Hadoop hdfs完全分布式搭建教程
1、安装环境
①、四台Linux CentOS6.7 系统
hostname ipaddress subnet mask geteway
1、 master 192.168.146.200 255.255.255.0 192.168.146.2
2、 slave1 192.168.146.201 255.255.255.0 192.168.146.2
3、 slave2 192.168.146.202 255.255.255.0 192.168.146.2
4、 slave3 192.168.146.203 255.255.255.0 192.168.146.2
其中 master 机器是 NameNode;
slave1 机器是 SecondaryNameNode
slave1,slave2,slave3 是三台 DataNode
②、hadoop 2.7 安装包
百度云下载链接:http://pan.baidu.com/s/1gfaKpA7密码:3cl7
③、三台机器上建立一个相同的用户 hadoop
2、安装 JDK
教程:http://www.cnblogs.com/ysocean/p/6952166.html
3、配置SSH 无密码登录
教程:http://www.cnblogs.com/ysocean/p/6959776.html
我们以 master 机器来进行如下配置:
4、解压 hadoop-2.7.3.tar.gz
①、将下载的 hadoop-2.7.3.tar.gz 复制到 /home/hadoop 目录下(可以利用工具 WinSCP)
②、解压,进入/home/hadoop 目录下,输入下面命令
tar -zxvf hadoop-2.7.3.tar.gz
③、给 hadoop-2.7.3文件夹重命名,以便后面引用
mv hadoop-2.7.3 hadoop2.7
④、删掉压缩文件 hadoop-2.7.3.tar.gz,并在/home/hadoop 目录下新建文件夹tmp
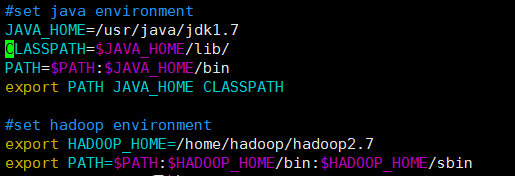
⑤、配置 hadoop 环境变量(这里我Java 和 hadoop 环境变量一起配置了)
使用 root 用户登录。输入
vi /etc/profile
5、配置 hadoop 文件中相应的文件
需要配置的文件如下,hadoop-env.sh,core-site.xml,hdfs-site.xml,slaves,所有的文件配置均位于hadoop2.7.1/etc/hadoop下面,具体需要的配置如下:
5.1 配置/home/hadoop/hadoop2.7/etc/hadoop目录下的core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.146.200:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/tmp</value>
</property> </configuration>
注意:hadoop.tmp.dir是hadoop 文件系统依赖的配置文件。 默认是在 /tmp 目录下的,而这个目录下的文件,在Linux系统中,重启之后,很多都会被清空。所以我们要手动指定这写文件的保存目录。
这个目录路径要么不存在,hadoop启动的时候会自动帮我们创建;要么是一个空目录,不然在启动的时候会报错。
5.2配置/home/hadoop/hadoop-2.7/etc/hadoop目录下的hdfs-site.xml

<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.146.201:50090</value>
</property>
</configuration>
注意:dfs.replication 是配置文件保存的副本数;dfs.namenode.secondary.http-address 是指定 secondary 的节点。
5.3配置/home/hadoop/hadoop-2.7/etc/hadoop目录下hadoop-env.sh 的JAVA_HOME

设置 JAVA_HOME 为自己在系统中安装的 JDK 目录

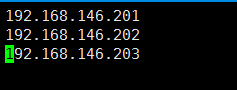
5.4配置/home/hadoop/hadoop-2.7/etc/hadoop目录下的slaves,删除默认的localhost,增加3个从节点

5.5、指定 SecondaryNameNode 节点
在 /home/hadoop hadoop-2.7/etc/hadoop 目录下手动创建一个 masters 文件
vi masters
打开文件后,输入 SecondaryNameNode 节点的主机名或者 IP 地址

6、将配置好的 hadoop 文件上传给其它三个节点
scp -r /home/hadoop 192.168.146.201:/home/
scp -r /home/hadoop 192.168.146.202:/home/
scp -r /home/hadoop 192.168.146.203:/home/
7、启动 hadoop
在master服务器启动hadoop,从节点会自动启动,进入/home/hadoop/hadoop-2.7目录
(1)初始化,输入命令,bin/hdfs namenode -format

(2)启动hdfs 命令:sbin/start-dfs.sh

(3)停止命令,sbin/stop-hdfs.sh
(4)输入命令,jps,可以看到相关信息
8、访问界面
①、关闭防火墙
service iptables stop
chkconfig iptables off
②、访问 NameNode 节点信息:http://192.168.146.200:50070
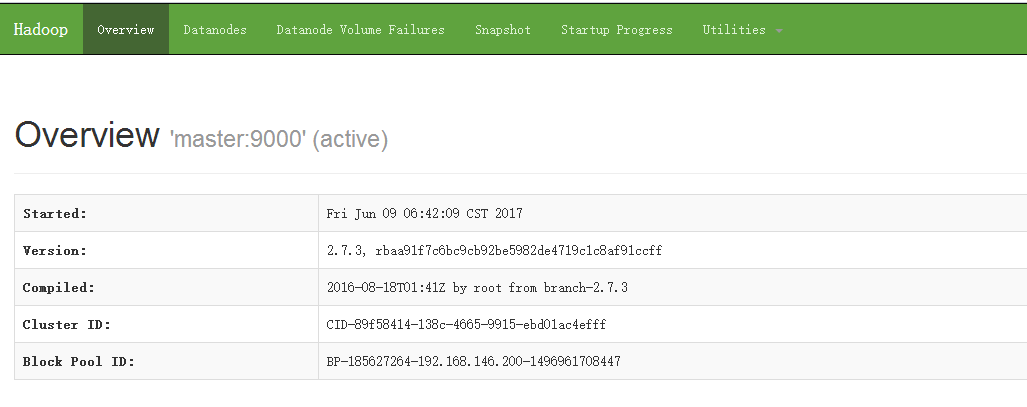
点击DataNodes 查看 DataNode 节点

③、访问 SecondaryNameNode 节点信息,就是我们在hdfs-site.xml 中配置的路径 http://192.168.146.201:50090

Hadoop hdfs完全分布式搭建教程的更多相关文章
- hadoop HDFS完全分布式搭建
1.准备阶段 准备好两台虚拟机(安装好hadoop,见:https://www.cnblogs.com/cjq10029/p/12336446.html),计划: IP 主机名 192.168.3.7 ...
- Hadoop的完全分布式搭建
一.准备虚拟机两台 1.将虚拟机进行克隆https://www.cnblogs.com/the-roc/p/12336745.html 2.1将克隆虚拟机的IP修改一下 vi /etc/sysconf ...
- hbase+hadoop+hdfs集群搭建 集成spring
序言 最近公司一个汽车项目想用hbase做存储,然后就有了这篇文字,来,来,来, 带你一起征服hbase,并推荐一本书<hbase权威指南> 这是一本极好的hbase入门书籍,我花了一个晚 ...
- Hadoop单机模式和伪分布式搭建教程CentOS
1. 安装JAVA环境 2. Hadoop下载地址: http://archive.apache.org/dist/hadoop/core/ tar -zxvf hadoop-2.6.0.tar.gz ...
- Hadoop的伪分布式搭建
我们在搭建伪分布式Hadoop环境,需要将一系列的配置文件配置好. 一.配置文件 1. 配置文件hadoop-env.sh export JAVA_HOME=/opt/modules/jdk1.7.0 ...
- 大数据hadoop的伪分布式搭建
1.配置环境变量JDK配置 1.JDK安装 个人喜欢在 vi ~/.bash profile 下配置 export JAVA_HOME=/home/hadoop/app/jdk1.8.0_91ex ...
- HDFS——完全分布式搭建
架构 NN--namenode SNN--secondnamenode DN--datanode hadoop_env.sh中修改JAVA_HOME core-site.xml <propert ...
- Linux单机环境下HDFS伪分布式集群安装操作步骤v1.0
公司平台的分布式文件系统基于Hadoop HDFS技术构建,为开发人员学习及后续项目中Hadoop HDFS相关操作提供技术参考特编写此文档.本文档描述了Linux单机环境下Hadoop HDFS伪分 ...
- 『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现
『实践』VirtualBox 5.1.18+Centos 6.8+hadoop 2.7.3搭建hadoop完全分布式集群及基于HDFS的网盘实现 1.基本设定和软件版本 主机名 ip 对应角色 mas ...
随机推荐
- Xamarin.Android 绑定友盟社会化分享组件
Xamarin.Android 绑定友盟社会化分享组件 最近在开发博客园Android App的时候需要用到友盟社会化分享组件,在github上搜了一下都没有找到最新版本绑定好的项目,就自己动手来绑定 ...
- BogoMIPS与calibrate_delay
在分析Arm+linux启动信息的时候.发现有一个信息竟然耗费了2s的时间,这简直是不能忍受的.这个耗时大鳄是什么东西哪,请看分析信息: [ 0.000000] console [ttyMT0] ...
- DirectFB 之 分段动画
动画动态配置 一套素材的目录结构一般如下: 子目录中的图片名称都是以数字命名,比如,1,2, 3, 4,-- 而配置文件animation.cfg的格式如下: #width height ...
- hdu1269强连通分量入门题
https://vjudge.net/contest/156688#problem 为了训练小希的方向感,Gardon建立了一座大城堡,里面有N个房间(N<=10000)和M条通道(M<= ...
- Ubuntu14.04双网卡主备配置
近日有个需求,交换机有两台,做了堆叠,服务器双网卡,每个分别连到一台交换机上.这样就需要将服务器的网卡做成主备模式,以增加安全性,使得当其中一个交换机不通的时候网卡能够自动切换. 整体配置不难,网上也 ...
- .net使用RabbitMQ
前面的两篇博文算是把RabbitMQ的基础了解了下,今天学习.Net 中RabbitMQ的使用.原本这篇博文是应该上周写的,可在自己使用的过程中出现了一个问题bug:就是在连接服务端时,一直报下面的错 ...
- 【2017-05-05】timer控件、三级联动、帐号激活权限设置
一.Timer控件 Timer实际就是一个线程控件. 属性:Enabled 是否被启用 Interval 多长时间执行一次控件中的代码 事件: Tick 事件中放要执行的代码. ...
- IOS的UIPickerView 和UIDatePicker
1.UIPickerView的常见属性 //数据源(用来告诉UIPickerView有多少列多少行) @property(nonatomic,assign) id<UIPikerViewData ...
- ios模拟器bug
Error: xcode-select: error: tool 'xcodebuild' requires Xcode, but active developer directory '/Libra ...
- fir.im 持续集成技术实践
互联网时代,人人都在追求产品的快速响应.快速迭代和快速验证.不论是创业团队还是大中型企业,都在探索属于自己的敏捷开发.持续交付之道.fir.im 团队也在全面实施敏捷,并推出新持续集成服务 - flo ...