hadoop-2.6.0源码编译问题汇总
在上一篇文章中,介绍了hadoop-2.6.0源码编译的一般流程,因个人计算机环境的不同,
编译过程中难免会出现一些错误,下面是我编译过程中遇到的错误。
列举出来并附上我解决此错误的方法,希望对大家有所帮助。
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
问题1:
Detected JDK Version: 1.8.0_ is not in the allowed range [1.7.,1.7.}
原因:我当时的执行mvn package 操作时,我安装的jdk版本是1.8.0_144,从问题描述就可以看出,应该使用jdk1.7.0-----jdk1.7.1000这个范围。
解决:更改ldk版本。这里很简单,就不在列举更换步骤。
问题2:
[ERROR] Failed to execute goal org.apache.hadoop:hadoop-maven-plugins:2.6.-cdh5.12.0:protoc (compile-protoc) on project hadoop-common: org.apache.maven.plugin.MojoExecutionException: 'protoc --version' did not return a version -> [Help ]
原因:根据错误提示,可以看出编译过程中缺少protoc
解决:百度protoc ,下载安装protobuf-2.5.0.tar.gz
问题3:
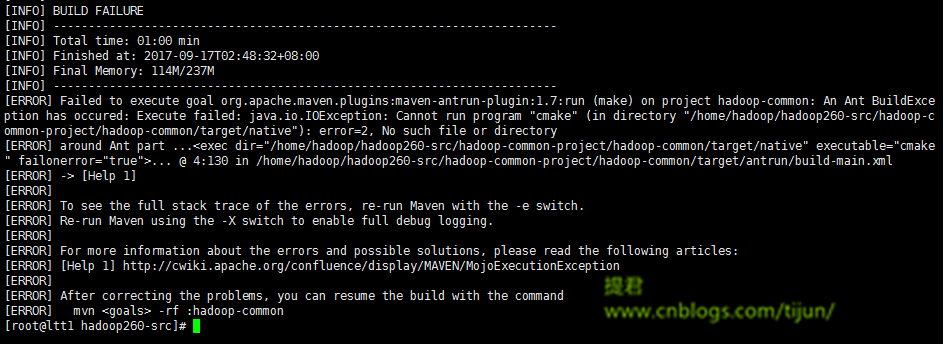
原因:执行这个动作失败。不能运行cmake
>>提君博客原创 http://www.cnblogs.com/tijun/ <<
解决:安装cmake
yum install cmake
问题4:
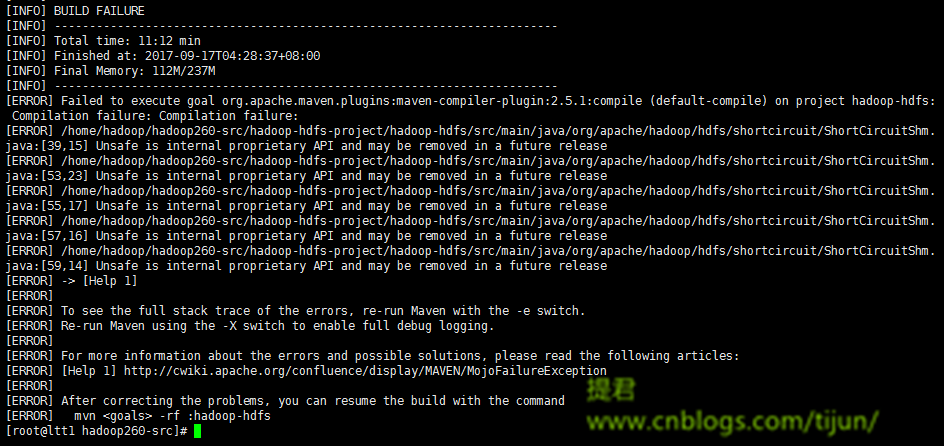
原因:这个错好奇怪,大概意思就是内部专用的API,以后可能会被在源码中移除,不安全,啥啥啥的,源码问题管我何事啊,还影响我编译。
解决:既然是maven编译,还是maven-compiler-plugin,在maven的settings.xml中添加配置
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<compilerArgument>-XDignore.symbol.file</compilerArgument>
</configuration>
</plugin>
问题5:

原因:看错误提示,应该是内存溢出的错误。
解决:在系统环境变量/etc/profile里面添加。添加完后一定记得source一下
export MAVEN_OPTS="-Xmx512m -XX:MaxPermSize=128m"
最后一个不算问题的问题,算是个注意点吧:
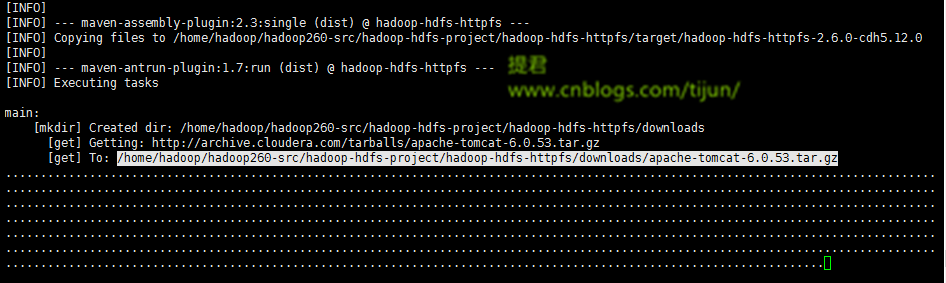
图示,一直在get tomcat ,点点点的没完,这是说明在联网下载这个tar包,从网上**cloudera.com**这个网址,下载到源码里面一个downloads目录下,
如果网站访问不到,无法连接到上述网址
hadoop-2.6.0源码编译问题汇总的更多相关文章
- hadoop-1.2.0源码编译
以下为在CentOS-6.4下hadoop-1.2.0源码编译步骤. 1. 安装并且配置ant 下载ant,将ant目录下的bin文件夹加入到PATH变量中. 2. 安装git,安装autoconf, ...
- Spark1.0.0 源码编译和部署包生成
问题导读:1.如何对Spark1.0.0源码编译?2.如何生成Spark1.0的部署包?3.如何获取包资源? Spark1.0.0的源码编译和部署包生成,其本质只有两种:Maven和SBT,只不过针对 ...
- ambari 2.5.0源码编译安装
参考:https://www.ibm.com/developerworks/cn/opensource/os-cn-bigdata-ambari/index.html Ambari 是什么 Ambar ...
- 使用Maven将Hadoop2.2.0源码编译成Eclipse项目
编译环境: OS:RHEL 6.3 x64 Maven:3.2.1 Eclipse:Juno SR2 Linux x64 libprotoc:2.5.0 JDK:1.7.0_51 x64 步骤: 1. ...
- hadoop-2.0.0-mr1-cdh4.2.0源码编译总结
准备编译hadoop-2.0.0-mr1-cdh4.2.0的同学们要谨慎了.首先看一下这篇文章: Hadoop作业提交多种方案 http://www.blogjava.net/dragonHadoop ...
- 基于cdh5.10.x hadoop版本的apache源码编译安装spark
参考文档:http://spark.apache.org/docs/1.6.0/building-spark.html spark安装需要选择源码编译方式进行安装部署,cdh5.10.0提供默认的二进 ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- Ubantu16.04进行Android 8.0源码编译
参考这篇博客 经过测试,8.0源码下载及编译之后,占用100多G的硬盘空间,尽量给ubantu系统多留一些硬盘空间,如果后续需要在编译好的源码上进行开发,需要预留更多的控件,为了防止后续出现文件权限问 ...
- jmeter4.0 源码编译 二次开发
准备: 1.jmeter4.0源码 - apache-jmeter-4.0_src.zip 2.IDE Eclipse - Oxygen.3 Release (4.7.3) 3.JDK - 1.8.0 ...
随机推荐
- Python爬虫从入门到放弃(二十四)之 Scrapy登录知乎
因为现在很多网站为了限制爬虫,设置了为只有登录才能看更多的内容,不登录只能看到部分内容,这也是一种反爬虫的手段,所以这个文章通过模拟登录知乎来作为例子,演示如何通过scrapy登录知乎 在通过scra ...
- Big Endian与Litter Endian
Big Endian是大端,Litter Endian是小端,意思很明了,但是很难记住谁是谁.每次涉及到这个概念的时候,我都会GOOGLE一下,浪费精力. 怎样才能永远记住他们呢?网上搜索了一下,有很 ...
- jQuery选择器使用习惯
http://www.cnblogs.com/fredlau/archive/2009/03/19/1416327.html
- RQNOJ 201 奥运大包围:LIS + 拼链成环
题目链接:https://www.rqnoj.cn/problem/201 题意: 开始时n(n<=1000)个人手拉手围成一个圈. 后来这些人中的一些按顺序向里面出圈形成一个新圈.从而使原圈形 ...
- Servlet3.1上传图片示例
一.前端JSP页面 <%@page pageEncoding="UTF-8"%><!DOCTYPE html><html><head> ...
- python的计数引用分析(一)
python的垃圾回收采用的是引用计数机制为主和分代回收机制为辅的结合机制,当对象的引用计数变为0时,对象将被销毁,除了解释器默认创建的对象外.(默认对象的引用计数永远不会变成0) 所有的计数引用+1 ...
- win10的power shell可以学习少部分linux命令_功能与cmd类似
更新帮助文件:
- virtualbox下正确虚拟机修改设备名称
在学习大数据管理过程中,想要修改虚拟机的设备名称(因为名称太长),所以就直接在右上角的设置中找到详细设置,直接修改设备名称,结果启动Hadoop失败!!!! 后来参考网上问题解决弄好了,现在给出修改设 ...
- js事件汇总
常用事件: 1.鼠标事件:onClick,onDblClick,onMouseDown,onMouseUp,onMouseOut,onMouseOver ·onClick:单击页面元素时发生,onDb ...
- 学习Java第一天,大致了解
第一章: java核心 1 了解 java的产生背景 2 了解java的体系结构和组成 3 了解java程序的编写 编译 运行 4 掌握java的 api文档的使用 5 了解 jdk的组成 1. ja ...