t)为:"<<depthbt(t)<<endl;
cout<<"(6)二叉树的叶子结点的个数leafcount(t,num)为:";
leafcount(t,num);
cout<<num<<endl;
cout<<"(7)二叉树的结点总个数nodecount(t)为:"<<nodecount(t)<<endl;
cout<<"(8)先序遍历preorder(t)的结果为:";
preorder(t);
cout<<endl;
cout<<"(9)中序遍历inorder(t)的结果为:";
inorder(t);
cout<<endl;
cout<<"(10)后序遍历postorder(t)的结果为:";
postorder(t);
cout<<endl;
cout<<"(11)层次遍历levelorder(t)的结果为:";
levelorder(t);
cout<<endl;
fflush(stdin);//清空缓存
cout<<"(12)输入一个字符,并在树中查找该字符是否存在findnode(t,x):";
cin>>x;
if(findnode(t,x))
cout<<"字符存在!";
else
cout<<"字符不存在!";
cout<<endl;
cout<<"(13)字符"<<x<<"对应结点findnode1(t,x)的孩子为:"<<endl;
p=findnode1(t,x);
if(p!=NULL)
{
if(p->lchild!=NULL)
cout<<x<<"左孩子为:"<<p->lchild->data<<" ";
else
cout<<x<<"无左孩子"<<" ";
if(p->rchild!=NULL)
cout<<x<<"右孩子为:"<<p->rchild->data<<endl;
else
cout<<x<<"无右孩子"<<endl;
}
else
cout<<x<<"不存在"<<endl;
cout<<"(14)清空clearbt(t)的结果为:";
clearbt(t);
if(emptybt(t))
cout<<"二叉树为空树!"<<endl;
else
cout<<"二叉树非空!"<<endl;
cout<<"(15)按照二叉树的括号描述createbt1(t,str)创建二叉树A(B(D,E),C(,F))";
createbt1(t,"A(B(D,E),C(,F))");
cout<<endl;
cout<<"输出二叉树的括号描述displaybt(t):";
displaybt(t);
cout<<endl;
cout<<"先序遍历preorder(t)的结果为:";
preorder(t);
cout<<endl;
cout<<"中序遍历inorder(t)的结果为:";
inorder(t);
cout<<endl;
clearbt(t);
system("pause");
}
struct node
{
elemtype data;//数据元素
struct node *lchild;//指向左孩子
struct node *rchild;//指向右孩子
};
typedef struct node btnode;//定义结构体的别名btnode
typedef struct node *btree;//定义结构体指针的别名btree
void initbt(btree &t)//初始化函数,构造一棵空树
{
t=NULL;
}
void createbt(btree &t)//先序遍历序列创建二叉树
{
elemtype ch;
cin>>ch;
if(ch=='#')
t=NULL;//#表示空树,递归终止
else
{
t=new btnode;//创建新结点
if(t==NULL)//如果创建结点失败,就退出
exit(-);
t->data=ch;//生成根结点
createbt(t->lchild);//构造左子树
createbt(t->rchild);//构造右子树
}
}
int emptybt(btree t)//判断树是否为空树
{
if(t==NULL)
return ;//空树返回1
else
return ;//非空树返回0
}
int depthbt(btree t)//求二叉树t的深度
{
if(t==NULL)
return ;//空树深度为0
else
{
int depthl=depthbt(t->lchild);//求左子树的高度为depthl
int depthr=depthbt(t->rchild);//求右子树的高度为depthr
return +(depthl>depthr?depthl:depthr);//子树深度最大的+1
}
}
int findnode(btree t,elemtype x)//仿照先序遍历,查找data域为x的结点是否存在
{
int i;
if(t==NULL)
return ;//t为空树,无结点,不存在x,返回0
else if(t->data==x)//t结点恰好是x对应结点,返回1
return ;
else
{
i=findnode(t->lchild,x);//在左子树中去查找x
if(i!=)//如果找到了就返回
return i;
else
return findnode(t->rchild,x);//没找到就去右子树中查找x
}
}
btree findnode1(btree t,elemtype x)//仿照先序遍历,查找data域为x的结点,返回结点指针
{
btree p;
if(t==NULL)
return NULL;//t为空树,不存在x,返回NULL
else if(t->data==x)//t结点恰好是x对应结点,返回t
return t;
else
{
p=findnode1(t->lchild,x);//在左子树中去查找x
if(p!=NULL)//如果找到了就返回
return p;
else
return findnode1(t->rchild,x);//没找到就去右子树中查找x
}
}
void preorder(btree t)//先序遍历的递归算法
{
if(t!=NULL)
{
cout<<t->data<<' ';//访问根结点
preorder(t->lchild);//递归访问左子树
preorder(t->rchild);//递归访问右子树
}
}
void inorder(btree t)//中序遍历的递归算法
{
if(t!=NULL)
{
inorder(t->lchild);//递归访问左子树
cout<<t->data<<' ';//访问根结点
inorder(t->rchild);//递归访问右子树
}
}
void postorder(btree t)//后序遍历的递归算法
{
if(t!=NULL)
{
postorder(t->lchild);//递归访问左子树
postorder(t->rchild);//递归访问右子树
cout<<t->data<<' ';//访问根结点
}
}
void clearbt(btree &t)//仿照后序遍历的递归算法
{
if(t!=NULL)
{
clearbt(t->lchild);//先清空左子树
clearbt(t->rchild);//后清空右子树
delete t;//删除根结点
t=NULL;
}
}
void levelorder(btree t)//借助循环队列的原理,实现层次遍历
{
btree queue[max];//定义循环队列
int front,rear;//定义队首和队尾指针
front=rear=;//置队列为空队列
if(t!=NULL)
cout<<t->data<<' ';//先访问再入队列
queue[rear]=t;
rear++;//结点指针入队列
while(rear!=front)//队列不为空,继续循环
{
t=queue[front];//队头出队列
front=(front+)%max;
if(t->lchild!=NULL)//输出左孩子,并入队列
{
cout<<t->lchild->data<<' ';
queue[rear]=t->lchild;
rear=(rear+)%max;
}
if(t->rchild!=NULL)//输出右孩子,并入队列
{
cout<<t->rchild->data<<' ';
queue[rear]=t->rchild;
rear=(rear+)%max;
}
}
}
int nodecount(btree t)//求二叉树t的结点个数
{
int num1,num2;
if(t==NULL)
return ;//空树结点个数为0
else
{
num1=nodecount(t->lchild);//左子树结点个数
num2=nodecount(t->rchild);//右子树结点个数
return (num1+num2+);//左子树+右子树+1
}
}
void leafcount(btree t,int &count)//求二叉树t的叶子结点的个数
{
if(t!=NULL)
{
if(t->lchild==NULL&&t->rchild==NULL)
count++;//叶子结点计算
leafcount(t->lchild,count);//左子树叶子个数
leafcount(t->rchild,count);//右子树叶子个数
}
}
void displaybt(btree t)//以广义表法输出二叉树
{
if(t!=NULL)
{
cout<<t->data;
if(t->lchild!=NULL||t->rchild!=NULL)
{
cout<<'(';
displaybt(t->lchild);
if(t->rchild!=NULL)
cout<<',';
displaybt(t->rchild);
cout<<')';
}
}
}
void createbt1(btree &t,char *str)//由广义表str串创建二叉链
{
btnode *st[max];
btnode *p=NULL;
int top=-,k,j=;
char ch;
t=NULL;//建立的二叉树初始化为空
ch=str[j];
while(ch!='\0')//str未扫描完时循环
{
switch(ch)
{
case '(':top++;st[top]=p;k=;break;//为左结点
case ')':top--;break;
case ',':k=;break;//为右结点
default:p=new btnode;
p->data=ch;
p->lchild=p->rchild=NULL;
if(t==NULL)//p指向二叉树的根结点
t=p;
else//已建立二叉树根结点
{
switch(k)
{
case :st[top]->lchild=p;break;
case :st[top]->rchild=p;break;
}
}
}
j++;
ch=str[j];
}
}
运行结果如下:
树和二叉树的存储结构的实现(C/C++实现)的更多相关文章
- Java数据结构——树的三种存储结构
(转自http://blog.csdn.net/x1247600186/article/details/24670775) 说到存储结构,我们就会想到常用的两种存储方式:顺序存储和链式存储两种. 先来 ...
- [置顶] ※数据结构※→☆非线性结构(tree)☆============树结点 链式存储结构(tree node list)(十四)
结点: 包括一个数据元素及若干个指向其它子树的分支:例如,A,B,C,D等. 在数据结构的图形表示中,对于数据集合中的每一个数据元素用中间标有元素值的方框表示,一般称之为数据结点,简称结点. 在C语言 ...
- 树和二叉树->存储结构
文字描述 1 二叉树的顺序存储 用一组地址连续的存储单元自上而下,自左至右存储完全二叉树上的结点元素. 这种顺序存储只适用于完全二叉树.因为,在最坏情况下,一个深度为k且只有k个结点的单支树却需要长度 ...
- 树和二叉树->相互转化
文字描述 由上篇关于树和二叉树的存储结构知,树和二叉树都可以采用二叉链表作为存储结构.也就是说,给定一颗树,可以找到惟一的一颗二叉树与之对应,从物理结构来看,它们的二叉链表是相同的,只是解释不同而已. ...
- C#数据结构-二叉树-链式存储结构
对比上一篇文章"顺序存储二叉树",链式存储二叉树的优点是节省空间. 二叉树的性质: 1.在二叉树的第i层上至多有2i-1个节点(i>=1). 2.深度为k的二叉树至多有2k- ...
- 数据结构与算法(C/C++版)【树与二叉树】
第六章<树与二叉树> 树结构是一种非线性存储结构,存储的是具有"一对多"关系的数据元素的集合. 结点: A.B.C等,结点不仅包含数据元素,而且包含指向子树的分支.例如 ...
- K:树、二叉树与森林之间的转换及其相关代码实现
相关介绍: 二叉树是树的一种特殊形态,在二叉树中一个节点至多有左.右两个子节点,而在树中一个节点可以包含任意数目的子节点,对于森林,其是多棵树所组成的一个整体,树与树之间彼此相互独立,互不干扰,但其 ...
- ****** 二 ******、软设笔记【数据结构】-KMP算法、树、二叉树
五.KMP算法: *KMP算法是一种改进的字符串匹配算法. *KMP算法的关键是利用匹配失败后的信息,尽量减少模式串与主串的匹配次数以达到快速匹配的目的.具体实现就是实现一个next()函 ...
- 树和二叉树->线索二叉树
文字描述 从二叉树的遍历可知,遍历二叉树的输出结果可看成一个线性队列,使得每个结点(除第一个和最后一个外)在这个线形队列中有且仅有一个前驱和一个后继.但是当采用二叉链表作为二叉树的存储结构时,只能得到 ...
随机推荐
- 【转】Android开发之数据库SQL
android中的应用开发很难避免不去使用数据库,这次就和大家聊聊android中的数据库操作. 一.android内的数据库的基础知识介绍 1.用了什么数据库 android中采用的数据库是SQLi ...
- 【java】io流之字符输出流:java.io.Writer类及子类的子类java.io.FileWriter
package 文件操作; import java.io.File; import java.io.FileWriter; import java.io.IOException; import jav ...
- 转:iOS开发之多种Cell高度自适应实现方案的UI流畅度分析
本篇博客的主题是关于UI操作流畅度优化的一篇博客,我们以TableView中填充多个根据内容自适应高度的Cell来作为本篇博客的使用场景.当然Cell高度的自适应网上的解决方案是铺天盖地呢,今天我们的 ...
- Panel控件的使用
我们对控件进行分组的原因不外乎三个: 1.为了获得清晰的用户界面而将相关的窗体元素进行可视化分组. 2.编程分组,如对单选按钮进行分组. 3.为了在设计时将多个控件作为一个单元来移动. 在vb.net ...
- Linux(CentOS6.5_X86.64)编译libjpeg出现“checking host system type... Invalid configuration `x86_64-unknown-linux-gnu': machine `x86_64-unknown' not recognized”的解决
本文地址http://comexchan.cnblogs.com/,作者Comex Chan,尊重知识产权,转载请注明出处,谢谢! 今天在编译libjpeg 的时候,遇到下面的报错: checki ...
- 联想笔记本电脑 Z500除尘过程
首先说明联想z500真的是特别难拆,主要是C面的键盘如果没有垫片的话很难拆下,建议准备好垫片再进行. 第一步 首先拆掉背面的五个螺丝钉,然后打开四个垫子注意方向,把隐藏的另外四个螺丝拆掉. 第二步 把 ...
- js把通过图片路径生成base64
主要思想: 使用canvas.toDataURL()方法将图片的绝对路径转换为base64编码. 一.图片在本地服务器: var imgSrc = "img/1.jpg";//本地 ...
- glimmer 3.02安装小记
wget http://www.cbcb.umd.edu/software/glimmer/glimmer302.tar.gz tar xzfglimmer302.tar.gz cd glimmer3 ...
- vue实现登录后跳转到之前的页面
在开发中我们经常遇到这样的需求,需要用户直接点击一个链接进入到一个页面,用户点击后链接后会触发401拦截返回登录界面,登录后又跳转到链接的页面而不是首页,这种问题该如何去做呢? 先说一下我们需要用到的 ...
- linux系统编程:自己动手写一个who命令
who命令的作用用于显示当前有哪些用户登录到系统. 这个命令执行的原理是读取了系统上utmp文件中记录的所有登录信息,直接显示出来的 utmp文件在哪里呢? man who的时候,在手册下面有这么一段 ...