MyBatis_查询缓存01
一、查询缓存
查询缓存的使用,主要是为了提高查询访问速度。将用户对同一数据的重复查询过程简单化,不在每次均从数据库中查询获取结果数据,从而提高访问速度。
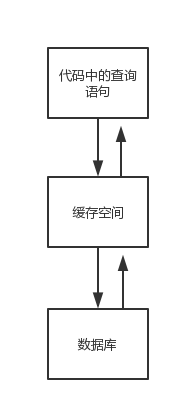
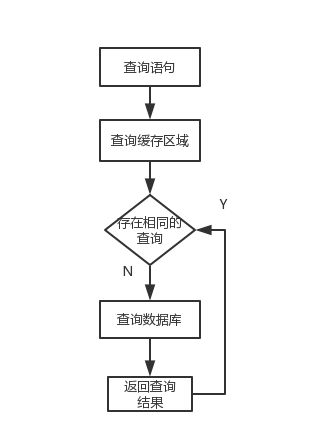
MyBatis的查询缓存机制,根据缓存区的作用域与生命周期,可划分为两种:一级缓存和二级缓存。
MyBatis查询缓存的作用域是根据映射文件mapper的namespace划分的,相同namespace的mapper查询数据存放在同一个缓存区域。不同的namespace下的数据互不干扰。无论是一级缓存还是二级缓存,都是按照namespace进行分别存放的。
但一、二级缓存的不同之处在于,SqlSession一旦关闭,则SQLSession中的数据将不存在,即一级缓存就不存在,而二级缓存的生命周期会与整个应用同步,与SQLSession是否关闭无关。
简单的说,一级缓存是在同一线程(同一SQLSession)间共享数据,而二级缓存是在不同线程间共享数据。
二、一级缓存的证明

三、从缓存中查找数据的依据


MyBatis的查询依据是:Sql的id+SQL语句。
Hibernate的查依据是:查询结果对象的id。
缓存的底层实现是一个Map,Map的value是查询结果。Map的key,即查询依据,使用的ORM架构不同,查询依据就不不同。
ORM:
四、增删改对一级缓存的影响
@Test
public void test03() {
Student student = dao.selectStudentById(197);
System.out.println(student);
//增删改操作都会清空一级缓存
dao.insertStudent(new Student("阿古斯",26,96.5));
Student student1 = dao.selectStudentById(197);
System.out.println(student1);
}
输出:
0 [main] DEBUG com.jmu.dao.IStudentDao.selectStudentById - ==> Preparing: select id,name,age,score from student where id=?
75 [main] DEBUG com.jmu.dao.IStudentDao.selectStudentById - ==> Parameters: 197(Integer)
116 [main] TRACE com.jmu.dao.IStudentDao.selectStudentById - <== Columns: id, name, age, score
116 [main] TRACE com.jmu.dao.IStudentDao.selectStudentById - <== Row: 197, 明明, 19, 87.9
120 [main] DEBUG com.jmu.dao.IStudentDao.selectStudentById - <== Total: 1
Student [id=197, name=明明, score=87.9, age=19]
121 [main] DEBUG com.jmu.dao.IStudentDao.insertStudent - ==> Preparing: insert into student(name,age,score) values(?,?,?)
122 [main] DEBUG com.jmu.dao.IStudentDao.insertStudent - ==> Parameters: 阿古斯(String), 26(Integer), 96.5(Double)
123 [main] DEBUG com.jmu.dao.IStudentDao.insertStudent - <== Updates: 1
124 [main] DEBUG com.jmu.dao.IStudentDao.selectStudentById - ==> Preparing: select id,name,age,score from student where id=?
124 [main] DEBUG com.jmu.dao.IStudentDao.selectStudentById - ==> Parameters: 197(Integer)
124 [main] TRACE com.jmu.dao.IStudentDao.selectStudentById - <== Columns: id, name, age, score
125 [main] TRACE com.jmu.dao.IStudentDao.selectStudentById - <== Row: 197, 明明, 19, 87.9
125 [main] DEBUG com.jmu.dao.IStudentDao.selectStudentById - <== Total: 1
Student [id=197, name=明明, score=87.9, age=19]
结论:增删改操作都会清空一级缓存,无论是否提交
首先,证明二级缓存的存在。
因为SqlSession一旦关闭,一级缓存就不存在,而二级缓存的生命周期会与整个应用同步,与SQLSession是否关闭无关。
sqlSession.close();
开启内置的二级缓存步骤:
- 对实体进行序列化

- 在映射文件中添加<cache/>标签;
缓存命中率:
【DEBUG】 Cache Hit Ratio:0.5
(2)增删改对二级缓存的影响
public void test01() {
sqlSession = MybatisUtils.getSqlSession();
dao = sqlSession.getMapper(IStudentDao.class);
Student student = dao.selectStudentById(197);
System.out.println(student);
sqlSession.close();
sqlSession = MybatisUtils.getSqlSession();
dao = sqlSession.getMapper(IStudentDao.class);
dao.insertStudent(new Student("",0,0));
Student student1 = dao.selectStudentById(197);
System.out.println(student1);
}
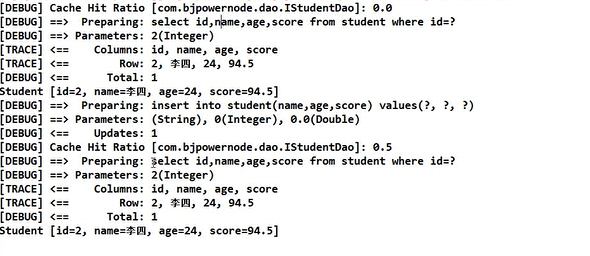
上面的例子说明:
- 增删改同样会清空二级缓存;
- 对于二级缓存的清空,实际上是对所查找key对应的value置为null,而非将<key,value>对,即Entry对象删除
- 从DB中重新进行select查询的条件是:A、缓存中根本不存在这个key;B、缓存中存在改key所对应的Entry对象,但其value为null
(3)二级缓存的配置
- size:二级缓存中可以存放的最多对象个数,默认为1024个。(实际上就是HashMap的长度,可以放多少Entry对象)
- eviction:逐出策略。当二级缓存中的对象达到最大值时,就需要通过逐出策略将缓存中的对象移出缓存。默认为LRU。常用的策略有:FIFO(First in First out)先进先出、LRU(Least Recently Used)未被使用时间最长的。
- flushInterval:刷新缓存的时间间隔,单位毫秒。这里的刷新缓存即清空缓存。一般不指定,即当执行增删改时刷新缓存。
- readOnly:设置缓存中数据是否只读。默认false。
(4)二级缓存的关闭
(1)全局关闭
<settings>
<!-- 关闭二级缓存 -->
<setting name="cacheEnabled" value="false" />
</settings>
(2)局部关闭

(5)二级缓存的使用原则
- 多个namespace不要操作同一张表
- 不要在关联关系表上执行增删改操作(一个namespace一般对同一个表,若表间存在关联关系,也就意味着同一个表可能会出现多个namespace。若其中一个namespace对表进行增删改操作而影响到了其关联表数据,而这个关联表的数据修改之后刷新当前namespace下的二级缓存,而对另一个namespace下的二级缓存数据没有影响)
- 查询多于修改时使用二级缓存
MyBatis_查询缓存01的更多相关文章
- ECMall关于数据查询缓存的问题
刚接触Ecmall的二次开发不久,接到一个任务.很常见的任务,主要是对数据库进行一些操作,其中查询的方法我写成这样: 01 function get_order_data($goods_id) 02 ...
- Mysql查询缓存Query_cache的功用
MySQL的查询缓存并非缓存执行计划,而是查询及其结果集,这就意味着只有相同的查询操作才能命中缓存,因此MySQL的查询缓存命中率很低,另一方面,对于大结果集的查询,其查询结果可以从cache中直接读 ...
- mysql实战优化之九:MySQL查询缓存总结
mysql Query Cache 默认为打开.从某种程度可以提高查询的效果,但是未必是最优的解决方案,如果有的大量的修改和查询时,由于修改造成的cache失效,会给服务器造成很大的开销. mysql ...
- Hibernate中 一 二级缓存及查询缓存(1)
最近趁有空学习了一下Hibernate的缓存,其包括一级缓存,二级缓存和查询缓存(有些是参照网络资源的): 一.一级缓存 一级缓存的生命周期和session的生命周期一致,当前sessioin ...
- Mysql查询缓存碎片、缓存命中率及Nagios监控
Mysql 的优化方案,在互联网上可以查找到非常多资料,今天对Mysql缓存碎片和命中率作了详细了解,个人作了简单整理. 一.Mysql查询缓存碎片和缓存命中率. mysql> SHOW STA ...
- hibernate笔记--缓存机制之 二级缓存(sessionFactory)和查询缓存
二级缓存(sessionFactory): Hibernate的二级缓存由SessionFactory对象管理,是应用级别的缓存.它可以缓存整个应用的持久化对象,所以又称为“SessionFactor ...
- mybatis入门基础(八)-----查询缓存
一.什么是查询缓存 mybatis提供查询缓存,用于减轻数据压力,提高数据库性能. mybaits提供一级缓存,和二级缓存. 1.1. 一级缓存是sqlSession级别的缓存.在操作数据库时需要构造 ...
- mybatis中的查询缓存
一: 查询缓存 Mybatis提供查询缓存,用于减轻数据压力,提高数据库压力. Mybatis提供一级缓存和二级缓存. 在操作数据库时需要构造SqlSession对象,在对象中有一个数据结构(Hash ...
- 11g新特性-查询缓存(1)
众所周知,访问内存比访问硬盘快得多,除非硬盘体系发生革命性的改变.可以说缓存在Oracle里面无处不在,结果集缓存(Result Cache)是Oracle Database 11g新引入的功能,引入 ...
随机推荐
- WPF学习之路一
前段时间一直在学习MVC,工作需要,现在需要180度急转弯,搞WPF,MVVM,只能找资料学习了. WPF中有一个消息机制,就是当前台控件绑定的值改变时,会自动通知到指定的事件来改变VM的值,反之亦然 ...
- 用C#实现DES加密解密解决URL参数明文的问题
啥也不说,直接上代码. 加密解码,封装到一个类,key可以自己修改. using System; using System.Security.Cryptography; using System.Te ...
- .net core 开发短网址平台的思路
最近有个客户要求开发一套短网址网站,小编现在都使用.net core进行网站开发了,以是厘厘思路,想想使用.net core 的中间件应该很容易实现. 1. 构建一个中间件,监测网站的响应状态,代码如 ...
- Windows定时器学习
定时器是一个在特定时间或者规则间隔被激发的内核对象.结合定时器的异步程序调用可以允许回调函数在任何定时器被激发的时候执行. 通过调用CreateWaitableTimer()可以创建一个定时器,此函数 ...
- crontab中使用python无法执行
手动执行可以的,但是在crontab中却无法执行,在网上搜了一圈,给出的结论是将相对路径改成绝对路径. 改了之后解决这个问题. 是不是依赖某些环境变量,linux 里的 cron 只有几个基本的环境变 ...
- python 自动拉起进程脚本
cat /usr/local/ssdb/moniter_ssdb.py #!/usr/bin/env python import os import sys import commands #ssdb ...
- java并发之同步辅助类(Semphore、CountDownLatch、CyclicBarrier、Phaser)
线程同步辅助类,主要学习两点: 1.上述几种同步辅助类的作用以及常用的方法 2.适用场景,如果有适当的场景可以用到,那无疑是最好的 semaphore(seməˌfôr) 含义 信号量就是可以声明多把 ...
- 《java.util.concurrent 包源码阅读》11 线程池系列之ThreadPoolExecutor 第一部分
先来看ThreadPoolExecutor的execute方法,这个方法能体现出一个Task被加入到线程池之后都发生了什么: public void execute(Runnable command) ...
- IDisposeable,Close
一.资源分类 资源分为托管资源和非托管资源. 非托管资源:所有的windows内核对象(句柄)都是非托管资源,如stream,数据库连接,GDI+和COM对象等,这些资源不受CLR管理. 托管资源:由 ...
- jquery 三级关联选择效果
在网页制作中,三级关联选择经常遇到,于是归纳了一个进行参考 代码如下: <!DOCTYPE html> <html lang="en"> <head& ...