hadoop-2.6.0源码编译问题汇总
在上一篇文章中,介绍了hadoop-2.6.0源码编译的一般流程,因个人计算机环境的不同,
编译过程中难免会出现一些错误,下面是我编译过程中遇到的错误。
列举出来并附上我解决此错误的方法,希望对大家有所帮助。
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
问题1:
Detected JDK Version: 1.8.0_ is not in the allowed range [1.7.,1.7.}
原因:我当时的执行mvn package 操作时,我安装的jdk版本是1.8.0_144,从问题描述就可以看出,应该使用jdk1.7.0-----jdk1.7.1000这个范围。
解决:更改ldk版本。这里很简单,就不在列举更换步骤。
问题2:
[ERROR] Failed to execute goal org.apache.hadoop:hadoop-maven-plugins:2.6.-cdh5.12.0:protoc (compile-protoc) on project hadoop-common: org.apache.maven.plugin.MojoExecutionException: 'protoc --version' did not return a version -> [Help ]
原因:根据错误提示,可以看出编译过程中缺少protoc
解决:百度protoc ,下载安装protobuf-2.5.0.tar.gz
问题3:
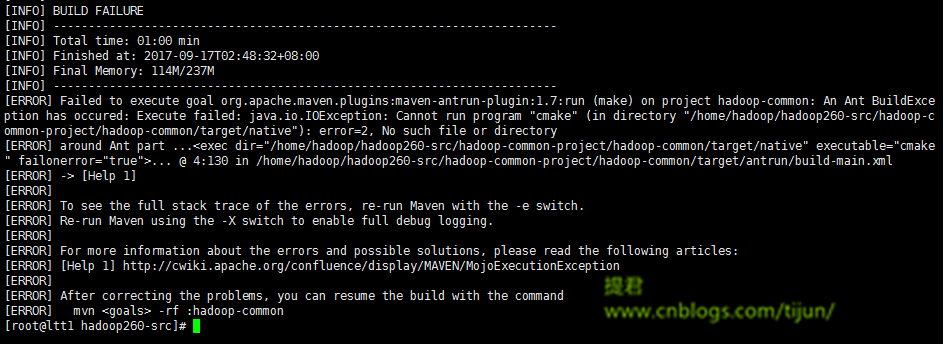
原因:执行这个动作失败。不能运行cmake
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
解决:安装cmake
yum install cmake
问题4:
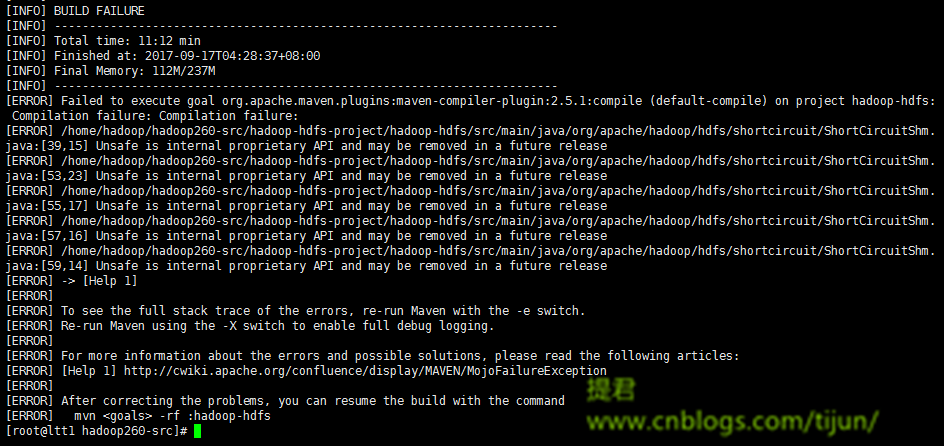
原因:这个错好奇怪,大概意思就是内部专用的API,以后可能会被在源码中移除,不安全,啥啥啥的,源码问题管我何事啊,还影响我编译。
解决:既然是maven编译,还是maven-compiler-plugin,在maven的settings.xml中添加配置
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<compilerArgument>-XDignore.symbol.file</compilerArgument>
</configuration>
</plugin>
问题5:

原因:看错误提示,应该是内存溢出的错误。
解决:在系统环境变量/etc/profile里面添加。添加完后一定记得source一下
export MAVEN_OPTS="-Xmx512m -XX:MaxPermSize=128m"
最后一个不算问题的问题,算是个注意点吧:
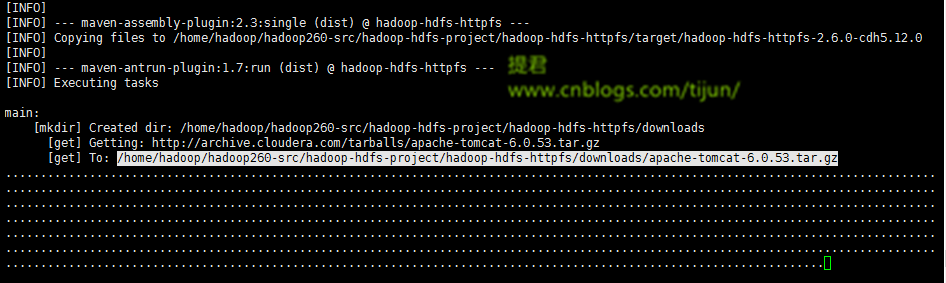
图示,一直在get tomcat ,点点点的没完,这是说明在联网下载这个tar包,从网上**cloudera.com**这个网址,下载到源码里面一个downloads目录下,
如果网站访问不到,无法连接到上述网址
hadoop-2.6.0源码编译问题汇总的更多相关文章
- hadoop-1.2.0源码编译
以下为在CentOS-6.4下hadoop-1.2.0源码编译步骤. 1. 安装并且配置ant 下载ant,将ant目录下的bin文件夹加入到PATH变量中. 2. 安装git,安装autoconf, ...
- Spark1.0.0 源码编译和部署包生成
问题导读:1.如何对Spark1.0.0源码编译?2.如何生成Spark1.0的部署包?3.如何获取包资源? Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对 ...
- ambari 2.5.0源码编译安装
参考:https://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/index.html Ambari 是什么 Ambar ...
- 使用Maven将Hadoop2.2.0源码编译成Eclipse项目
编译环境: OS:RHEL 6.3 x64 Maven:3.2.1 Eclipse:Juno SR2 Linux x64 libprotoc:2.5.0 JDK:1.7.0_51 x64 步骤: 1. ...
- hadoop-2.0.0-mr1-cdh4.2.0源码编译总结
准备编译hadoop-2.0.0-mr1-cdh4.2.0的同学们要谨慎了.首先看一下这篇文章: Hadoop作业提交多种方案 http://www.blogjava.net/dragonHadoop ...
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- Ubantu16.04进行Android 8.0源码编译
参考这篇博客 经过测试,8.0源码下载及编译之后,占用100多G的硬盘空间,尽量给ubantu系统多留一些硬盘空间,如果后续需要在编译好的源码上进行开发,需要预留更多的控件,为了防止后续出现文件权限问 ...
- jmeter4.0 源码编译 二次开发
准备: 1.jmeter4.0源码 - apache-jmeter-4.0_src.zip 2.IDE Eclipse - Oxygen.3 Release (4.7.3) 3.JDK - 1.8.0 ...
随机推荐
- 设计模式,Let's Go! (上)
* { color: #3e3e3e } body { font-family: "Helvetica Neue", Helvetica, "Hiragino Sans ...
- Opentk教程系列-1绘制一个三角形
本系列教程翻译自Neo Kabuto's Blog.已经取得作者授权. 本文原文地址http://neokabuto.blogspot.com/2013/02/opentk-tutorial-1-op ...
- 《NoSQL精粹》读书笔记
NoSQL数据库数据模型的一般分类: 1. 键值数据模型 2. 文档数据模型 3. 列族数据模型 4. 图数据模型 常见NoSQL数据库: Redis, Cassandra, MongoDB, Neo ...
- Java面向对象的理解
Java是一门面向对象的编程语言(Object Oriented Programming,OOP), 这个句话是每个学习Java的程序员应该先深刻理解的一句话. 我们之所以将自自然界分解,组织成各种概 ...
- Composer简介及使用实例
1.PHP-FIG 官网:http://www.php-fig.org/ php编码规范: 本文档是PHP互操作性框架制定小组(PHP-FIG :PHP Framework Interoperabil ...
- AndroidTv Home界面实现原理(一)——Leanback 库的使用
接下去应该是梳理一下 Android Tv 主界面实现原理及解析的一个系列博客了,大体上的安排是先介绍 Google 官方提供的 Leanback 库的使用,如何使用该库来实现简单的 Home 界面, ...
- ajax和json
1.$ ajax({ url:"", data:{username:"admin"},//发送时携带的参数 type:"post/get", ...
- python appium 操作app
下面是一些Python脚本中操作app的用法: 检查app安装情况(返回true/false), driver.is_app_installed(package_name) 安装app driver. ...
- matlab-常用函数(1)
rng('shuffle'): matlab help文档中的解释 rng('shuffle'): seeds the random number generator based on the cur ...
- 关于用VMware克隆linux系统后,无法联网找不到eth0网卡的问题
当使用克隆后的虚拟机时发现系统中的网卡eth0没有了,使用ifconfig -a会发现只有eth1.因为系统是克隆过来的,原有的eth0以及ip地址都是原先网卡的,VMware发现已经被占用,就会创建 ...